随机数

机器大数值数据类型的数值大小上限
数值随机化算法
随机投点法计算 值
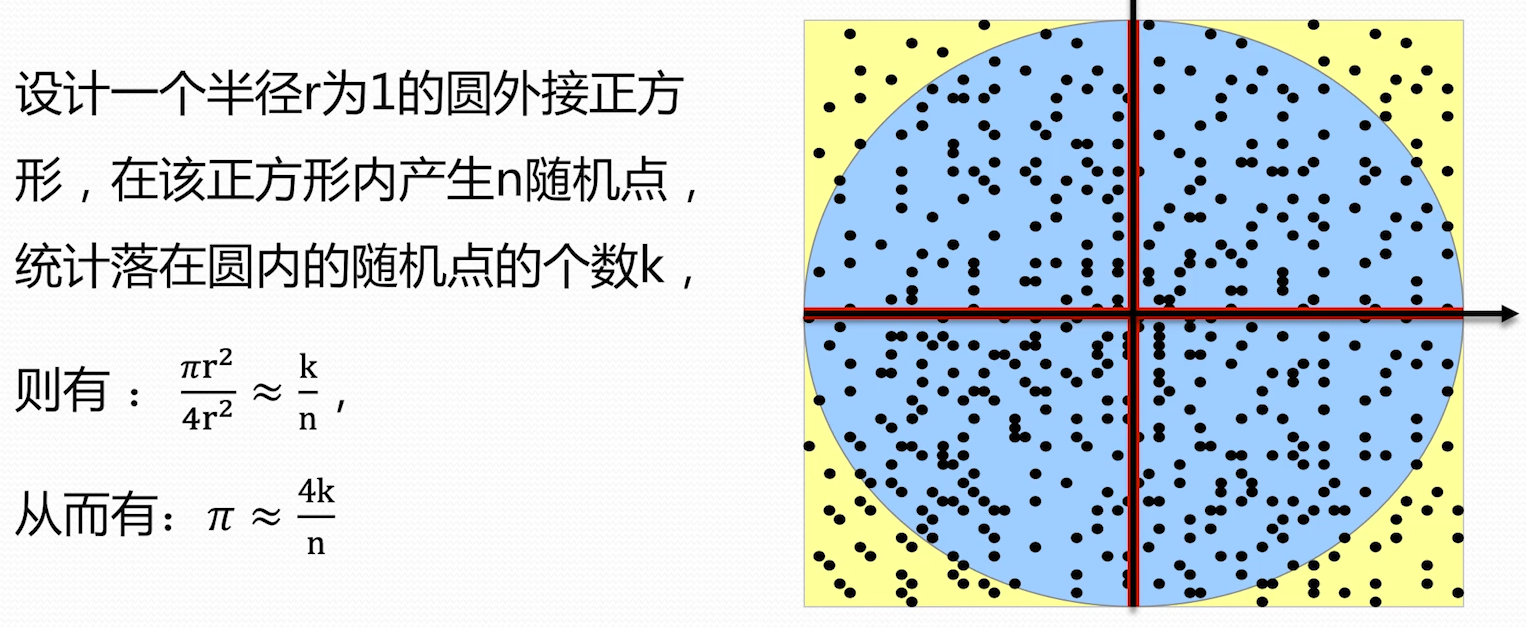
使用随机点的方法估算圆的面积
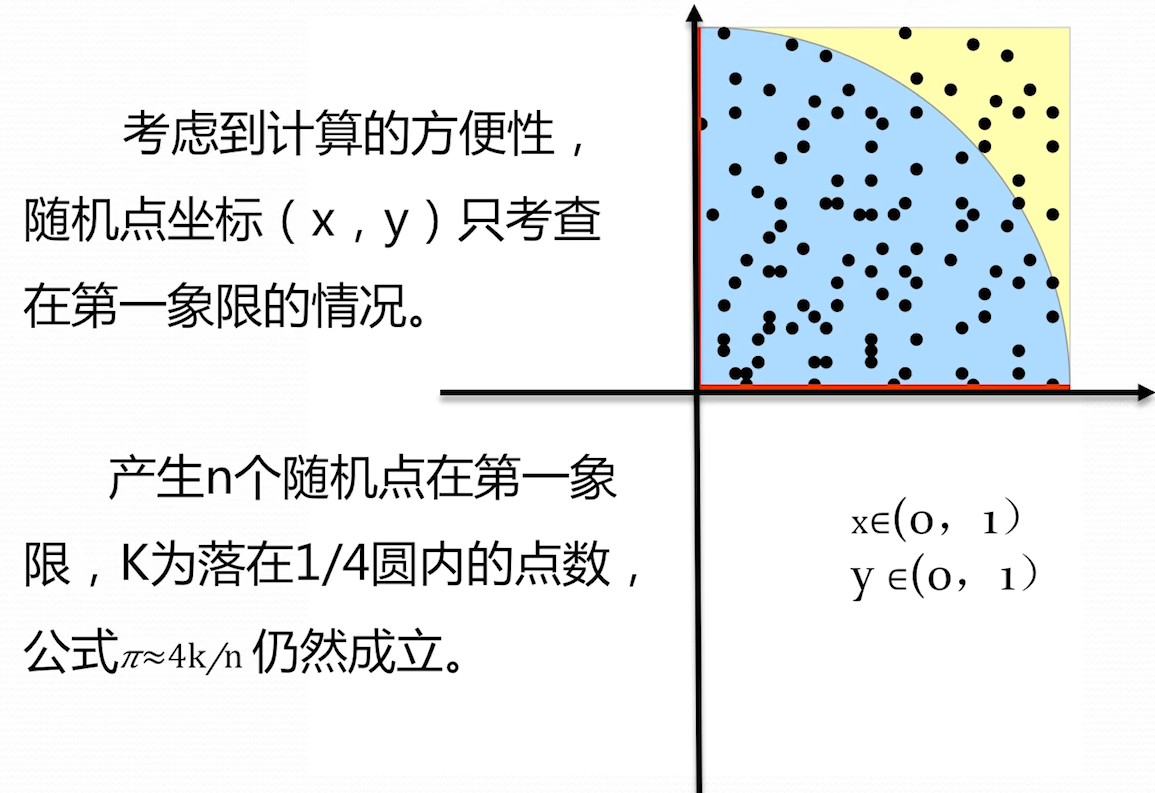
由于图形是对称图形,为了减小计算,只考虑第一想象的情况
算法

For 循环进行投点,要增加面积的精确度,需要增大投点数量n
计算定积分

通过投点计算出积分区域占整个矩形区域的比例,从而计算出积分区域面积
解非线性方程组

就是在求解空间里面随机,直到找到一个误差比较小的 x,作为近似解
舍伍德算法

前半段介绍平均时间复杂度计算;但是有的算法可能存在某些情况时间复杂度远大于平均复杂度的情况,如快排,平均时间复杂度 ,最差 因此舍伍德算法,就是用来尽量避免最差情况的算法
回顾学习过的舍伍德算法
- 线性时间选择算法
- 快速排序算法
这两个算法都是快排分治的方法
当在数据基本有序的情况下,partition () 算法的两个分组严重不平衡,导致这两个算法的时间复杂度都是
改造的方法将 partition 算法改造成 randomizedpartition 算法
当无法改造成舍伍德算法的时候,可借助随机预处理技术 (洗牌算法)

就是随机打乱数组的数据
跳跃表

跳跃表设置了不同级别的指针,更高的级别的指针跨越元素更大; 搜索时先从级别最大的指针开始搜索,逐级确定目标元素所在位置
跳跃表可在 平均时间内支持关于有序集的搜索、插入、删除、等运算
因为指针每高一级,所跨越的元素数量就多一倍,类似二叉树,所以平均时间复杂度
含有 n 个元素的有序链表,改造成一个完全跳跃表,使得每一个 k 级节点含有 k+1 个指针,分别跳过 个中间节点。第 i 个 k 级节点安排在跳跃表的位置 处,。最高级的节点是 级节点
缺点 同完全二叉搜索树类似。它虽然可以有效的支持成员搜索运算,但不适应动态变化的情况。元素的插入和删除运算会破开怀跳跃表原有的平衡状态,影响之后的搜索的效率
如某一个节点插入过量数据,这里全是最低级指针连接,插入的大量数据之间没有更高级指针连接,目标数据在这部分数据中时,查找效率明显下降 应该设立机制让插入的节点也有机会参与更高级的指针连接
舍伍德算法解决 在动态变化中维持跳跃表中附加指针的平衡性:随机化策略
在一个完全跳跃表中,高一级指针节点个数/第一集指针节点个数=1/2
因此,再插入一个元素时,应以概率 引入一个 k 级指针节点
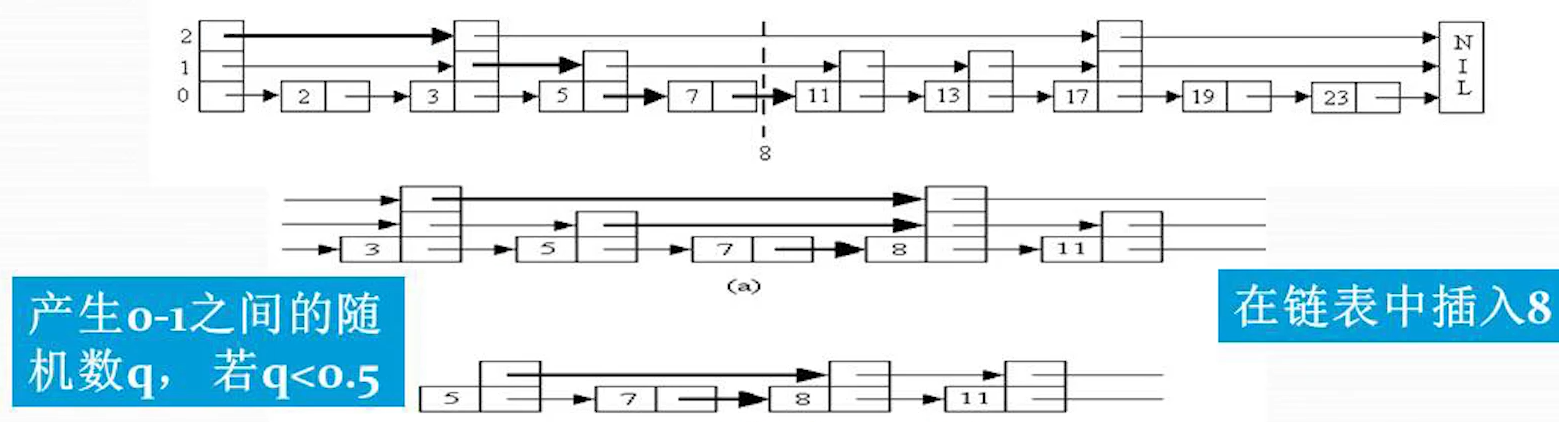
上图在 7,11 之间插入 8 节点;使用随机数 q 判断是否生成二级指针连接,使用 判断是否生成三级指针连接
舍伍德算法-跳跃表插入元素步骤 为了维持跳跃表平衡性,确定一实数 (通常取 ) 目的:含有i+1 级指针的节点数/含有i 级指针的节点数 p
再插入一个新节点时
- 现将节点级别 k 初始化为 0
- 然后用随机数生成器反复的产生一个 间的随机实数q
- 如果q<p,则是新节点级别 k 增加 1,直至 或 用 作为新节点级别的上界。其中 n 是当前跳跃表中节点个数
拉斯维加斯算法


是一次成功的概率; 是求解失败的时间,还要加上再次求解成功的平均时间
N 后问题-拉斯维加斯算法

结合回溯法,就是前面几行用拉斯维加斯算法,后几行使用回溯法 行数较少,拉斯维加斯算法随机能得到解的概率会更大;在排好一些行之后,使用回溯法,回溯法的树变的更小,搜索更快;回溯树的树高越高节点散开的分支越多,越不容易搜索
结合回溯法
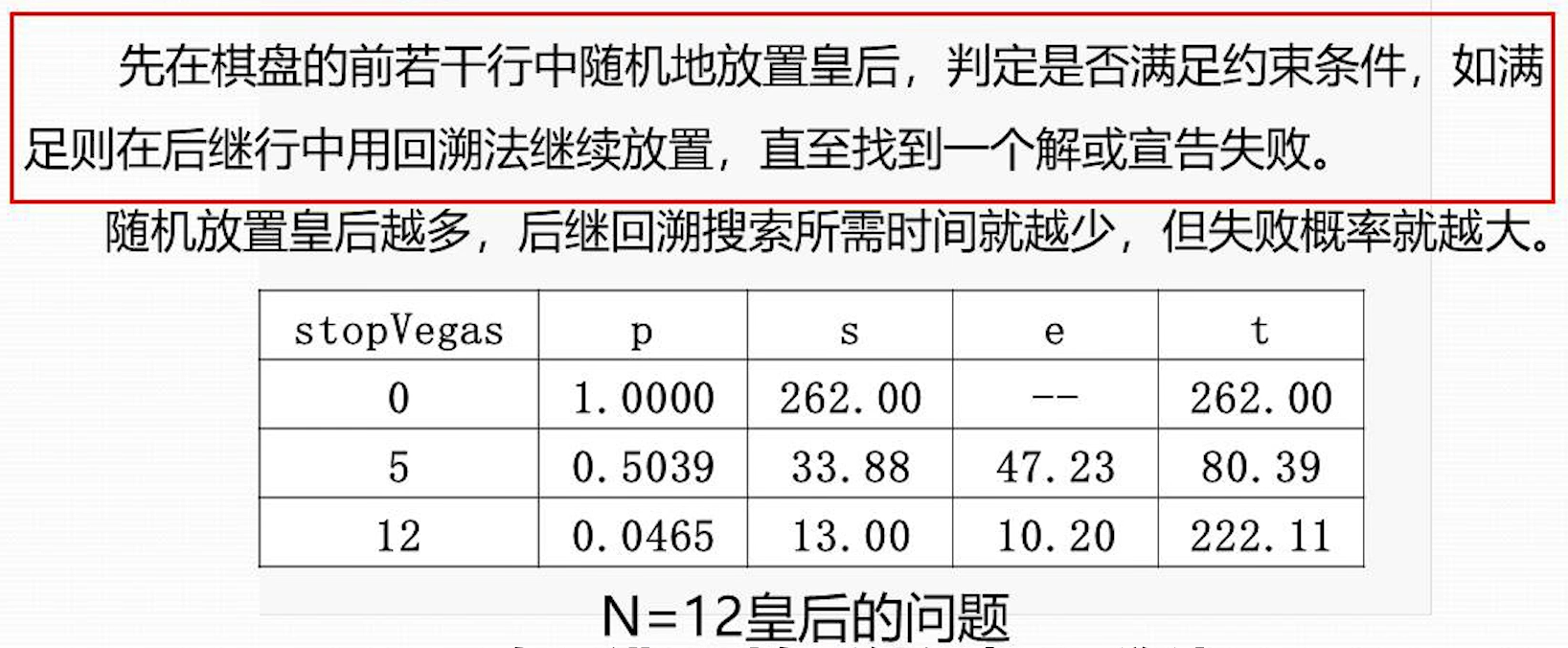
观察表格 p 是拉斯维加斯算法找到解的概率。S 是拉斯维加斯算法耗费时间,e 是回溯法耗费时间,t 是总耗费时间 第一行是代表没有使用 lv 算法,第二行前 5 行使用 lv 算法,第三行 12 行全部使用 lv 算法 观察表格,只是用 lv 算法和回溯法(第 3 行和第 1 行)花费时间较多; 结合两种方法(第 2 行)花费时间少
正数因子分解

问题是分解出一个整数的一个因子;split 函数是遍历的方法寻找到他的一个因子
Pollard 算法思想
- 选取 范围内的随机数 x 1
- 由 ,产生无穷序列
- 对于 ,以及 ,算法计算出 与 n 的最大公因子
- 如果 d 是 n 的非平凡因子,则实现对 n 的一次分割,算法因子d
算法实现
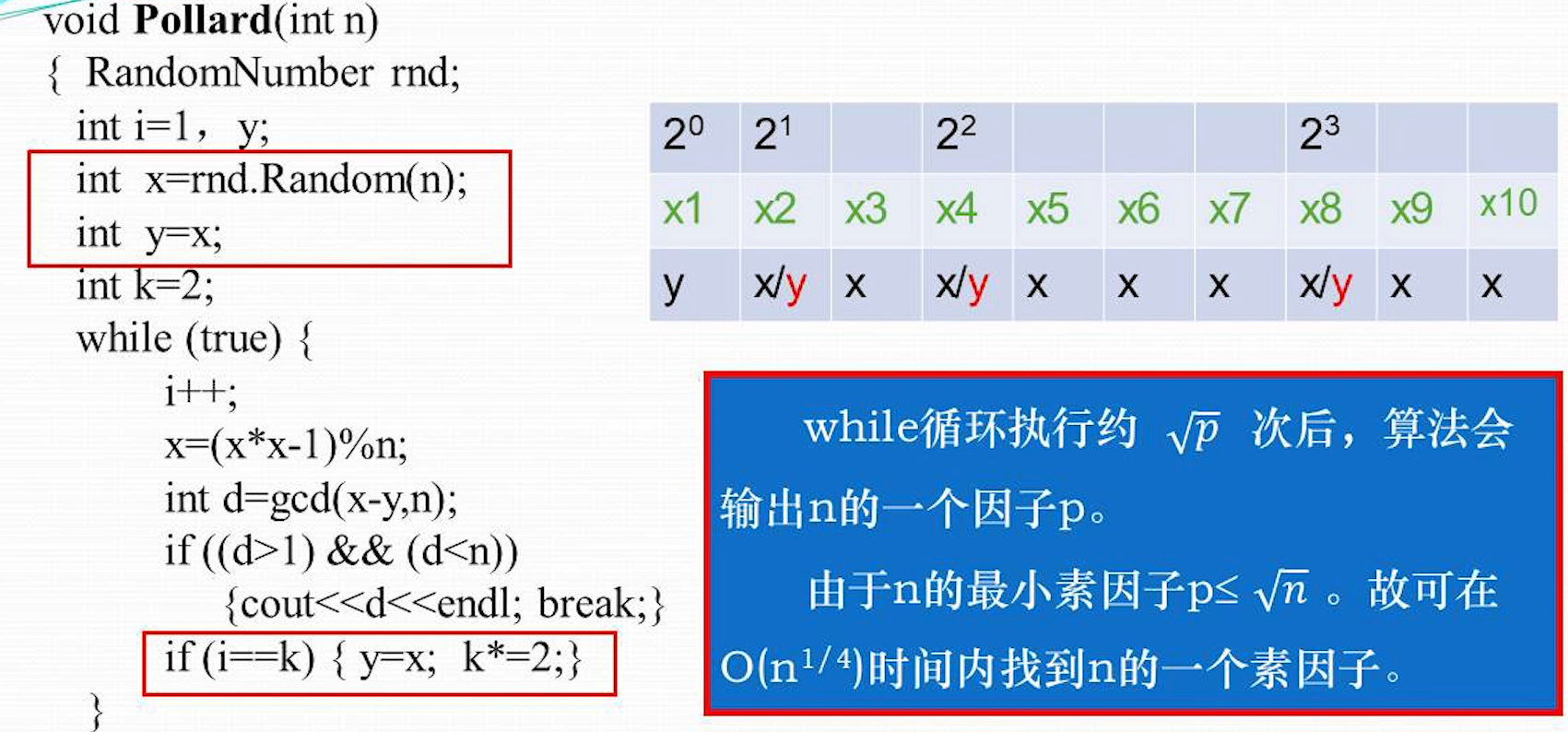
这里使用 x-y 和 n 求 gcd 的方法,比较复杂,大概是生成随机数的过程,是一个伪随机过程,生成大量数据之后,其中会出现循环数据,这些循环数据是和 n 有关的,且可以认为循环数据之中 n 的因子也会形成循环,就是循环中的循环;通过 x-y 可能会找到,x,y 是 mod p 余数一样的数字,但是 x 和 y 不相等,那么他们的差肯定某个数的倍数,这个差和 n 在做最大公约数成功的机会就更高了
Lv 算法,会拿可能是某个数倍数的数(这个数是因为伪随机数字会产生周期性的环导致的,这些重复数据更容易出现同余数,同余数做差得到这个倍数的数),这个数它肯定有因子,这样和 n 做 gcd 比直接随机一个数字更高效一点
Pallard 算法依赖生成的伪随机数的周期性,
蒙特卡洛(Monte Carlo)算法
一些问题,不论采用确定性算法或概率算法都无法保证每次都能得到正确的解答
蒙特卡罗算法则在一般情况下可以保证对问题的所有实例都以高概率给出正确解,但是通常无法判定一个具体解是否正确
蒙特卡洛算法

主元素问题
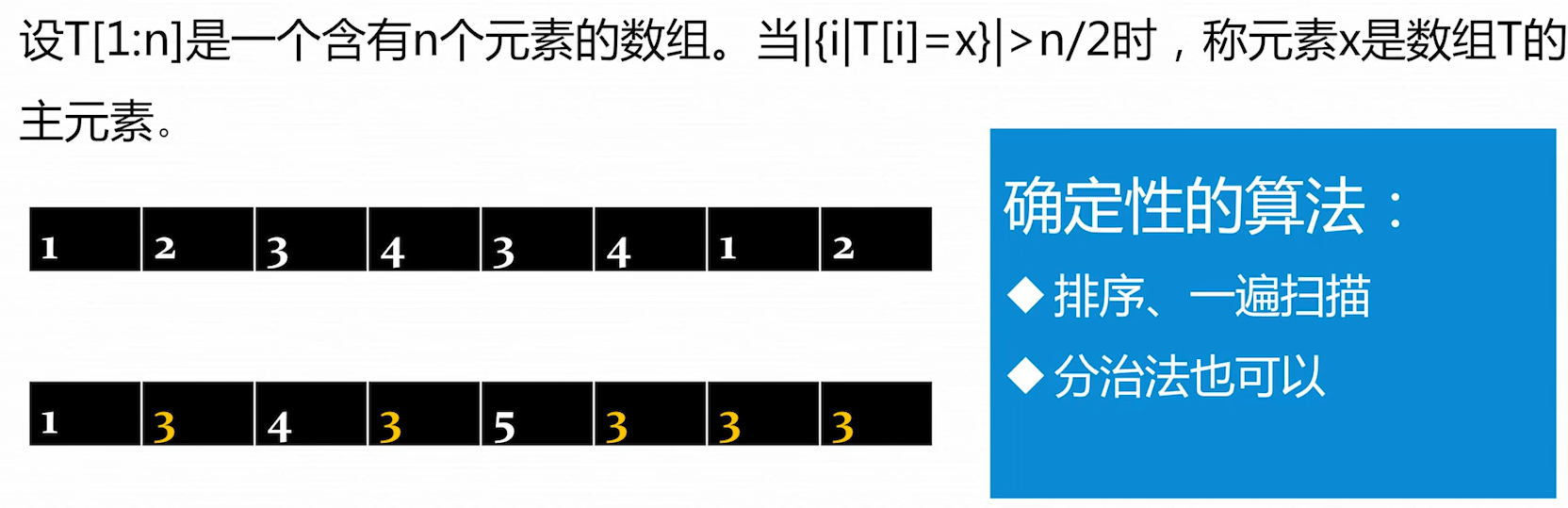
主元素:这个数值的数量大于总元素数量的一般,如第二行的 3 使用确定性算法,可以先排序,在遍历一下,算每一个元素出现次数有没有超过总数一半的

左边函数,随机一个 i,查看所有数据中 i 出现的次数是否超过总数的一半 用出错率生成随机生成 i 的次数k 随机 k 次看一下有没有出现主元素的情况

蒙特卡洛算法是根据设定的错误率,来限制尝试的主元素 i 的次数
素数测试


偏假 3/4 的蒙特卡洛算法,进行 k 次 prime 函数之后抱枕错误率低于