算法的非正式定义
- 算法是一系列解决问题的清晰指令,及对符合一定规范的输入,在有限时间内获得所要求的输出
关于算法的几个要点
- 算法的每个步骤必须清晰、明确、不含糊
- 算法处理的值域必须自习定义
- 同一种算法可以用不同的形式描述
- 同一个问题可能存在不同的解决算法
- 同意一个问题的不同算法不仅解题思路不同,而且解题速度可能有显著差别
算法与程序
算法:满足下述性质的指令序列:
-
输入:有零个或多个外部量作为算法的输入
-
输出:算法产生至少一个量作为输出
-
确定性:组成算法的每条指令清晰、无歧义
-
有限性:算法中每条指令的执行次数、时间有限
-
正确性:对每一次输入,算法应产生正确的输出值
-
通用性:算法的执行过程可应用于所有同类求解问题,而不是仅适用于特殊的输入
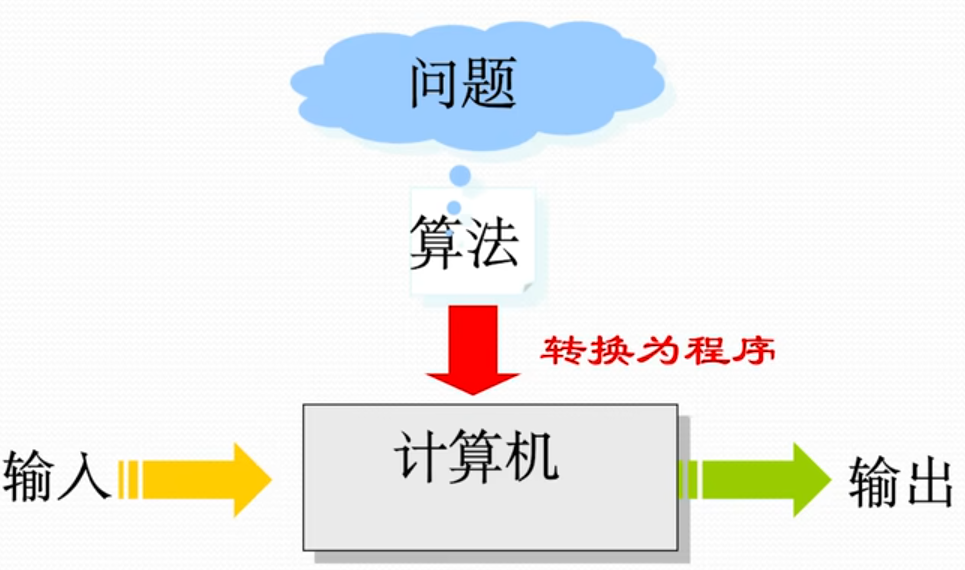
程序:是算法用某种程序设计语言的具体实现;代表了对特定问题的求解,而程序只是算法在计算机上的实现。 程序可不满足算法性质 4 操作系统是一种程序而不是算法
问题求解(Problem Solving)
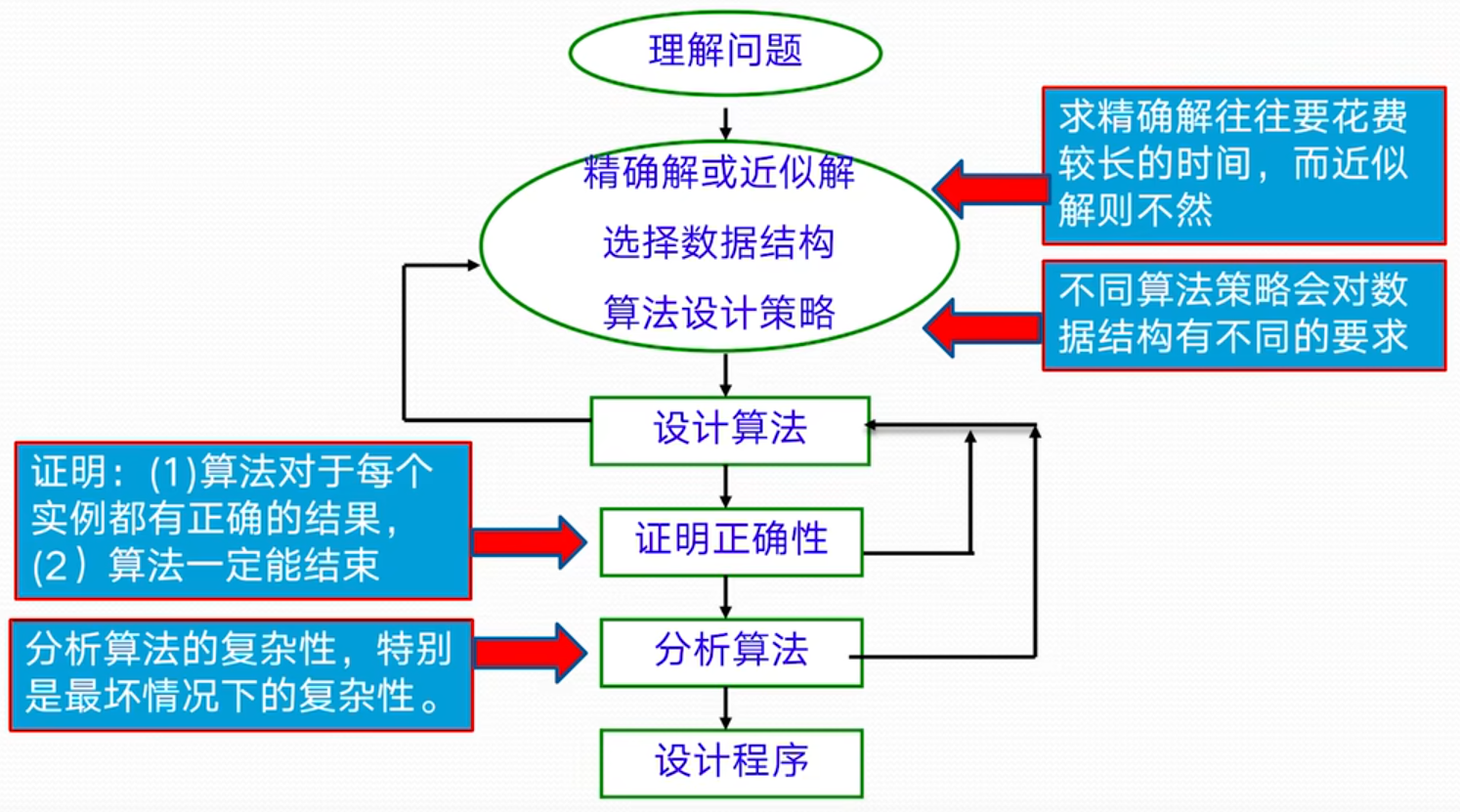
算法举例
求两个正整数吗、,n 的最大公约数
1. 欧几里得算法 :gcd(m, n)
其中 ,其递归定义
欧几里得算法描述方法 1-自然语言描述
第一步:如果 n = 0,返回 m 的值作为结果 同时过程结束;否则,计入第二步 第二步:用 n 去除 m ,将余数赋给r 第三步:将 n 的值赋给 m。将 r 的值赋给 n。返回第一步
欧几里得算法描述方法 2-伪代码描述

**欧几里得算法描述方法 3-C 语言描述

2. 连续整数检测算法
算法思想 基于最大公约数的定义:同时整除两个整数的最大正数
显然,不会大于两数较小这,故令:t=min (m, n) 用t除 m, n, 若除尽,t 即为最大公约数;否则令: t=t-1, 继续尝试
连续整数检测算法描述(自然语言)

3. 中学中计算最大公约数
将两个数字分解素数因子乘积的形式, 其中公共的素数因子相乘就是最大公约数,如下 2 x 2
 首先需要筛选出素数,逐个测试 n 中的公共因子,找素数使用埃氏筛法
首先需要筛选出素数,逐个测试 n 中的公共因子,找素数使用埃氏筛法
4. 埃拉托色尼筛法
算法思想
- 首先初始化一个 2~n 的连续序列,做候选素数
- 第一个循环消去 2 的倍数
- 然后,指向序列的下一个数字 3,消去其倍数
- 接下来指向 5,消去其倍数
- 按此方法不断做下去,直到序列中没有可消元素
代码
from math import sqrt
def ai(n):
"""埃氏筛法,输入数字的范围 0~n;素数标记为1"""
num_list = [0] * (n + 1)
for i in range(2, int(sqrt(n)) + 1):
if num_list[i] == 1:
num_list[i*i:n+1:i] = [1] * len(num_list[i*i:n+1:i])
return num_list算法时间复杂度分析

时间复杂度意义:
- 判断算法可行性
- 算法的优劣
时间复杂度的分析算法

对所有实例进行分析是不现实的,通常分析:最坏情况、最好情况、平均情况
最坏情况下的时间复杂性
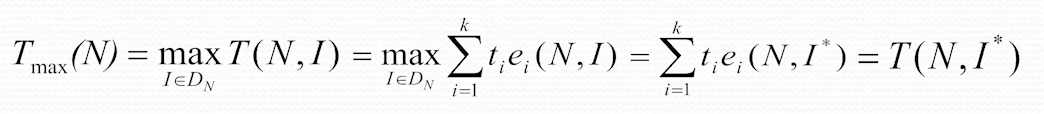
以花费时间最长的实例的花费时间为准,作为最坏情况下的时间复杂度
最好情况下的时间复杂度
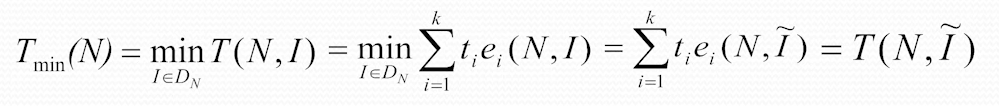
以花费时间最少的实例的花费时间为准,作为最好情况下的时间复杂度
平均情况下的时间复杂度
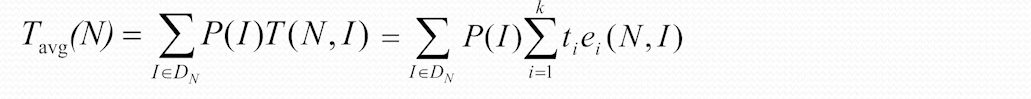
每一个实例发生的时间和对应的概率乘积的和, 作为平均情况下的时间复杂度
- 通常,我们讨论算法最坏情况下的时间复杂性,最好情况下的时间复杂性是特例下发生,意义不大
- 如果保证最坏情况下的时间复杂度是理想的,算法是能行的,对于问题的解决才有意义
- 算法的时间性分析分为二类
- 非递归算法的时间复杂性分析
- 递归算法的时间复杂性分析 两种类型的分析方法不同
非递归算法的时间复杂度分析(插入排序为例)
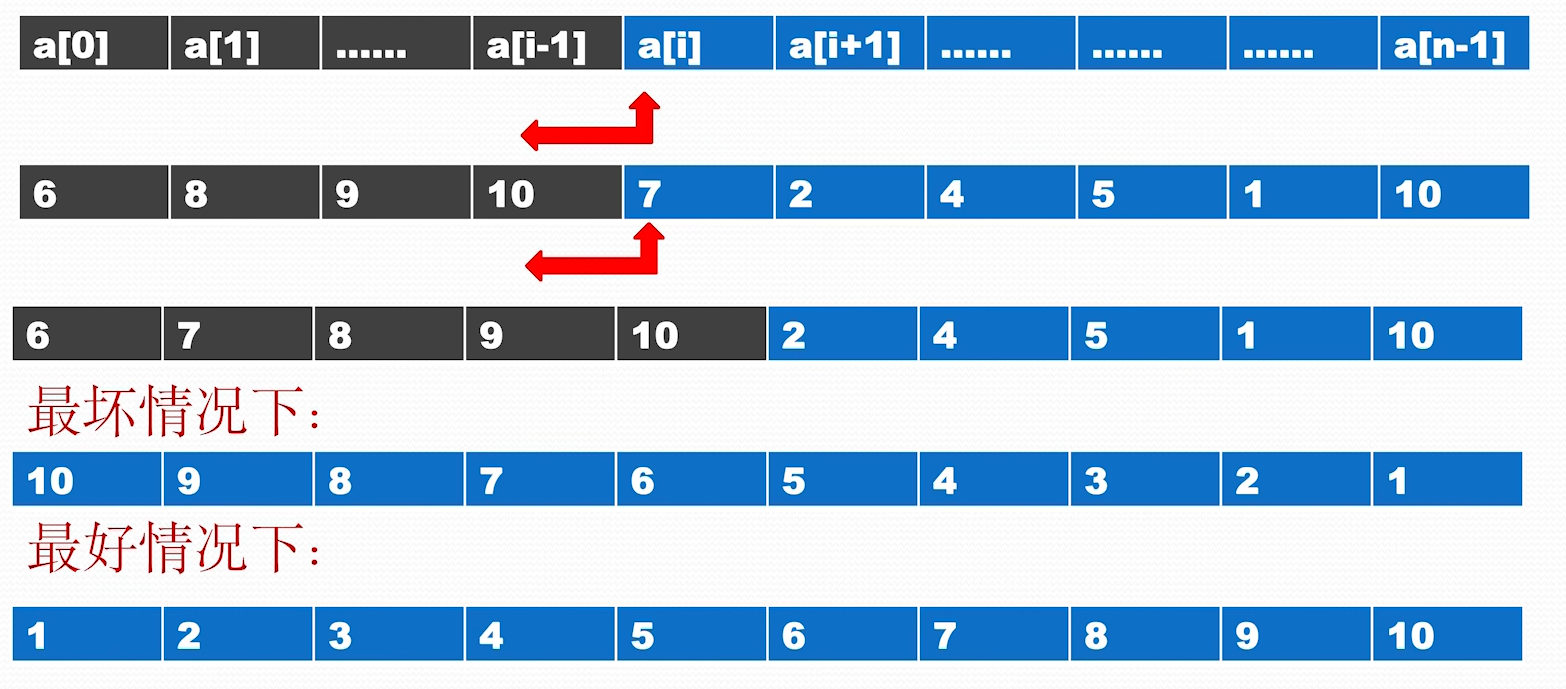
插入排序最差情况下,即完全逆序,复杂度 最好情况下已经排好顺序,复杂度
插入排序-C 语言描述

总的时间公式是:
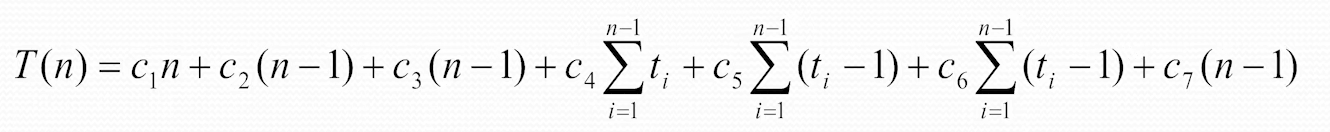
- 最好的情况下,
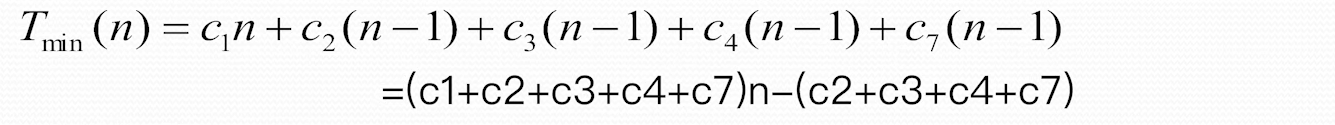
- 最坏的情况下
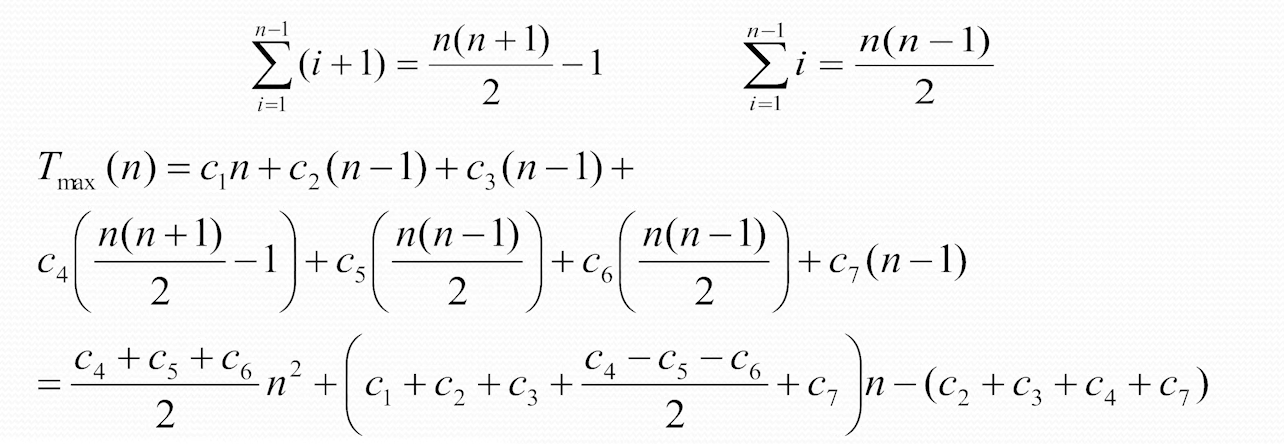
算法复杂度在渐进意义下的阶:
渐进意义下的记号: 是定义在正数集上的整函数。 为算法的时间复杂性, 是数据规模
-
渐进上界记号 若 含义:算法在任何实例情况下,其时间复杂性不超过 的阶数 即 如插入排序:
-
渐进下界记号 若 含义:算法在任何实例的情况下,其时间复杂性的阶不低于 的阶 即 如插入排序:
-
记号
 算法最好最坏的情况下时间复杂度相同,这就是 的含义
算法最好最坏的情况下时间复杂度相同,这就是 的含义 -
非紧渐进上界记号 若 含义:算法在任何实例情况下,其==算法时间复杂性的阶小于 的阶== 即 举例:
-
非紧渐进下界记号 若 含义:算法在任何实例情况下,其==算法时间复杂性的阶大于 的阶== 即 举例:
算法的 O 记号的快速分析步骤

只需要找被执行次数最多的代码,计算阶次
**例:顺序搜索算法

简便分析方法:

实例的概率和所花时间的乘积,来计算平均情况的时间复杂度
常见的时间复杂性函数
最优算法
- 问题的计算时间下界为 ,则计算时间复杂性为 的算法是最优的
- 例如,基于比较的排序算法的计算时间下界为 , 因此计算时间复杂度为 的排序算法是最优算法 故堆排序、合并排序是基于比较的最优排序算法
递归算法的时间复杂性的计算
递推方法
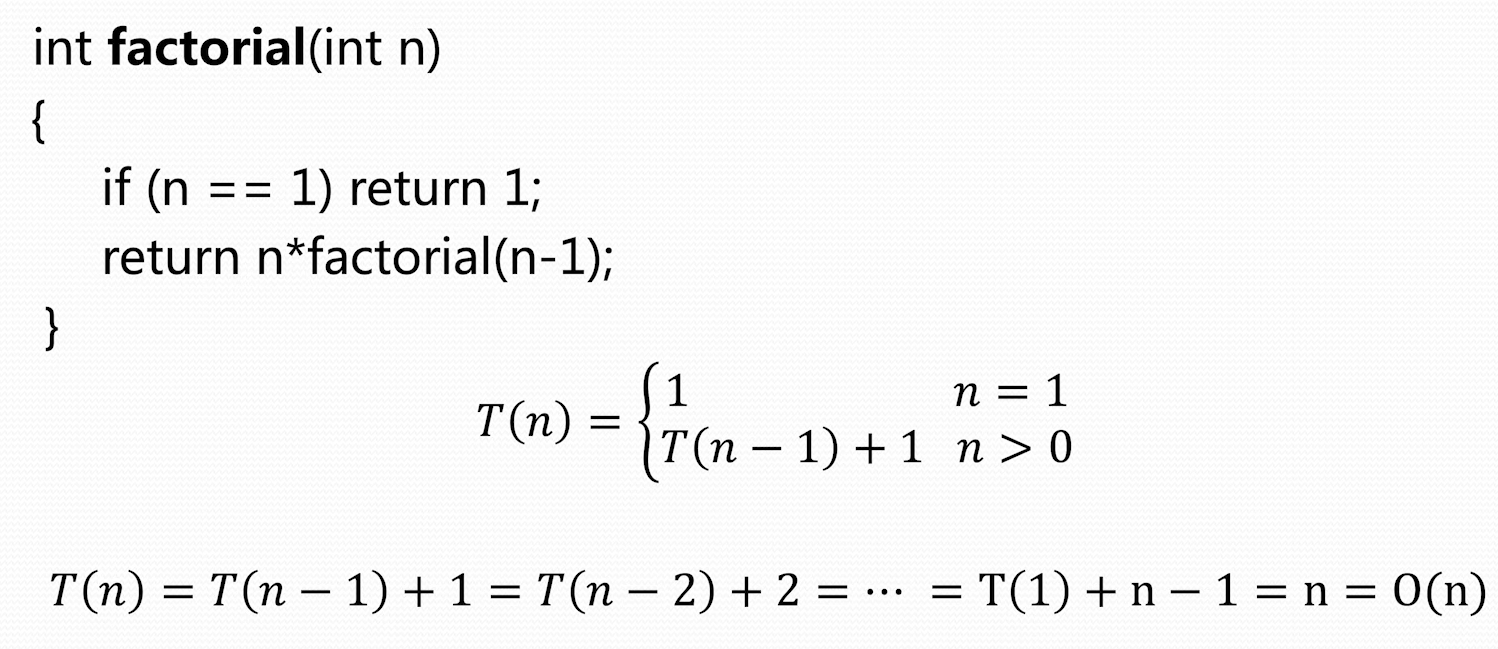 通过观察问题,来得到递推公式,如上求 的递归算法
通过观察问题,来得到递推公式,如上求 的递归算法
主定理-master 定理方法
在第二章分治策略中,通常设计为递归算法 其时间复杂性的递归定义一般有如下形式:
使用 Master 定理方法可以快速求解该方程 这里要求 为整数, 是正函数 详见第二章
主定理求解方法
- 首先根据$$ T(n)=\begin{cases} O(1) &n=n_{0} \ aT\left( \frac{n}{b} \right)+f(n) & n>n_{0} \end{cases}\Rightarrow n^{\log_{b}a}
T(n)=\begin{cases} 1 & n=1 \ 2T\left( \frac{n}{2} \right)+n &n>1 \end{cases}
$n^{\log_{b}a}=n^{\log_{2}2}=n,f(n)=n\rightarrow n^{\log_{b}a}=f(n)$ 因为:$f(n)=\Theta(n^{\log_{b}a})=\Theta(n)$ 根据 Master 定理规则 2: $T(n)=O(n^{\log_{b}a}\log n)=O(n\log n)$ **例 3:** 时间复杂度定义:T(n)=\begin{cases} 1 & n=1 \ 4T\left( \frac{n}{2} \right)+n^3 &n>1 \end{cases}
$n^{\log_{b}a}=n^{\log_{2}{4}}=n^2, f(n)=n^3\Rightarrow n^{\log_{b}a}<f(n)$ 因为:$f(n)=\Omega (n^{\log_{b}a+1}=\Omega(n^{2+1}))$, 这里 $\varepsilon=1>0$ 并且 $n>1$ 时,$4f\left( \frac{n}{2} \right)=4\left( \frac{n}{2} \right)^3=\frac{n^3}{2}<cf(n)=cn^3$,这里 $\frac{1}{2}\leq c<1$ 根据 Master 定理的规则 3: $T(n)=O(f(n))=O(n^3)$ **不能使用主定理求解的例子** 并不是所有的递归算法都能使用 master 定理  ### 递归树方法 - 递归树是迭代计算模型 - 递归树的生成过程与迭代过程一致 - 更具递归定义不断拓展递归树,指导边界条件(其值已知) - 对递归树产生的所有项求和就是递归方程的解 **例 1:** 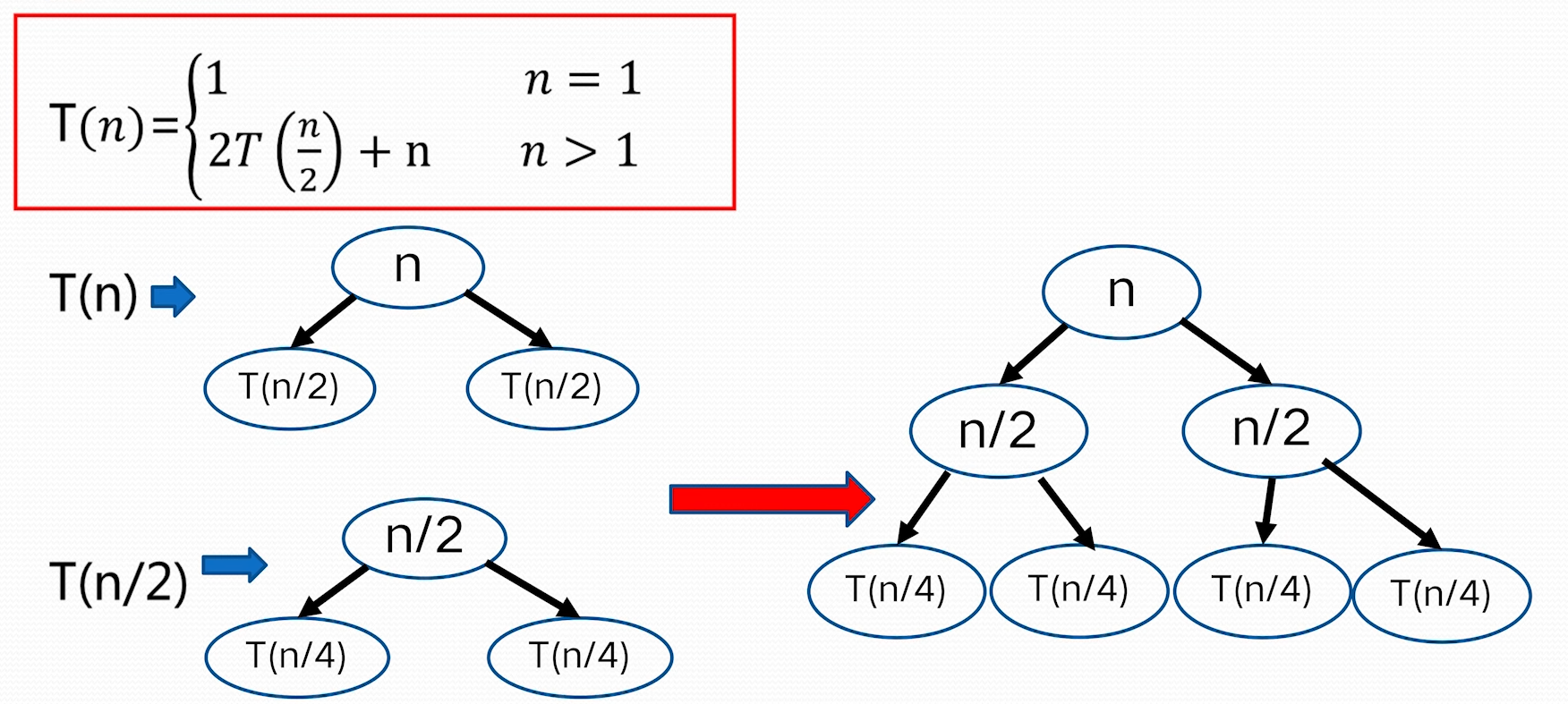 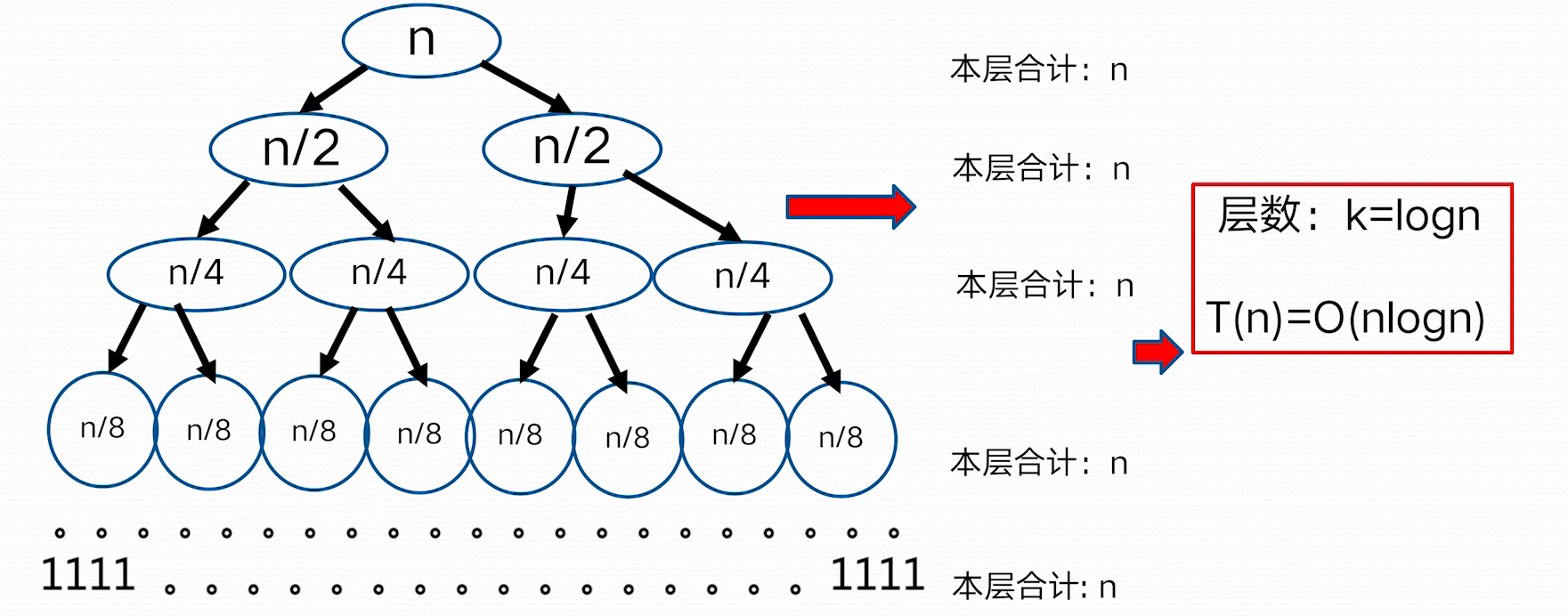 > 根据递归式对 n 进行分解,最底层 n=1;把所有层的和加起来得到结果 > 如上,每一层和是 n,层数为 $\log n$,所以 $T(n)=O(n\log n)$ > > 把f(n)放到母节点上,把他的子问题放到子节点上,依次拓展到子节点为 1> **例 2** 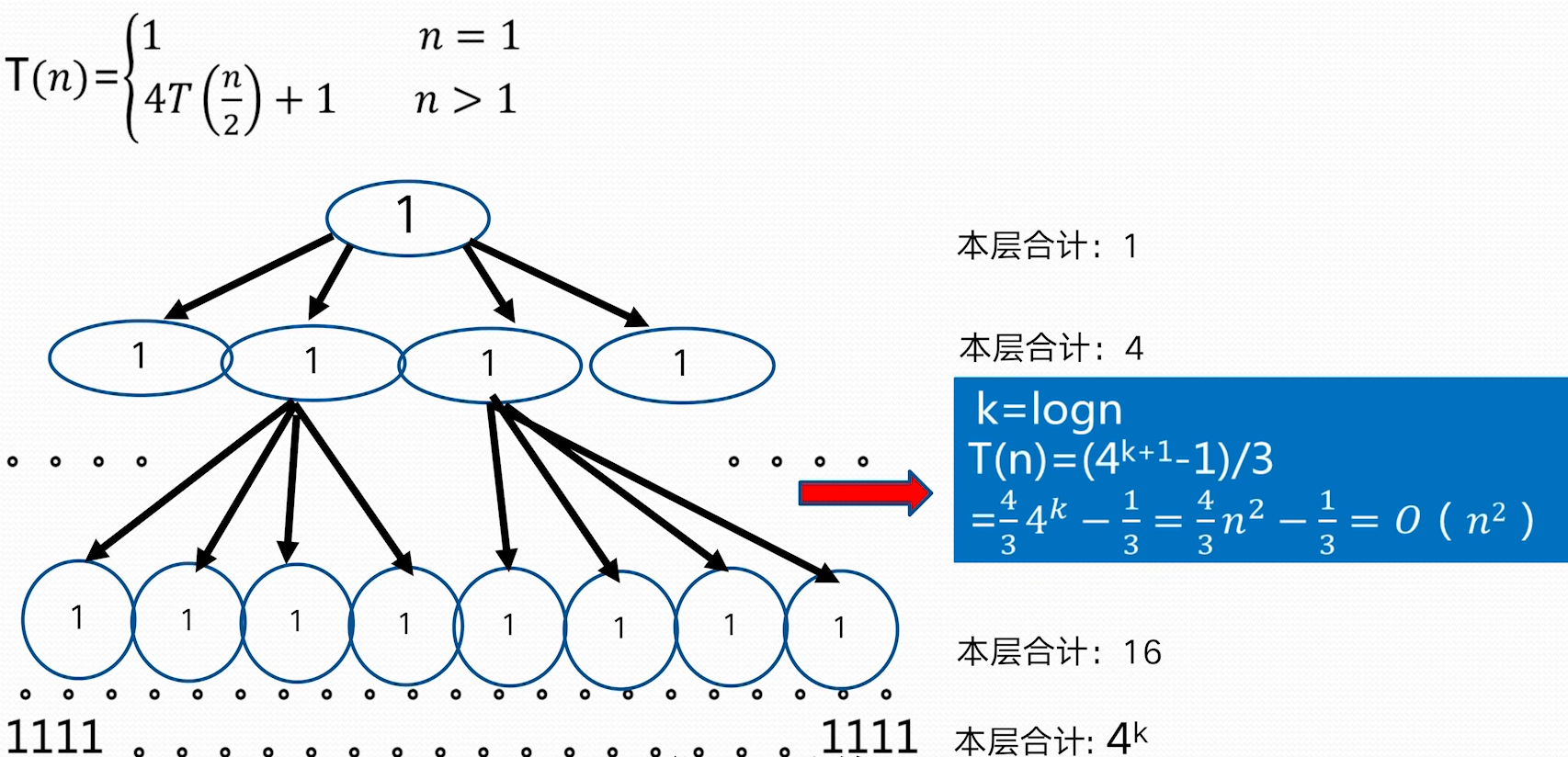 > 这里母节点 f (n)=1, 子问题问题是 4 个 $T\left( \frac{n}{2} \right)$,子问题的f(n)也是 1,这样形成了全是 1 的 4 叉树,子问题规模每一次减半,所以树高为logn;所有层求和得总的时间复杂性 $T(n)=O(n^2)$ **例 3** 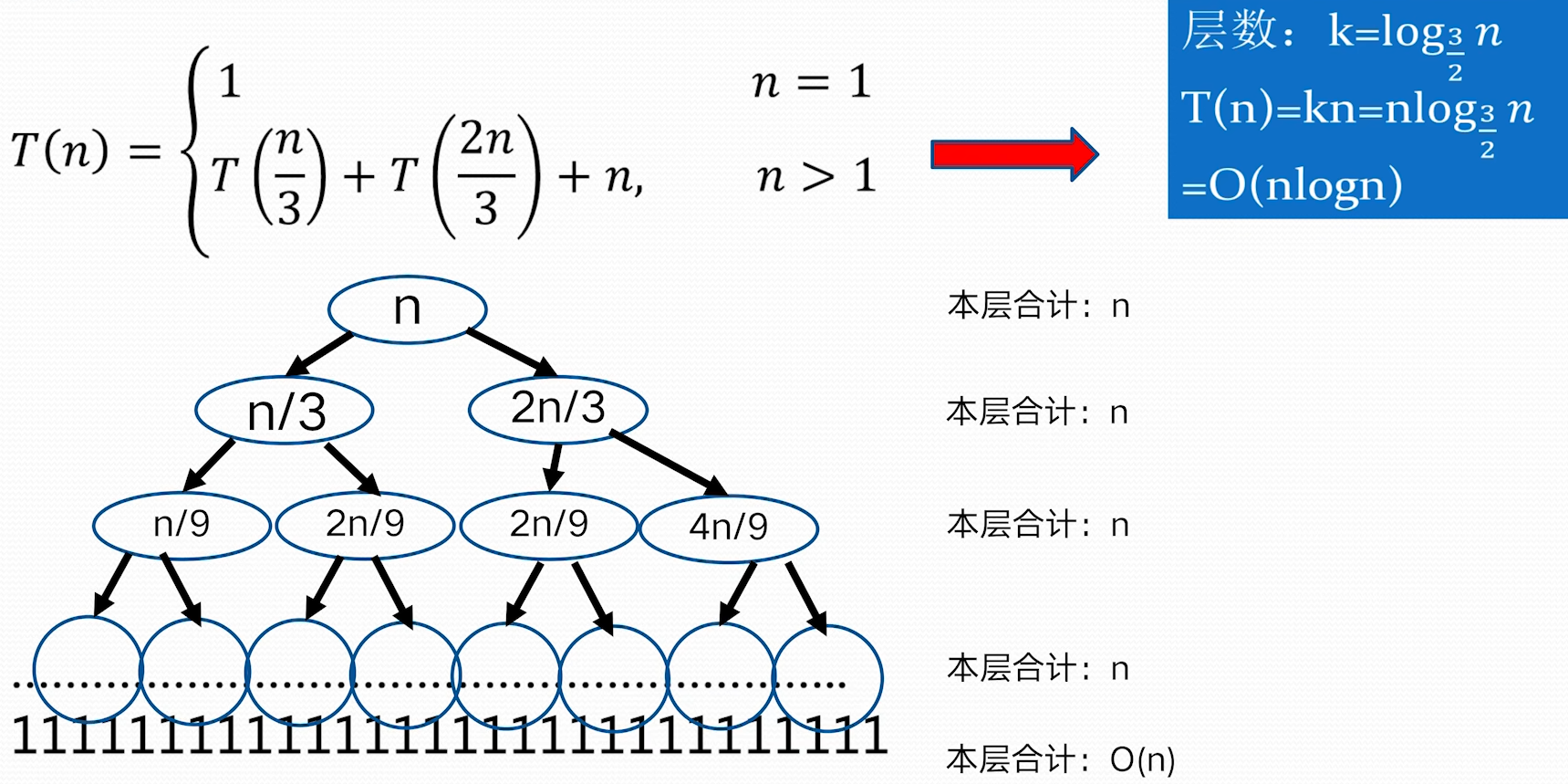 > 母节点f(n)=n, 每层两分叉,$T\left( \frac{2n}{3} \right)$ 这一分支会更深一点,导致到后面的层,整层的和到不了 n,以为另一分支会提前结束。 > 我们为了方便计算,适当放大一点,把最后的层都看作和为 n > > 层数:$k=\log_{\frac{3}{2}}n$ > $T(n)=kn-n\log_{\frac{3}{2}}n=O(n\log n)$ **其他方法**: # 小结\begin{align} T_{1}(n)&=\sum_{j=0}^{k} \frac{n}{2^{j}}=\sum_{j=0}^{\log n} \frac{n}{2^j} \ T_{2}(n)&=\sum_{i=1}^{n} \lfloor \frac{n}{i} \rfloor \ T_{3}(n) &= n(k+1)=n(\log \log n+1) \end{align}