笔记仓库链接:0000-复习课
第 1 章
1 . 什么是算法
算法是解决问题的一种方法,是由若干条指令组成的有穷序列
2 . 算法与程序的区别有哪些
算法是满足以下性质的指令序列:
- 输入:零个或者多个外部量作为算法的输入
- 输出:至少产生一个量作为输出
- 确定性:组成算法的指令是清晰、无歧义的
- 有限性:指令数量、执行时间有限
程序是某种程序语言的具体实现,可以不满足有限性
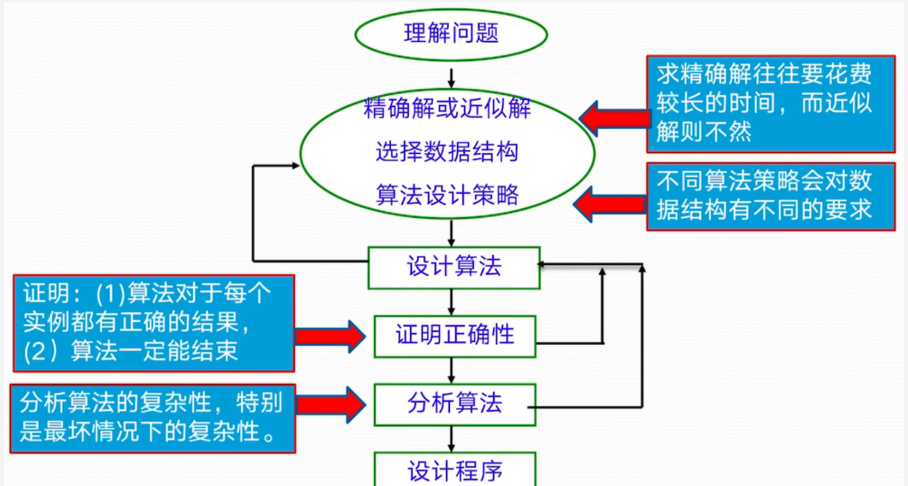
3 . 算法设计与分析的具体步骤是什么
问题定义→选择设计策略→设计算法→证明正确性→分析算法→设计程序
4 . 记号的含义与关系
渐进意义下的记号: 是定义在正数集上的整函数。 为算法的时间复杂性, 是数据规模
-
渐进上界记号 ---- ⇐ 若 含义:算法在任何实例情况下,其==时间复杂性不超过 的阶数== 即 如插入排序:
-
渐进下界记号 ---- >= 若 含义:算法在任何实例的情况下,其==时间复杂性的阶不低于 的阶== 即 如插入排序:
-
记号 ---- ==
 算法最好最坏的情况下时间复杂度相同,这就是 的含义
算法最好最坏的情况下时间复杂度相同,这就是 的含义 -
非紧渐进上界记号 ---- < 若 含义:算法在任何实例情况下,其==算法时间复杂性的阶小于 的阶== 即 举例:
-
非紧渐进下界记号 ---- > 若 含义:算法在任何实例情况下,其==算法时间复杂性的阶大于 的阶== 即 举例:
关系:
定理 1: 即渐进上下界相等时
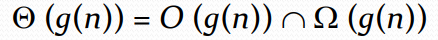 性质:
性质:

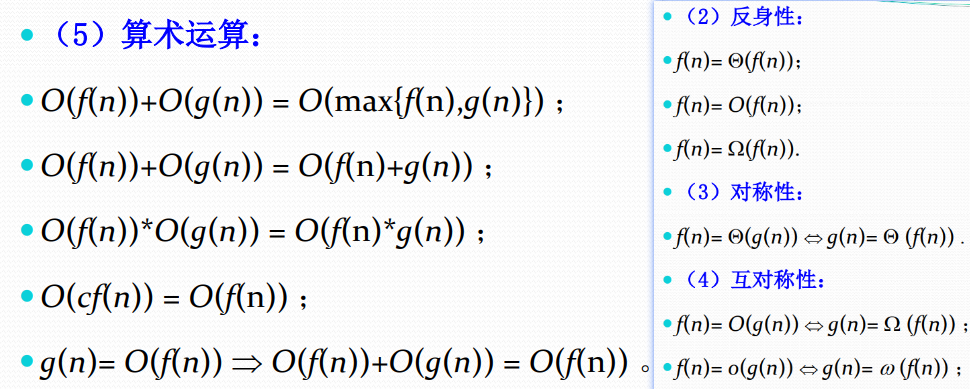
5. 递归树、主定理求时间复杂度
主定理求解方法
- 首先根据 $$ T(n)=\begin{cases} O(1) &n=n_{0} \ aT\left( \frac{n}{b} \right)+f(n) & n>n_{0} \end{cases}\Rightarrow n^{\log_{b}a}
T(n)=\begin{cases} 1 & n=1 \ 2T\left( \frac{n}{2} \right)+n &n>1 \end{cases}
> $n^{\log_{b}a}=n^{\log_{2}2}=n,f(n)=n\rightarrow n^{\log_{b}a}=f(n)$ > 因为:$f(n)=\Theta(n^{\log_{b}a})=\Theta(n)$ > 根据 Master 定理规则 2: $T(n)=O(n^{\log_{b}a}\log n)=O(n\log n)$ **例 3:** 时间复杂度定义:T(n)=\begin{cases} 1 & n=1 \ 4T\left( \frac{n}{2} \right)+n^3 &n>1 \end{cases}
> $n^{\log_{b}a}=n^{\log_{2}{4}}=n^2, f(n)=n^3\Rightarrow n^{\log_{b}a}<f(n)$ > 因为:$f(n)=\Omega (n^{\log_{b}a+1}=\Omega(n^{2+1}))$, 这里 $\varepsilon=1>0$ > 并且 $n>1$ 时,$4f\left( \frac{n}{2} \right)=4\left( \frac{n}{2} \right)^3=\frac{n^3}{2}<cf(n)=cn^3$,这里 $\frac{1}{2}\leq c<1$ > 根据 Master 定理的规则 3: $T(n)=O(f(n))=O(n^3)$ **不能使用主定理求解的例子** 并不是所有的递归算法都能使用 master 定理  ### 递归树方法 - 递归树是迭代计算模型 - 递归树的生成过程与迭代过程一致 - 更具递归定义不断拓展递归树,指导边界条件(其值已知) - 对递归树产生的所有项求和就是递归方程的解 **例 1:** 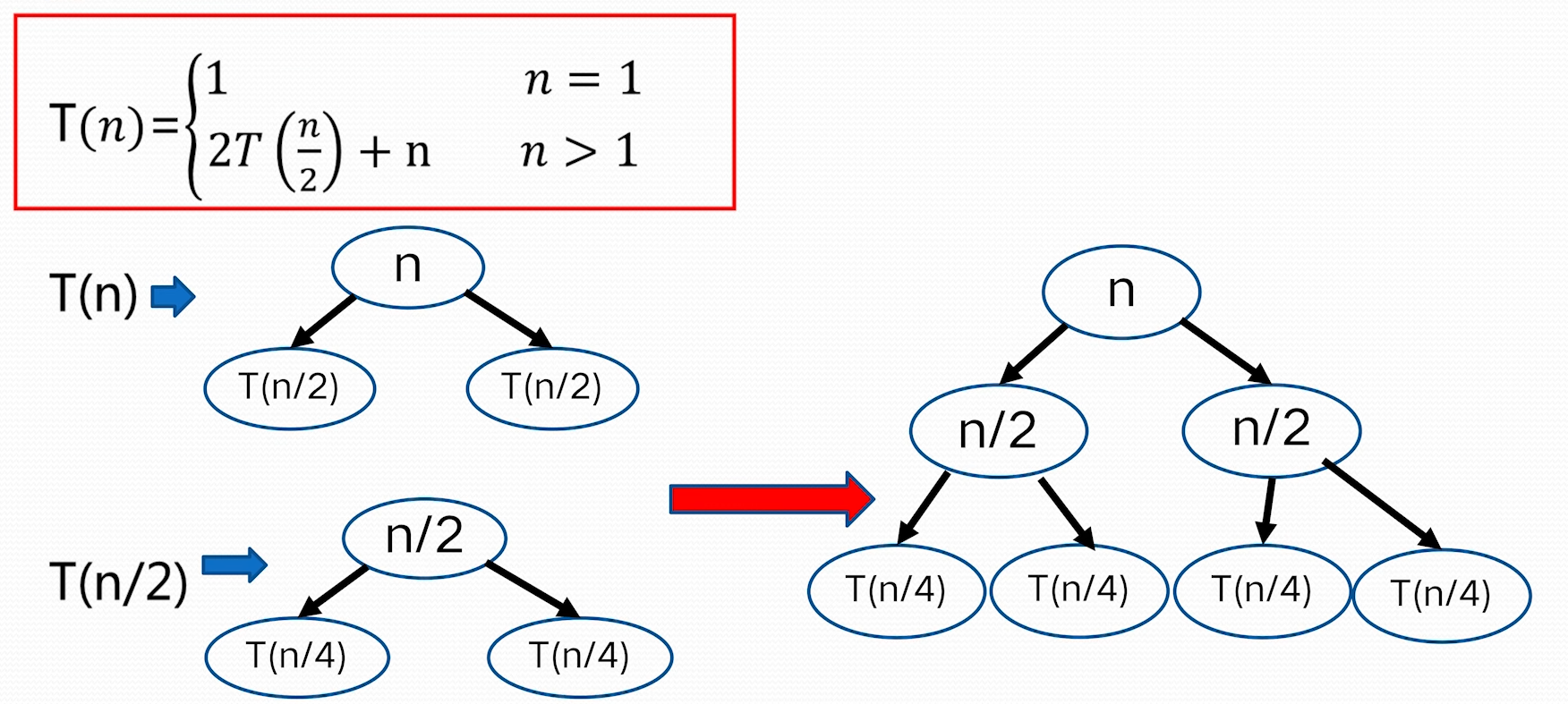 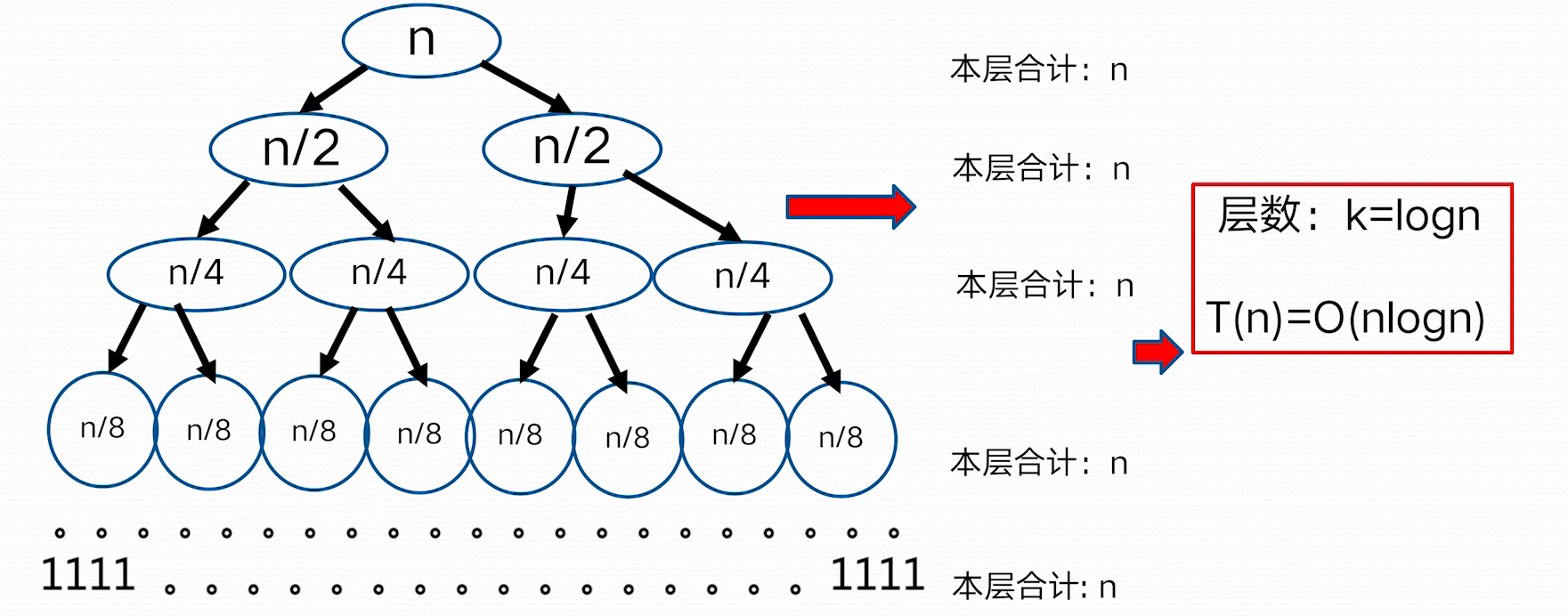 > 根据递归式对 n 进行分解,最底层 n=1;把所有层的和加起来得到结果 > 如上,每一层和是 n,层数为 $\log n$,所以 $T(n)=O(n\log n)$ > > 把 f(n)放到母节点上,把他的子问题放到子节点上,依次拓展到子节点为 1> **例 2** 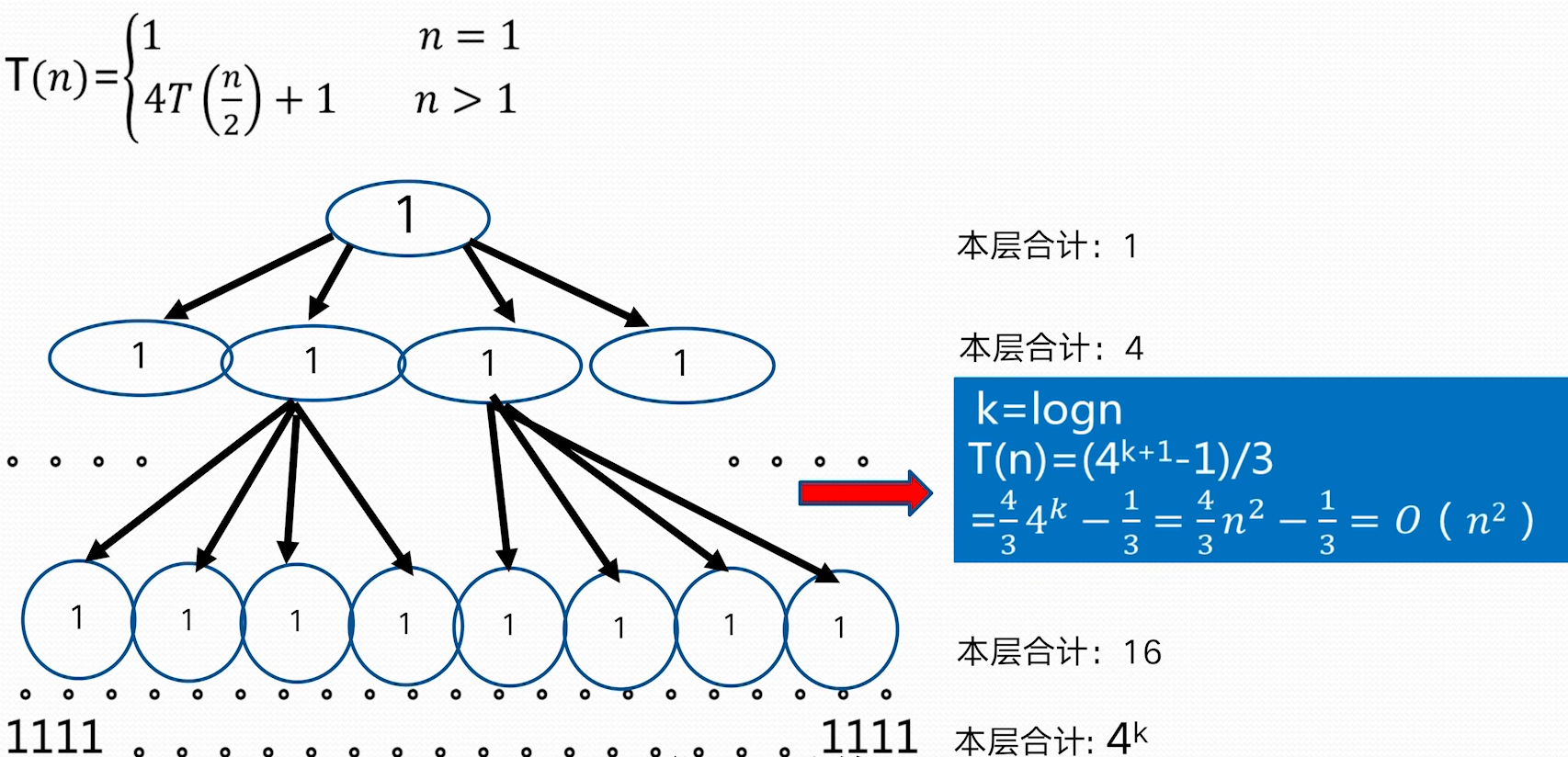 > 这里母节点 f (n)=1, 子问题问题是 4 个 $T\left( \frac{n}{2} \right)$,子问题的 f(n)也是 1,这样形成了全是 1 的 4 叉树,子问题规模每一次减半,所以树高为 logn;所有层求和得总的时间复杂性 $T(n)=O(n^2)$ **例 3** 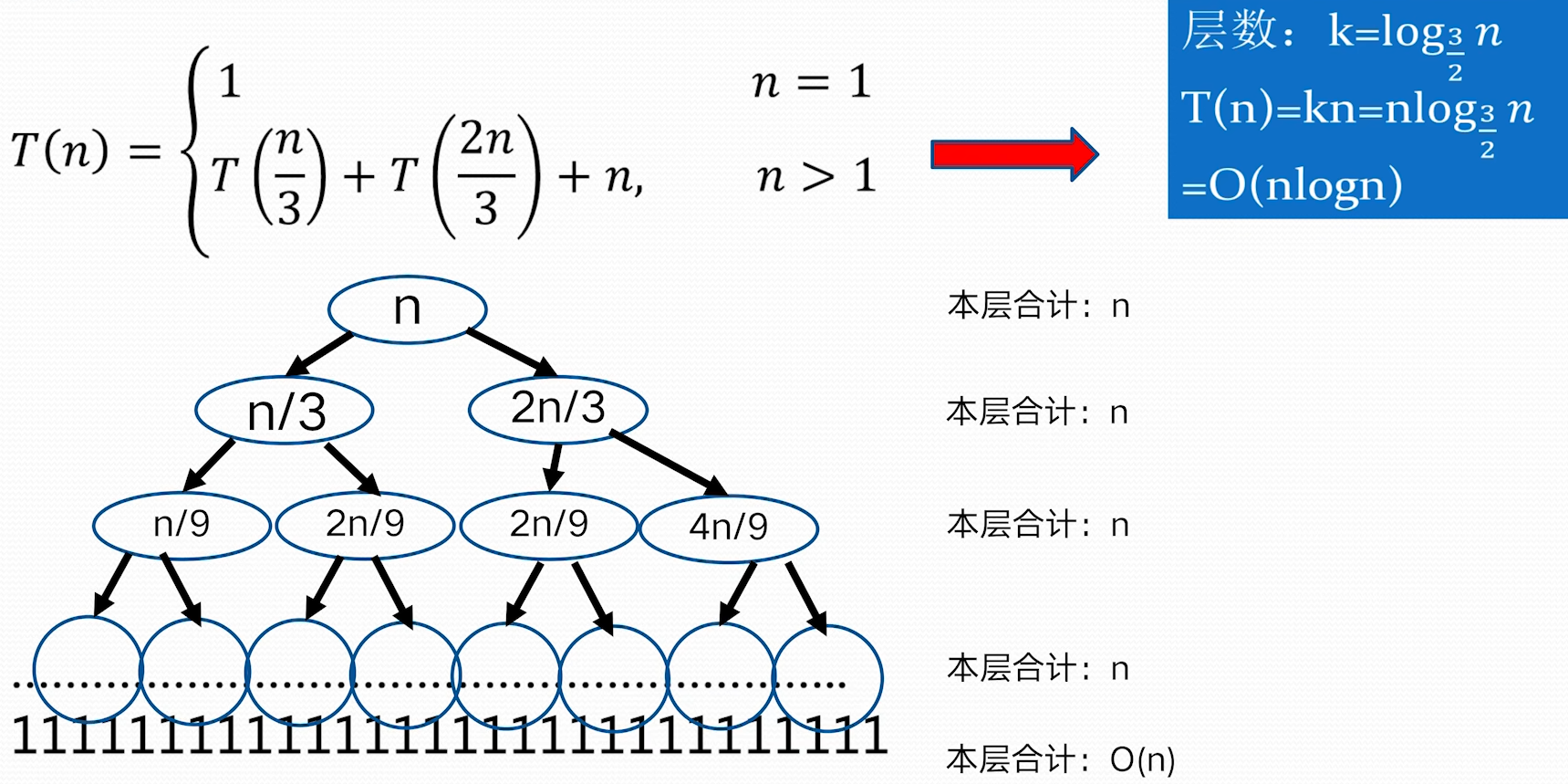 > 母节点 f(n)=n, 每层两分叉,$T\left( \frac{2n}{3} \right)$ 这一分支会更深一点,导致到后面的层,整层的和到不了 n,以为另一分支会提前结束。 > 我们为了方便计算,适当放大一点,把最后的层都看作和为 n > > 层数:$k=\log_{\frac{3}{2}}n$ > $T(n)=kn-n\log_{\frac{3}{2}}n=O(n\log n)$ # 第 2 章 ## 1 . 分治法能解决的问题一般具有哪些特征 1. 该问题的规模缩小到一定的程度就可以容易的解决 2. 该问题可以分解成若干个规模较小的相同问题 3. 利用该问题分解出的子问题的解可以合并为该问题的解 4. 该问题所分解出的各个子问题是相互独立的 > PS: > 其中 2,3 条表明子问题的最优解和该问题的最优解是一致的,这是==最优子结构性质==; > 第 4 条表明,分解出来的子问题是不重复的,共同组成该问题的解,这是==无重复子问题== > > 最优子结构性质和无重复子问题是分支法所能解决问题的必备要素 ## 2 . 二分搜索算法实现与时间复杂度分析 ## **二分搜索技术** 非递减序的 n 个元素 $a[0:n-1]$,现在要在这个元素众找出一特定元素 x 分析: 初始用 l、r 分别表示整个数组最左边和最右边的数据索引 一个子问题 $a[l:r]$,r<l 是表示没有任何元素,返回-1 - 设在 $a[l:r]$ 中找到 x,mid=(l+r)/2 1. 如果 $x==a[mid]$,则找打 2. 如果 $x<a[mid]$,继续在 $a[l, mid]$ 中找 x 即可,即令 r=mid 3. 如果 $x>a[mid]$,继续在 $a[mid,r]$ 中找 x 即可,即令 l=mid 子问题的答案就是大问题的答案,满足分支的四个适用条件 **算法描述**  **递归算法时间复杂度分析** 时间复杂性的递归方程T(n)=\begin{cases} 1 &n=0 \ T\left( \frac{n}{2} \right)+1 &n>1 \end{cases}
利用主定理或递归树可以求其时间复杂性为 $O(\log n)$ **非递归算法时间复杂性分析** 每执行一个循环,问题规模减半,即使最坏情况下,==时间复杂性为 $O(\log n)$== 虽然时间复杂度非递归方案和递归方案一样,但是非递归方案效率更高 ## 3 . 棋盘覆盖问题,回溯法、栈、队列求解的实例 **棋盘覆盖问题** 在一个 $2^k\times 2^k$ 个方格组成的棋盘之中,恰有一个方格与其他方格不同,成该方格为-特殊方格。且称该棋盘为-特殊棋盘。棋盘覆盖问题中,要用图示的 4 中不同形态的 L 型骨牌覆盖给定的特殊棋盘上除特殊方格以外的所有方格,且任何 2 个 L 型骨牌不得重叠覆盖  **思路** 当 k>0 是,将 $2^k \times 2^k$ 棋盘分割为 4 个 $2^{k-1}\times2^{k-1}$ 子棋盘(a)所示。特殊方格必位于较小子棋盘之中,其余 3 个子棋盘中无特殊方格。为了将这 3 个无特殊方格的子棋盘转化为特殊棋盘,可以用 L 型骨牌覆盖这 3 个较小棋盘的会合处,如图(b)所示,从而将原问题转化为 4 个较小规模的棋盘覆盖问题。递归的使用这种分割,直到棋盘简化为棋盘 $1\times 1$ 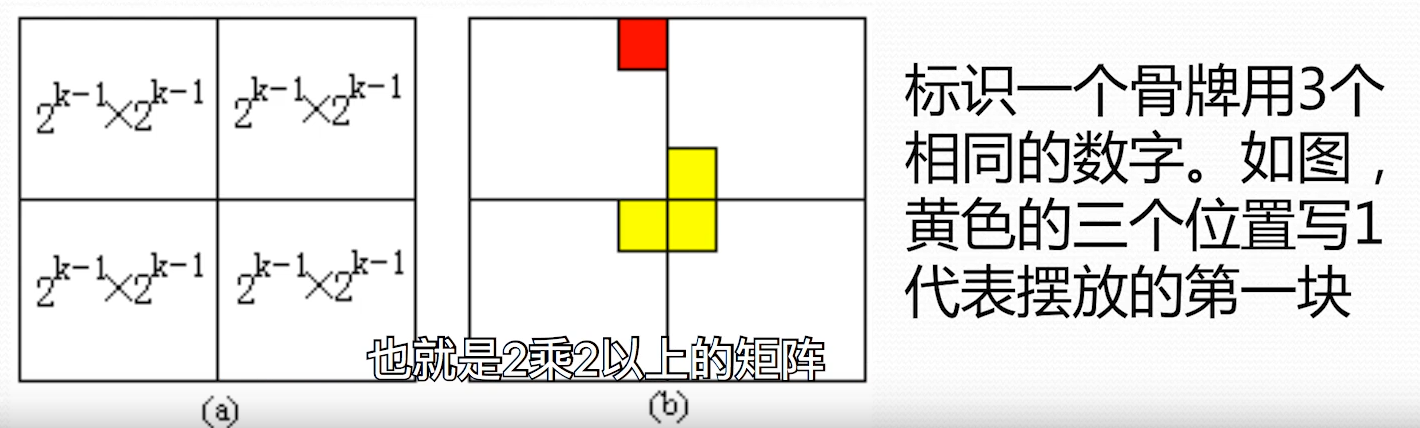 > 原棋盘分割成 4 个,在三个无特殊方格的棋盘添加一个 L 型骨牌,问题变成了 4 个和原问题相同性质的 4 个子问题 **算法描述**  > 其中 tr,tc 是左上角坐标,dr,dc 是特殊方格坐标,size 是棋盘大小, s 是子棋盘大小 > 四个 if 对应特殊方格在不同子棋盘中的情况 **时间复杂性**T(n)=\begin{cases} O(1) & n=1 \ 4T\left( \frac{n}{2} \right)+O(1)&n>1 \end{cases}
由主定理规则 1 ,可得时间复杂性 $T(n)=O(n^2)$ *本算法可使用队列或者栈实现非递归算法* ### 拓展 **队列实现** 队列先入先出 入队:一个大棋盘分为四个子棋盘,将四个子棋盘按序入队 出队:从队列中取出一个棋盘,将其分为四个子棋盘 注意:划分为四个子棋盘时,一个 L 型块被放入到棋盘中 **栈实现** 栈先入后出 入栈: 大棋盘分为四个子棋盘,将四个子棋盘按序入栈 出栈:从栈顶取出一个棋盘,将其分为 4 个子棋盘 注意:划分为四个子棋盘时,一个 L 型块放到棋盘中 ## 4 . 合并排序算法实现与时间复杂度分析 **合并排序** 将待排序元素集合分成大小大致相同的 2 个子集合,分别对 2 个子集合进行排序,最终将排好序的子集合合并成一个有序结合 **算法实现(递归)** ```cpp void MergeSort(Type a[], int left, int left) { if (left < right) // 至少两个元素 { int i=(left+right)/2; //取中点 MergeSort(a, left, i); // 左半部分 MergeSort(a, i+1, right); // 右半部分 merge(a, b, left, i, right); //两个部分排序合并, 放到临时数组b中 copy(a, b, left, right); // 把数组b复制回 数组a } } ``` **复杂度分析**T(n)=\begin{cases} O(1) & n\leq 1 \ 2T\left( \frac{n}{2} \right)+O(n) & n>1 \end{cases}
$T(n)=O(n\log n)$ 渐进意义下的最优算法 ## 5 . 快速排序时间复杂度分析 **快速排序算法的时间复杂型分析** - 快速排序算法的性能取决于划分的对称性 最坏的情况:每次划分成 2 个子问题,一个长度为 0. 另一个长度为 n-1,其对应的递归定义为: $$ T(n)=\begin{cases} 1 & n=1 \\ T(n-1)+n &n>1 \end{cases}最坏的时间复杂度:$O(n^2)$
平均时间复杂度:$O(n\log n)$
稳定性:不稳定
第 3 章
1. 动态规划算法求解的基本步骤
- 找出最优解的性质,并刻画其结构特征(最优子结构性质)
- 递归的定义最优值
- 以自底而上的方式计算出最优值
- 根据计算最优值时得到的信息,构造最优解
2. 动态规划与分治法的区别
相同点:
- 当问题规模较小的时候, 答案直接可得或者很容易解决
- 问题可分
- 小问题答案可以合并成大问题答案
不同点:
- 动态规划解决的问题存在大量重复,分治的子问题相互独立
3. 矩阵连乘问题算法与实例
矩阵连乘问题描述
- 给定 n 个矩阵 ,其中 与 是可乘的,. 考查这 n 个矩阵的连乘积
- 由于矩阵乘法满足结合律,所有计算矩阵的连乘可以有许多不同的计算次序。这宗计算次序用加括号的方式确定
- 若一个矩阵连乘积的计算次序完全确定,也就是说该乘积已完全加括号,则可以依次序反复调用两个矩阵相乘的标准算法计算出矩阵连乘积
如何确定计算次序,抱枕需要的连乘次数最少? 穷举法 列出所有可能的计算次序,并计算出每一种计算次序相应需要的数乘次序,从中找出一种数乘次数最少的计算次序 穷举法-算法复杂性分析 N 个矩阵的连乘积,设不同的计算次序为 . 因每种括号方式都可以分解成两个子矩阵的加括号问题:, 故 的递推式如下:
可以发现穷举法计算复杂度非常高,这种方案不可行
动态规划
1 . 首先分析最优解的结构
考查计算 A[i, j]的最优计算次序,设这个计算次序在矩阵 和 之间段考, 则其相应完全加括号方式为
这样这个问题就被划分成了两个子问题
- 特征:计算 的最优次序所包含的计算矩阵子链 和 的次序也是最优的
- 矩阵连乘计算次序问题的最优解包含着其子问题的最优解。这种性质称为最优子结构性质。可用动态规划算法求解的显著特征
的维数是 表示 的计算量 的计算量为 的计算量为
因此:
反证法可证明 是最优的,则 一定也是最优值( 常数)
2 . 建立递归关系(最优递归关系)

这里递归的时,需要找到 k 的值保证 最小
3 . 以自底向上的方式求最优解
- 对于 不同的有序对 对应不同的子问题。因此,不同子问题的个数共有:$$ \left(\begin{array}{ll} n \ 2 \end{array}\right)+n=\Theta(n^2)
m(1,j)=\begin{cases} v_{i}&j\geq w_{1} \ 0 &0 \leq j<w_{1} \end{cases}
m(i,j)=\begin{cases} max{m(i-1, j),m(i-1, j-w_{i})+v_{i}} & j\geq w {i} \ m(i-1, j) &0\leq j<w{i} \end{cases}
### 3 . 求最优值 **举例** 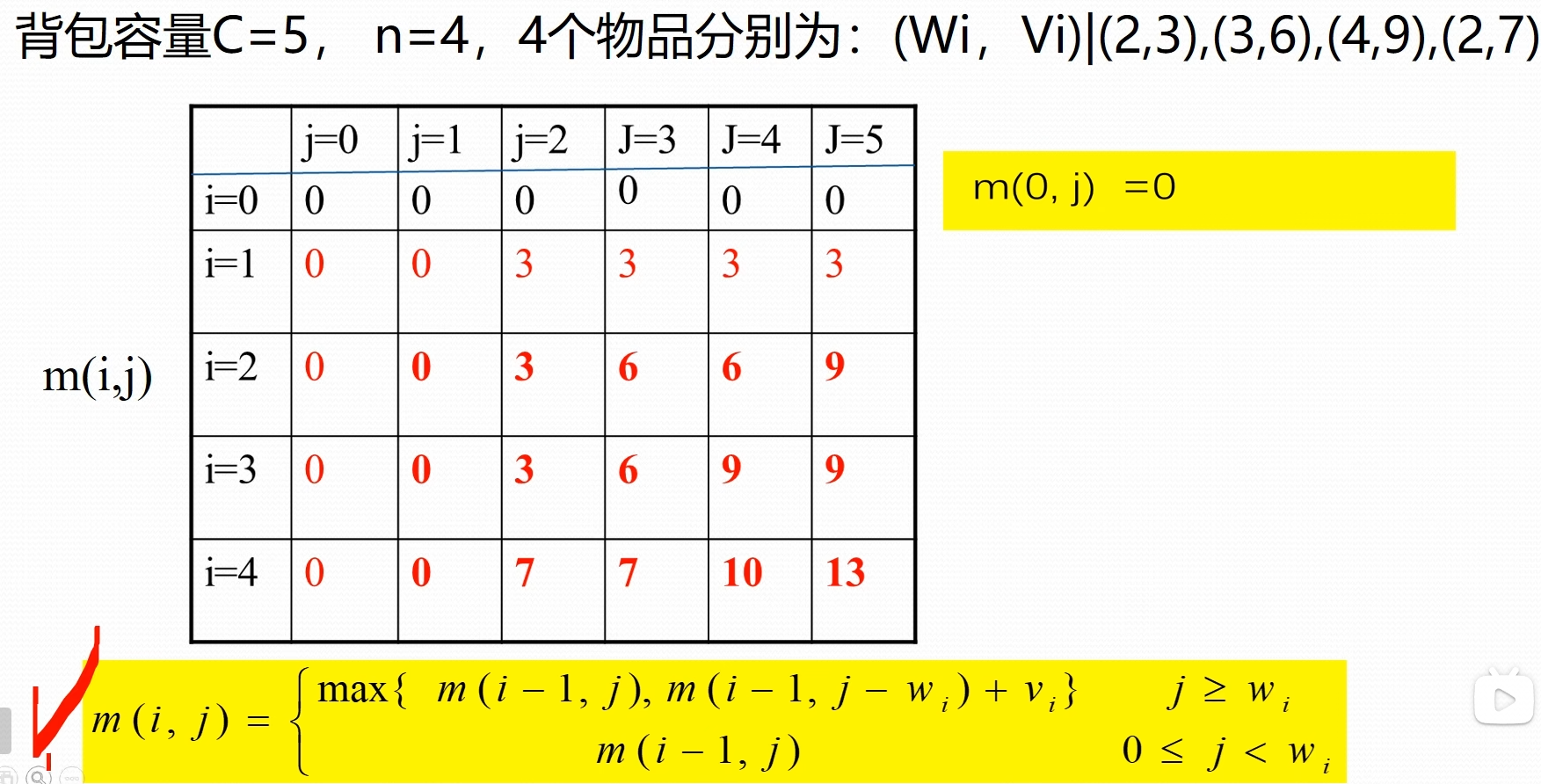 ### 4. 构造最优解 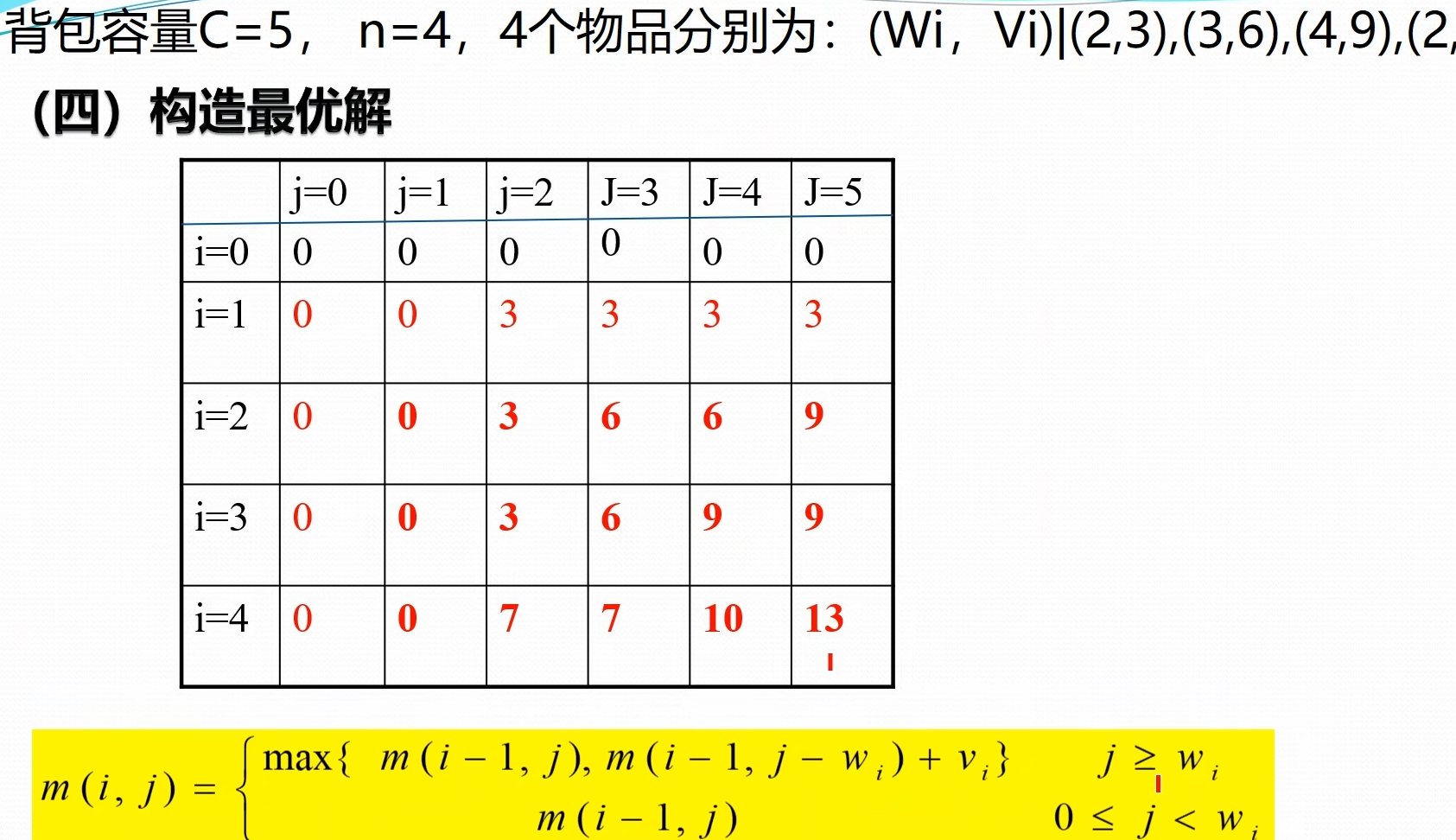 > 表格构造出来之后,构造最优解,最终的结果保存在右下角数值,根据递归式子,可以知道 $m[i,j]$ 来自于 $m[i-1][j]$ 或者 $m[i-1][j-w_{i}]$,从最右下角数据开始判断他是从那里过来,向上检索。如果是 $m[i-1][j]$ 代表没有选择当前第 i 个物品;否则选择了当前物品 ### 5. 算法设计   > 前面两层嵌套的for 循环计算出 m 表;剩下的代码找选择的物品 ### 6. 算法分析 由 $m[i][j]$ 递推式即表格可以看出,时间复发度 $O(nc)$,背包容量 c,物品数量 n 例如当 $c>2^n$ 时,算法需要 $\Omega(n{2}^n)$ 计算时间 # 第 4 章 ## 1. 贪心选择性质与最优子结构性质的定义 **贪心选择性质** *贪心选择性质*,是指所求问题的*整体最优解*,可以通过一系列*局部最优*的选择,即贪心选择来达到 贪心选择性质证明方法一步步的贪心选择(局部最优)最终导致问题的整体最优解 **最优子结构性质** 当一个问题的最优解包含其问题的最优解时,称此问题具有*最优子结构* 因为最优解对应最优值,所以通常证明:问题的最优值包含其子问题的最优解 ## 2. 贪心算法、动态规划算法、分治法的区别 - 性质相同点:贪心算法和动态规划算法都要求问题具有最优子结构性质 - 性质不同点:贪心算法要求问题就有贪心选择性质,动态规划和分治算法不要求 - 计算方式不同: 动态规划和分治算法通常==以自底向上的方式解各子问题== 贪心算法==以自顶向上的方式进行==,每做一次贪心选择就将问题变成规模更小的问题 ## 3. Prim 算法与 kruskal 算法思想、时间复杂度 **Prime 算法(选顶点加入集合 S)**  **Kruskal 算法(选择连接属于不同连接分支的最小边)**  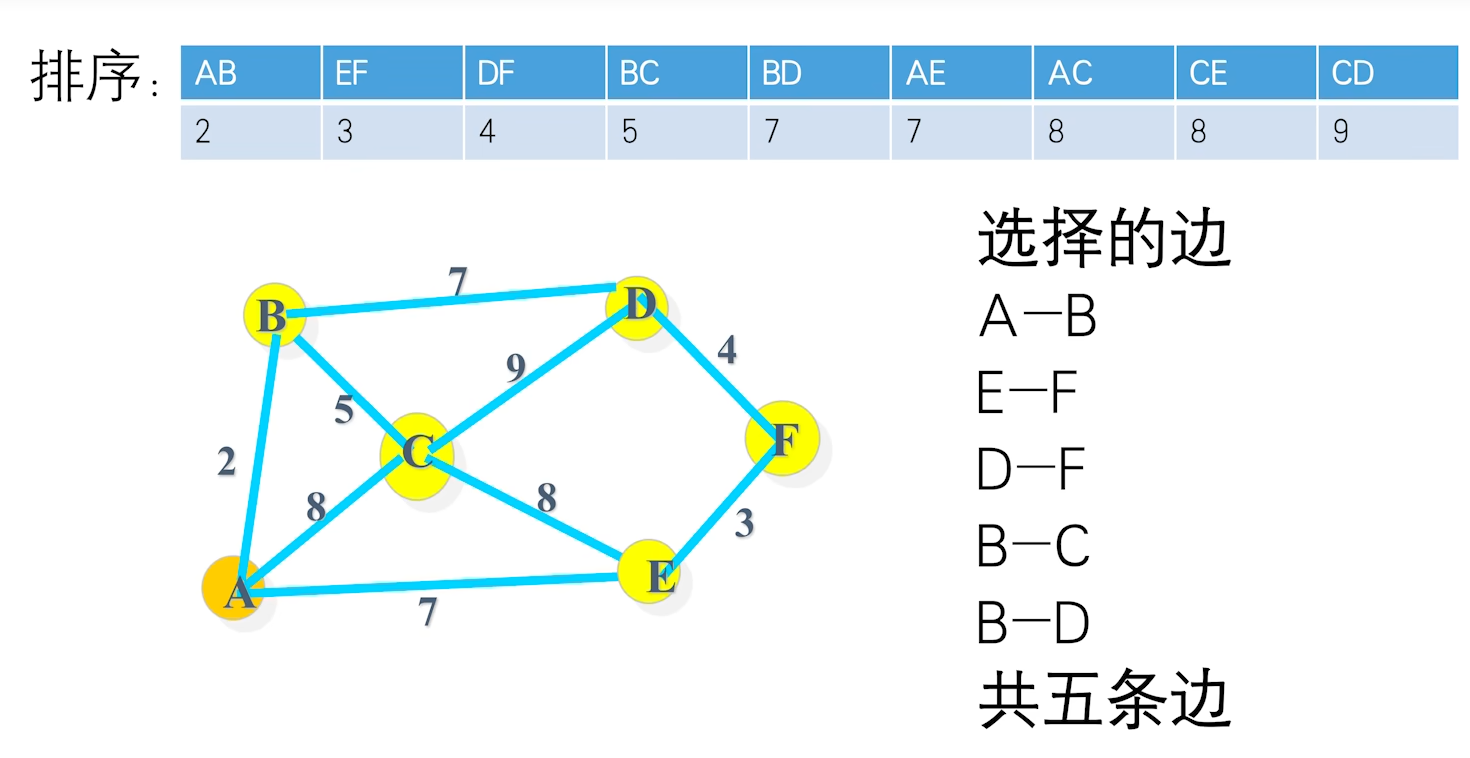 **时间复杂性对比**  ## 4. Dijkstra 算法的时间复杂度是多少  ## 5. 最优装载问题贪心算法正确性证明 **贪心选择性质**  > 这里是说有很多个最优解,类似前面活动安排,但是贪心算法实际上只能找到包含第一个集装箱的最优解,但是其他的最优解,我们可以证明,他可已使用第一个集装箱替换掉其中一个集装箱,这样集装箱数量不变,但是包含了第一个集装箱,这些都是最优解 >  > 普通最优解(0101)可以转换成贪心策略最优解(1100) **最优子结构性质** 最优装载问题具有最优子结构性质,设 1 至 n 个集装箱装上船的最大数量为 $T(1,n,w)$ 则 $T(1,n,w)=1+T(2,n,w-w_{1})$; 因 $T(1,n,w)$ 是最优值,则 $T(2,n,w-w_{1})$ 一定是最优值。反证法证明之  ## 6. 哈夫曼编码实例 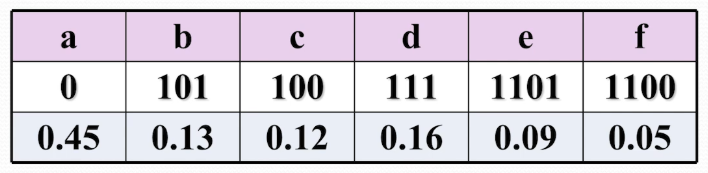  ## 7. 最小生成树算法正确性证明 ### MST 的最优子结构性质 命题: 设 $T$ 是图 $G$ 的最小生成树,边 $e$ 将 $T$ 分割为两个连通分量 $T_1$ 和 $T_2$。则 $T_1$ 必是其对应顶点集 $V_1$ 诱导子图的最小生成树。 **证明(反证法):** 1. **已知条件**:$T$ 是 $G$ 的最小生成树,其总权值为 $w(T) = w(T_1) + w(T_2) + w(e)$。 2. **假设反证**:假设 $T_1$ 不是该子图的最小生成树,则存在该子图的一棵更优生成树 $T_1'$,使得 **$w(T_1') < w(T_1)$**。 3. **构造新树**:保持 $T_2$ 和边 $e$ 不变,用 $T_1'$ 替换 $T_1$。构造新图 $T' = T_1' \cup T_2 \cup \{e\}$。 > _注:由于 $T_1'$ 涵盖了 $V_1$ 所有顶点且连通,$T'$ 依然是原图 $G$ 的一棵生成树。_ 4. 推导矛盾: 计算新树权值: $$w(T') = w(T_1') + w(T_2) + w(e)$$ 由于 $w(T_1') < w(T_1)$,显然有: $$w(T') < w(T_1) + w(T_2) + w(e) = w(T)$$ 即 $w(T') < w(T)$。这与“$T$ 是 $G$ 的最小生成树”这一前提矛盾。 5. **结论**:假设不成立,$T_1$ 必须是该子图的最小生成树。同理可证 $T_2$ 亦然。 ### MST贪心选择性质 **命题:** 设 $T$ 是图 $G$ 的最小生成树,$e$ 是 $T$ 中连接两个连通分量 $T_1$ 和 $T_2$ 的边,则 $e$ 必是连接 $T_1$ 与 $T_2$ 的所有边中权值最小的边。 **证明(反证法):** 1. **已知**:$T$ 为最小生成树,且 $T = T_1 \cup T_2 \cup \{e\}$,其权值为 $w(T) = w(T_1) + w(T_2) + w(e)$。 2. **假设反证**:假设 $e$ 不是连接 $T_1$ 与 $T_2$ 之间权值最小的边,则必然存在一条横跨这两个分量的边 $e'$,使得 $w(e') < w(e)$。 3. **构造新树**:利用 **“剪贴法” (Cut-and-Paste)**,构造一棵新的支撑树 $T' = T_1 \cup T_2 \cup \{e'\}$。 4. 推导矛盾: 由于 $w(e') < w(e)$,则: $$w(T') = w(T_1) + w(T_2) + w(e') < w(T_1) + w(T_2) + w(e) = w(T)$$ 即 $w(T') < w(T)$。 5. **结论**:这与 $T$ 是最小生成树(权值最小)的假设产生矛盾。因此,$e$ 必须是连接 $T_1$ 与 $T_2$ 之间权值最小的边。证毕。 # 第 5 章 ## 1. 常见的解空间树有哪几种?其规模分别是多大 子集树:$2^n$ 排列树: $n!$ ## 2. 装载问题算法与实例 **装载问题**  **以三个集装箱为例** 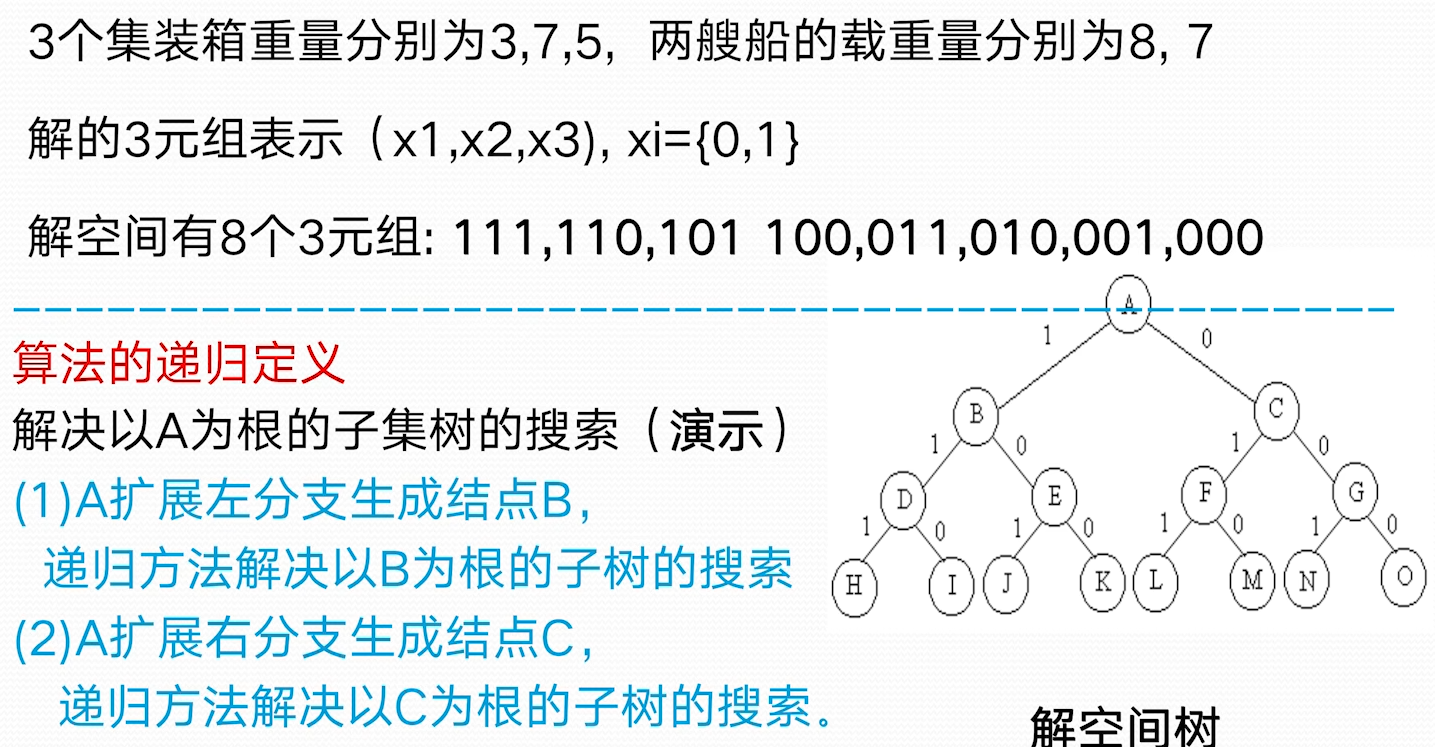 > 三个集装箱,每个集装箱有装和不装两个选择,可以得到解空间树如图 > 搜索这棵树来找到最佳答案 > 搜索方法使用递归方法 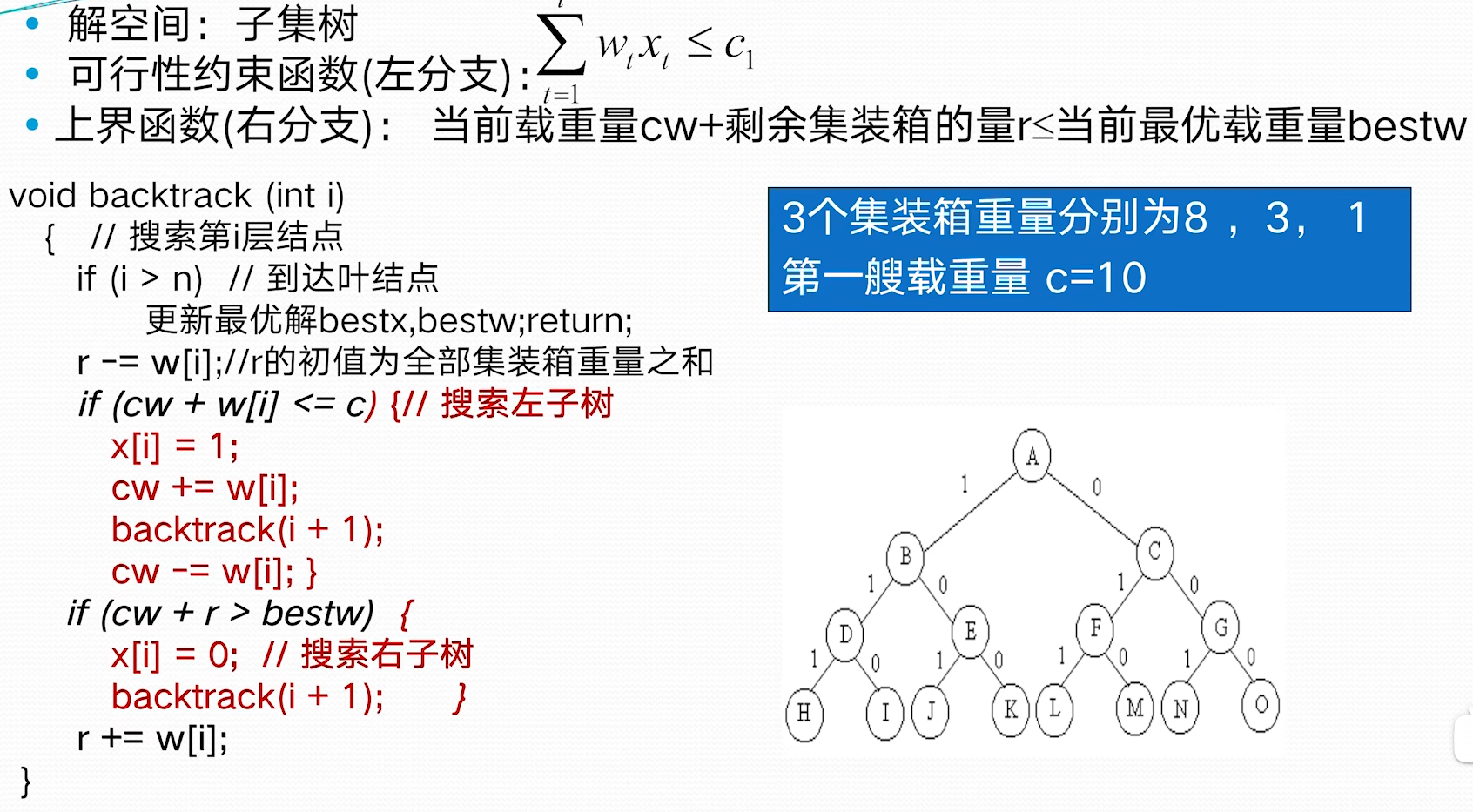 > 第一个 if 是到达叶子节点结束时,输出结果 > R 保存剩下没有判断的集装箱的重量和 > 第二个 if 搜索左子树,保证单前重量 cw 加上当前集装箱 $w[i]$ 不超过船的重量上限;递归搜索完,需要把当前重量恢复成没装这个集装箱的大小,方便后续搜索右分支(不装当前集装箱的情况) > 第三个 if 搜索右子树,保证剩余的集装箱的重量加上当前集装箱的重量大于 bestw,否则这里也没有最优解,没必要搜索了 > 最后退出这一节点,回到上一层,把剩余重量 r 还原 **时间复杂性** 使用回溯法解装载问题的时间复杂性是 $O(2^n)$。在某些情况下该算法优于动态规划算法 **回溯法如何计算其时间复杂性?** 1. 计算出解空间中除叶子层之外的节点总数 $f(n)$ 2. 每个非叶子即欸但扩展出其下一层的所有分支的时间复杂性 $g(n)$ 3. 复杂性为 $O(f(n)*g(n))$ 以最优装载问题为例,$f(n)=w^{n}-1,g(n)=O(1)$,因此其时间复杂性为 $O(2^n)$ 本章讨论的时间复杂性只有理论意义,没有实际意义,因为计算的是在没有任何剪枝的情况下的时间复杂性,实际上效率要好很多 **例子** 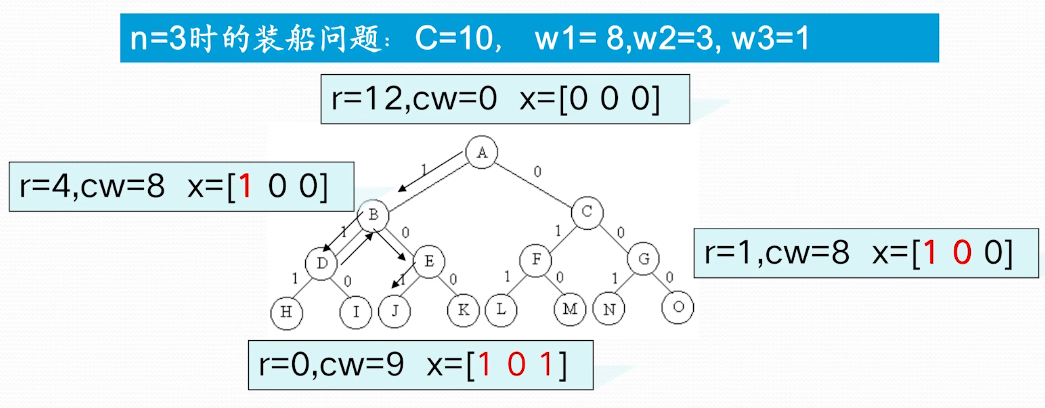 ## 3. N 皇后问题 **N 皇后问题** 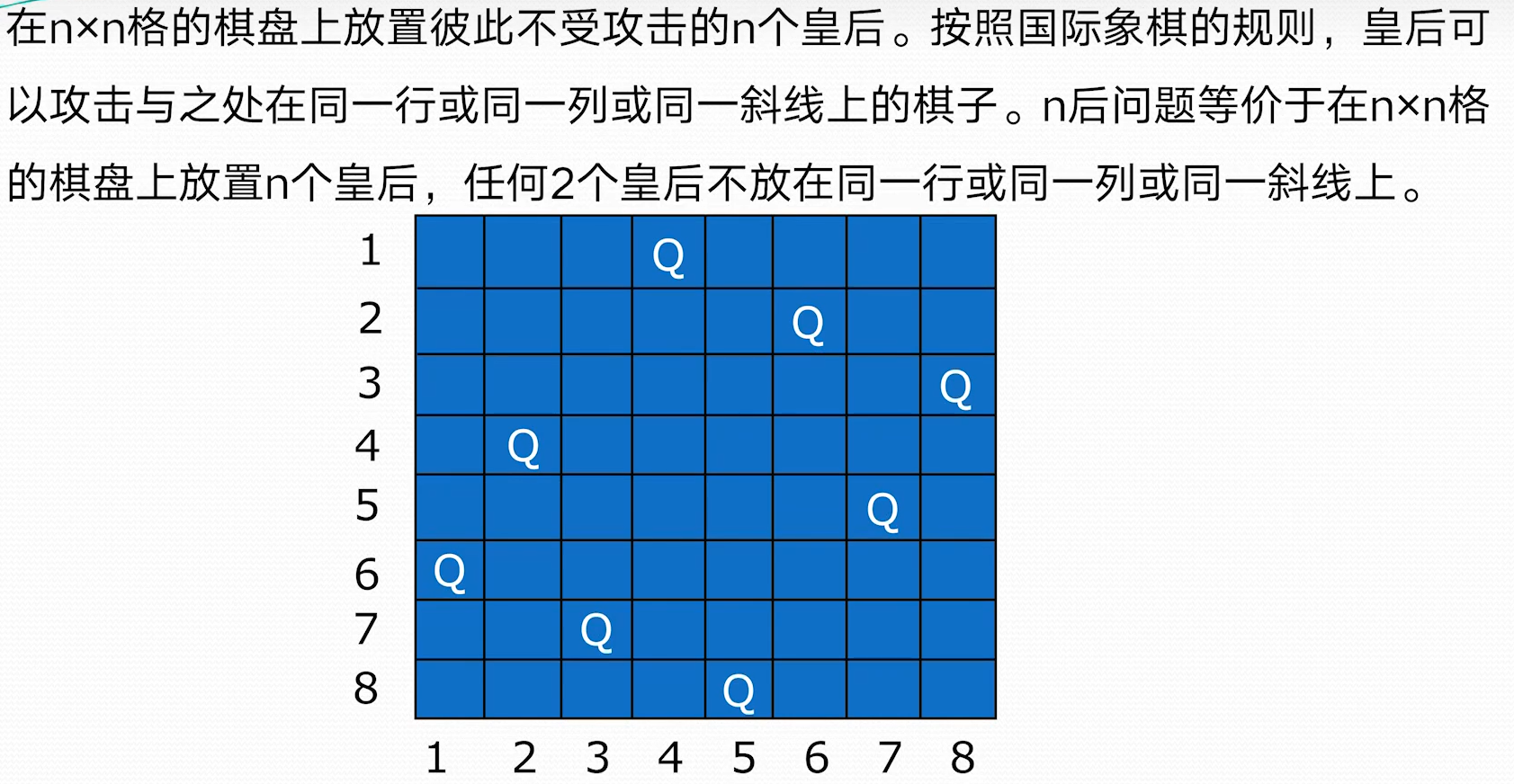 ## **第一种解空间树是 4 叉树** 每个皇后在一行上有四个可选位置(显约束:两个皇后不同行) 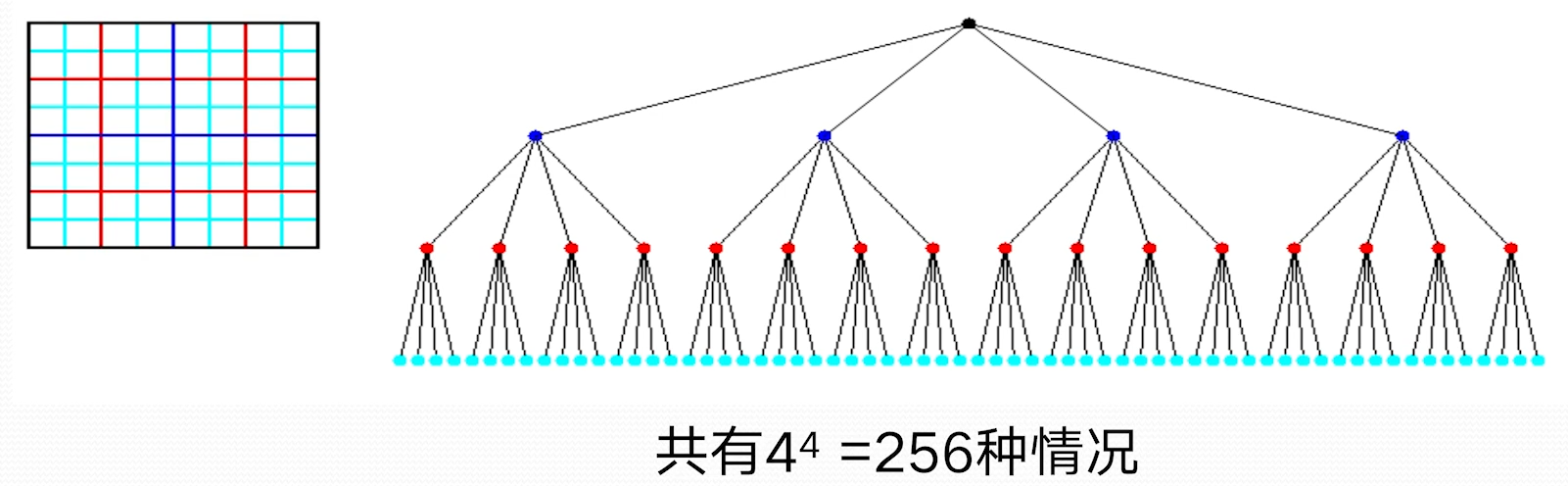 解向量:$x_1, x_2,...,x_n$,每一行一个皇后的位置 显约束:$x_i=1,2,...,n$ 任意两个皇后不同行 隐约束:1. 不同列:$x_i!=x_j$ 2. 不处于同一正/反对角线:$|i-j| \neq |x_i-x_j|$  > Palce 是判定隐约束的函数,包括判断新的皇后是否和之前的皇后同列或者同一斜线,都不在返回 true > > Backtrack 函数是回溯的函数 > 第一个 if 记录符合的答案个数 > 否则 for 循环遍历 n 个分支,即下一层的皇后可以选择的所有位置,然后判断是否符合隐条件,递归到下一行 ## **解空间树是排列树** 显约束:任意两个皇后不同行,不同列 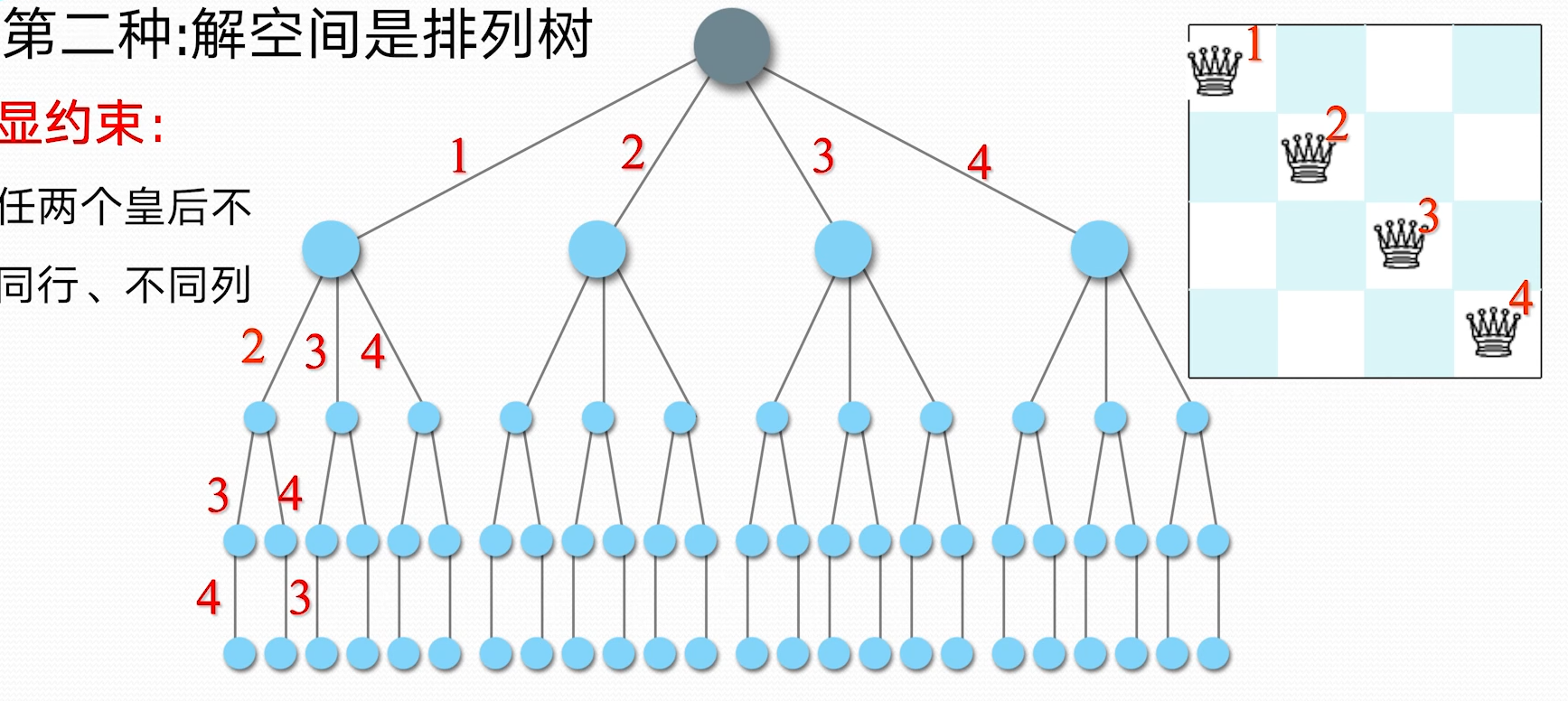 解向量:$x_1, x_2,...,x_n$,每一行一个皇后的位置 显约束:任意两皇后不同行、不同列。$x_{1},x_{2},\dots,x_{n}$ 是 1,2,...,n 排列 隐约束:不处于同一正/反对角线:$i-j\neq|x_{i}-x_{j}|$  > Place 函数是判别隐约束条件,当前皇后和前面所有皇后不再同一斜线 > Backtrack 函数使用排列树回溯算法,递归查找答案 ## 4. 0-1 背包问题算法 # 0-1 背包问题 0-1 背包问题的解是从 n 个物品中选出一定量的物品保证最终价值最大,它的解是所有物品的一个子集 解空间:子集树 可行性约束函数:$\sum_{i=1}^{n}w_{i}x_{i}\leq c_{1}$ 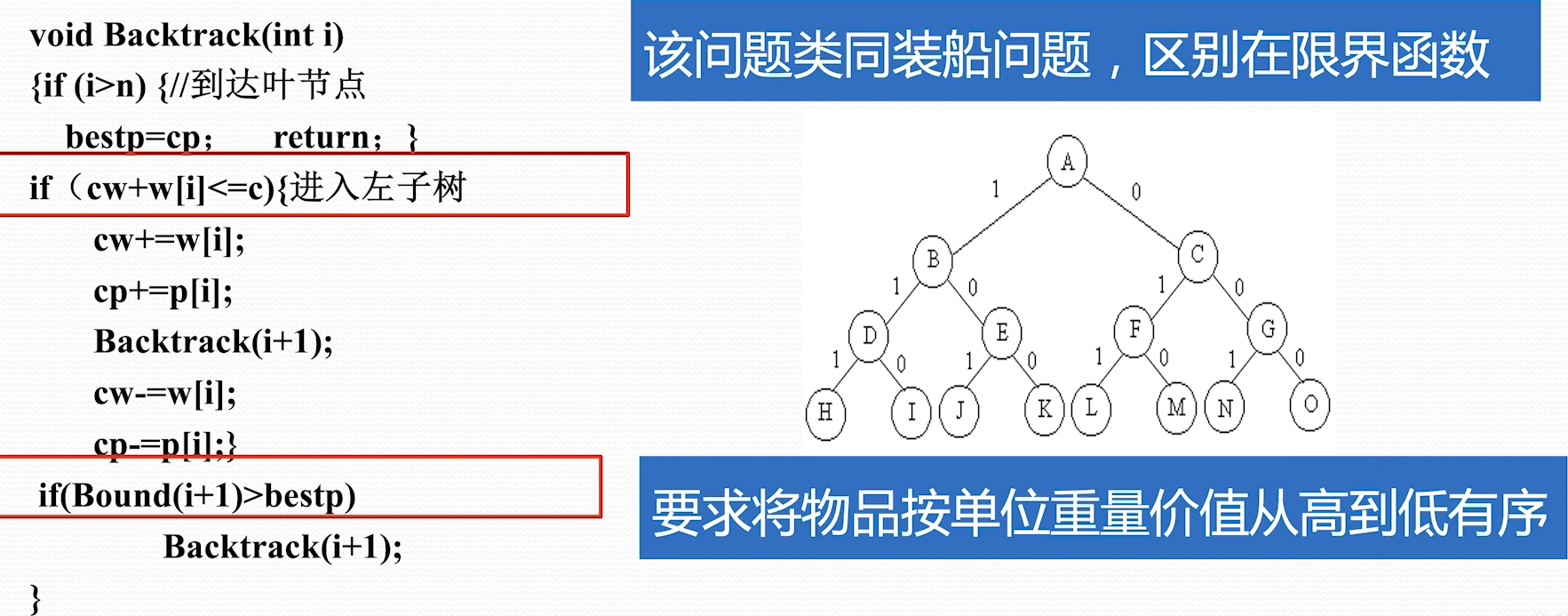 > 该问题和装载问题的区别在于限界函数,即对右分支进行剪枝的函数,在装载问题中,右分支是不选择当前物品,如果不选择当前物品,剩下的货箱加上当前装的货箱数量小于最优解,那右分支就没必要在遍历了 > > 同样对于 0-1 背包问题,我们需要限界函数能够判断右分支(不选择当前物品)能否获得更高的价值,否则就没必要遍历了 > 这是设计了一个 bound 函数,对剩下的物品进行贪心选择(需要提前按照单位重量价值比排列好数据),来判断时候需要对右分支进行搜索 > > 左子树 if:cw 是当前重量,cp 是当前价值;然后递归到下一个物品选择;回溯 cw 和 cp,准备进入右子树(不选择当前物品) > 右子树 if: 先判断剩余的物品(i+1 及其之后的物品)能够装进背包的价值是否超过 bestp;然后递归 **限界函数**  > 贪心计算从 i 物品开始及其之后的所有物品的最大价值 > Cleft 是背包剩余的空间;b 是总价值 > While 循环结束有两种情况,一个是物品全装进去了;一种是背包满了,还剩一个小空间塞不进去了 > 背包满了,还需要把最后一个物品切出一小部分塞到背包中 (对应最后 if),这样估计出价值的边界 ## 5. 图的 m 着色问题 # 图的 m 着色问题  > 把涂色表示成图的结构,表示他们的相邻关系 解向量: $(x_{1},x_{2},\dots,x_{n})$ 表示顶点 i 所着颜色 可行性约束函数:顶点 i 与已着色的相邻点颜色不重复  > 第一个 if 保存答案个数 > 接下来 for 循环,遍历当前顶点可选择的颜色,ok 函数来判断当前颜色 i 是否可选,可选递归为下一个节点选择颜色 > > Ok 函数检查选择的颜色是否可选,通过遍历已经涂好颜色的(j<k)且和 k 顶点相连($a[k][j]==1$)的顶点的颜色($x[j]==x[k]$),是否和 k 节点相同来判断 # 第 6 章 ## 1. 回溯法与分支限界法的区别 1. 求解目标:回溯法的求解目标是找出解空间树中满足约束条件的所有解(或一个最优解),而分支限界法的求解目标则是找出满足约束条就爱能的一个解(或最优解) 2. 搜索方式不同:回溯法以*深度优先*的方式搜索解空间树,而分支限界法则以*广度优先*或以*最小耗费优先*的方式搜索解空间树 ## 2. 队列式的分支限界法与优先队列式的分支限界法的区别有哪些 1. 队列式(FIFO)分支限界法 按照队列先进先出(FIFO)原则选择下一个节点作为拓展节点 2. 优先队列式分支限界法 按照优先队列中规定的优先级选取优先级最高的节点称为当前扩展节点 ## 3. 装载问题算法与实例 **装载问题**  ### 队列式分支界定法  > 这个-1 标记是可变位置的,初始,第一个位置是-1,当检测到-1 时,把-1 挪到尾部 **代码**  > 先看 EnQueue 函数,它负责队列入队,同时会对叶子节点进行判定,保存最优解 bestw,且叶节点不加入队列 > > 左边 Ew 是当前节点重量; > While 循环判定左儿子节点,需要满足加上当前节点重量后,总重量少于上限 c > 右儿子节点不装当前节点,不会超过上限 c,直接入队 > 然后取下一个节点,判定是否是尾部标志-1,同时队列中是否还有剩余节点,有节点说明是分层标志,没有节点说明是结束标志 > 如果是分层标志,就再取下一个节点,得到下一层的第一个节点 > 如果是结束标志,直接返回最优值 ### 算法改进 (右子树加入剪枝条件) **上述算法,右子树没有剪枝,效率太差** > 右分支无脑拓展,分支太多,需要加上剪枝 策略:设 bestw 是当前最优解;ew 是当前拓展节点所对应的重量;r 是剩余集装箱的重量。则当 $ew+r\leq bestw$ 时,可将其右子树剪去 为确保右子树成功剪枝,算法每一次进入左子树的时候更新 best w 的值。不要等待 i=n 时才去更新 **代码**  > 左分支:加上了判定最优 bestw 的代码,add 只添加非叶子节点 > 右分支:需要判定当前重量和剩余重量的和是否大于 bestw,且是非叶子节点 ### 构造最优解  > 这个数据结构,构造了一个指向父节点的树,其中还加入判定当前节点是否是父节点的左子树的 LChild 标志,以及当前节点的重量,这样可以从叶子节点向上搜索最优解  > 循环回溯到最优解 ### 优先队列式分支界限法 用最大优先队列存储活节点表(大顶堆实现) 活结点 x 的优先解:**根到节点 x 的路径相应的载重量+剩余集装箱重量之和** 优先队列中优先级最大的活结点称为下一个拓展节点 <u>以节点 x 为根的子树中所有节点相应的路径的载重量不会超过 x 的优先级 叶节点所对应的载重量与其优先级相同</u> 因此:<u>一但优先队列中有一个叶节点成为当前拓展节点,则可以断言该叶节点所对应的解即为最优解。此时可终止算法</u> **注意:算法中叶子节点要进队列** **模拟优先队列** 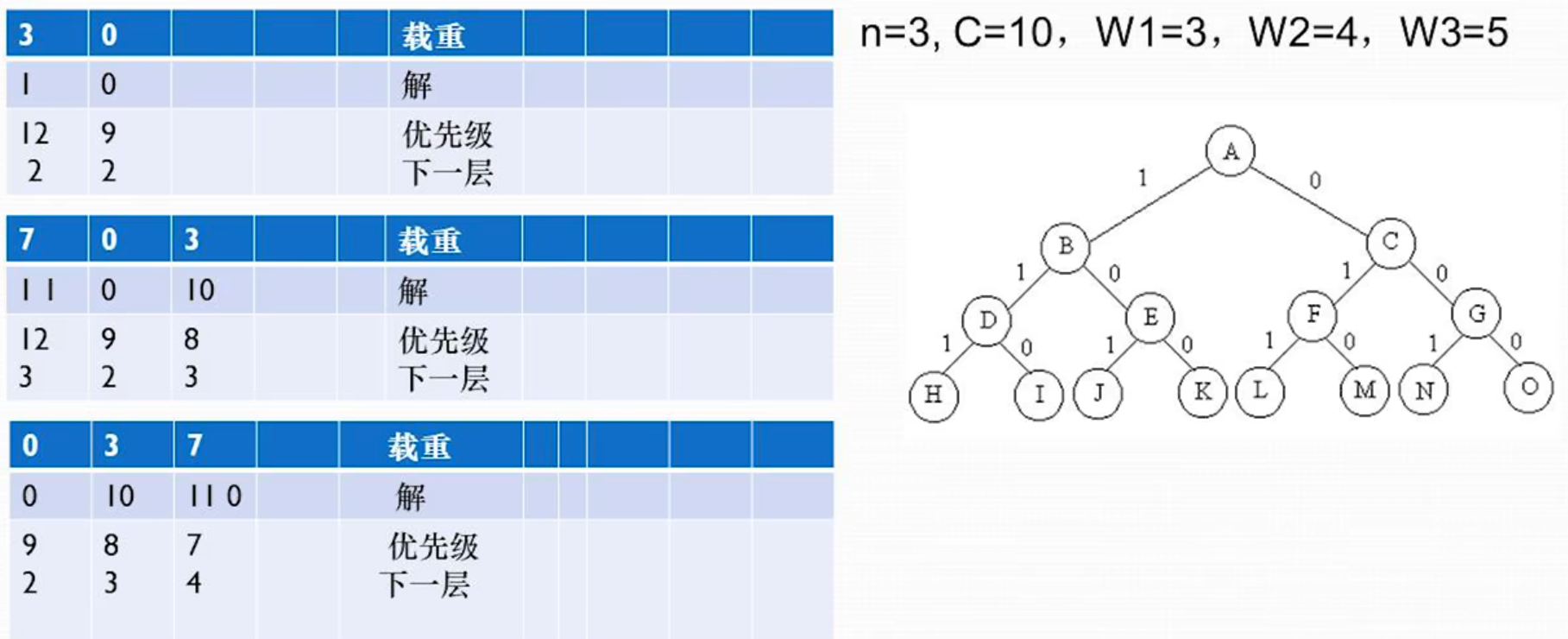 > 第一个分支重量是 3 或 0(w 1);优先级左分支 3+4+5=12,右分支 4+5=9;下一层都是第二层 > > BC 两个节点先展开 B 节点,展开是 7,3,优先级分别是 7+5=12,3+5=8;对应第二个表 > > C 节点展开 4,0,优先级是 9,5;优先级 5 已经小于当前层最优解 7,这个节点被优化掉了;只剩下 7,0,3,对应 DFE 节点;对应第 3 个表 > > 依次向下拓展,每次从优先最高的节点拓展一次;判断优先级是否小于当前最优值,小于就不拓展这个子节点; 直到优先级最高的节点是最下层(上图第四层)的节点,这个节点就是最优值 ## 4. 布线问题实例 ### 布线问题 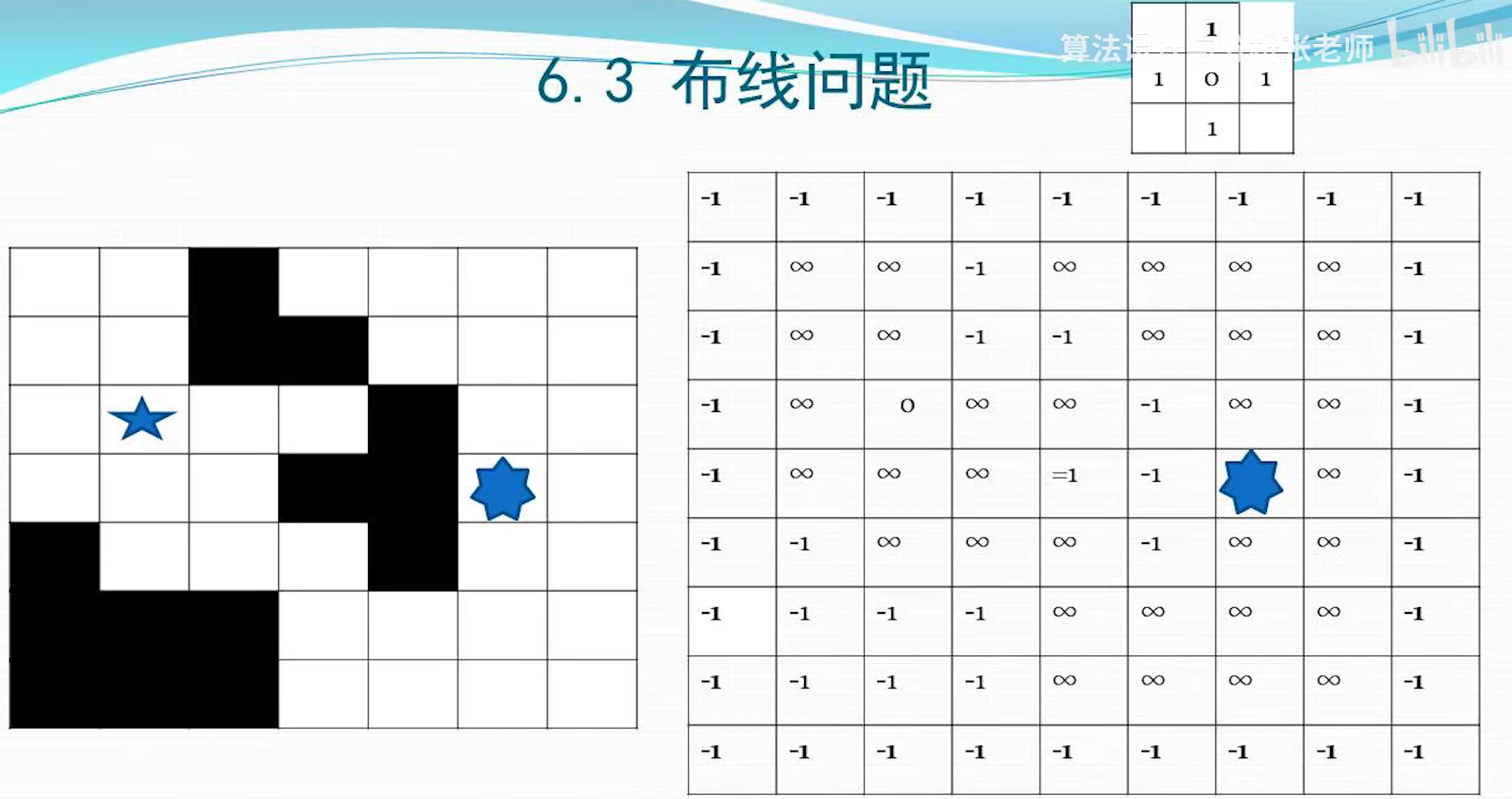 > 就是广度搜索求两点之间最短长度 > -1 代表墙 > 初始所有可走的位置数值是无穷大 ### 算法思想: 队列式分支限界法 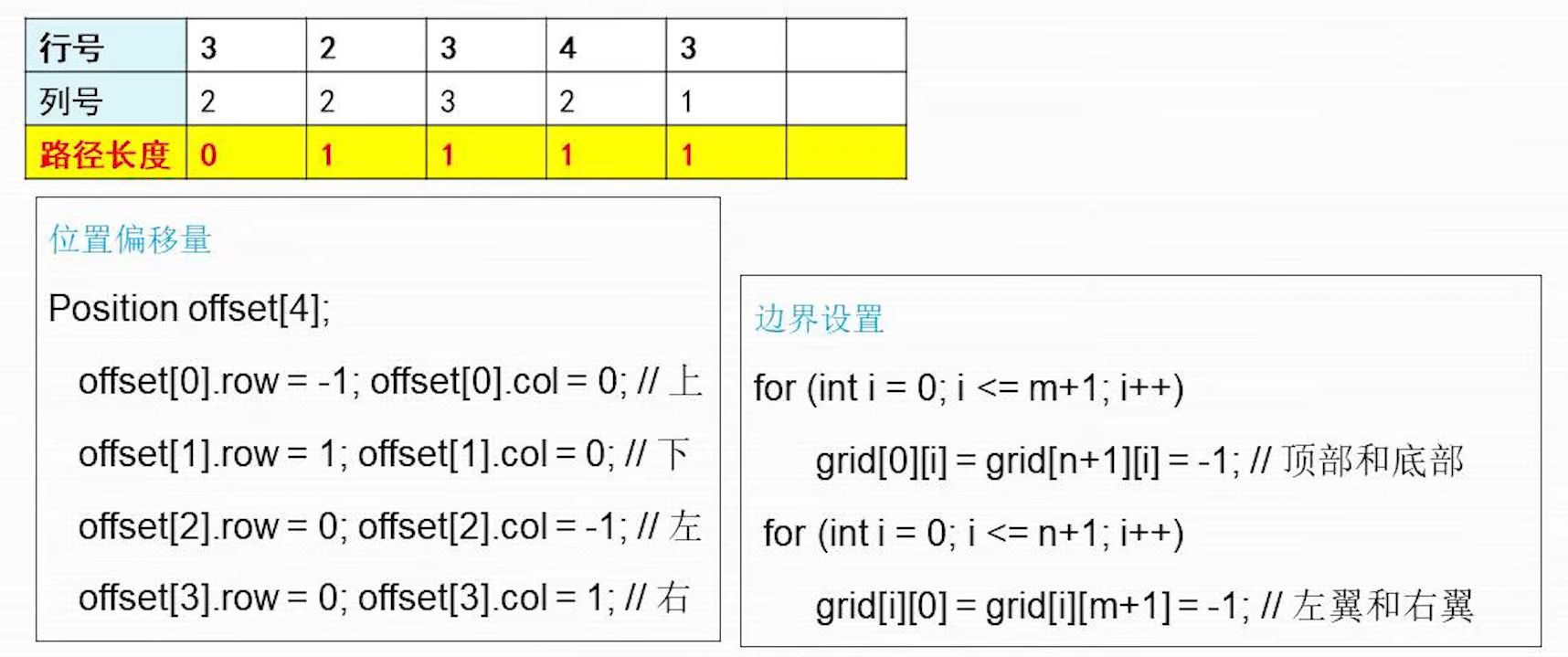 > 从出发节点开始,向上下左右四个方向拓展 > 拓展时的剪枝策略,拓展过去的最短路径长度必须小于之前得到的路径长度,才能进行拓展(所有可走的初始位置都是无穷大,保证第一次能走过去) > > 剪枝策略:新拓展的该位置路径长度小于该位置已经记录的值 **代码**  > For 循环遍历所有邻居(上下左右); nbr. Row, nbr. Row 是邻居的位置 > 接下来 if 判断从当前位置走过去的距离和原本邻居位置的数值,哪一个更小,决定是否添加新的节点到队列中 ## 5. 0-1 背包问题算法 **算法思想** 先进行预处理:==将各物品依其重量价值从大到小排列== 优先队列的优先解:==已装物品价值+后面物品装满剩余容量的价值== 算法:现价查当前扩展节点的左儿子即欸但。如果该==左儿子==节点是可行节点,则将他加入活结点优先队列中,如优于当前最优值,则更新当前最优值。当前拓展节点的==右儿子==节点一定是可行节点,仅当右儿子满足上界约束时(优先级大于当前最优值)才将它加入活结点优先队列。从优先队列中取下一个活结点称为拓展节点,继续拓展 当叶子节点为拓展节点 (当前优先级最高) 时,即为问题最优解, 算法结束 **上界函数 bound(int i)的计算**  > 把剩余空间和剩余物品,按照最高重量价值的顺序依次放入背包中,最后剩下的空间,把下一个物品切割塞进去,得到剩余背包空间的价值上限,作为剪枝的估计 **优先队列中节点包含的信息** - 当前背包价值、重量 - 节点的优先级(价值上界) - 左孩子标志 - 父节点地址 - 本节点对应的下一个要装入背包的物品编号 **代码** 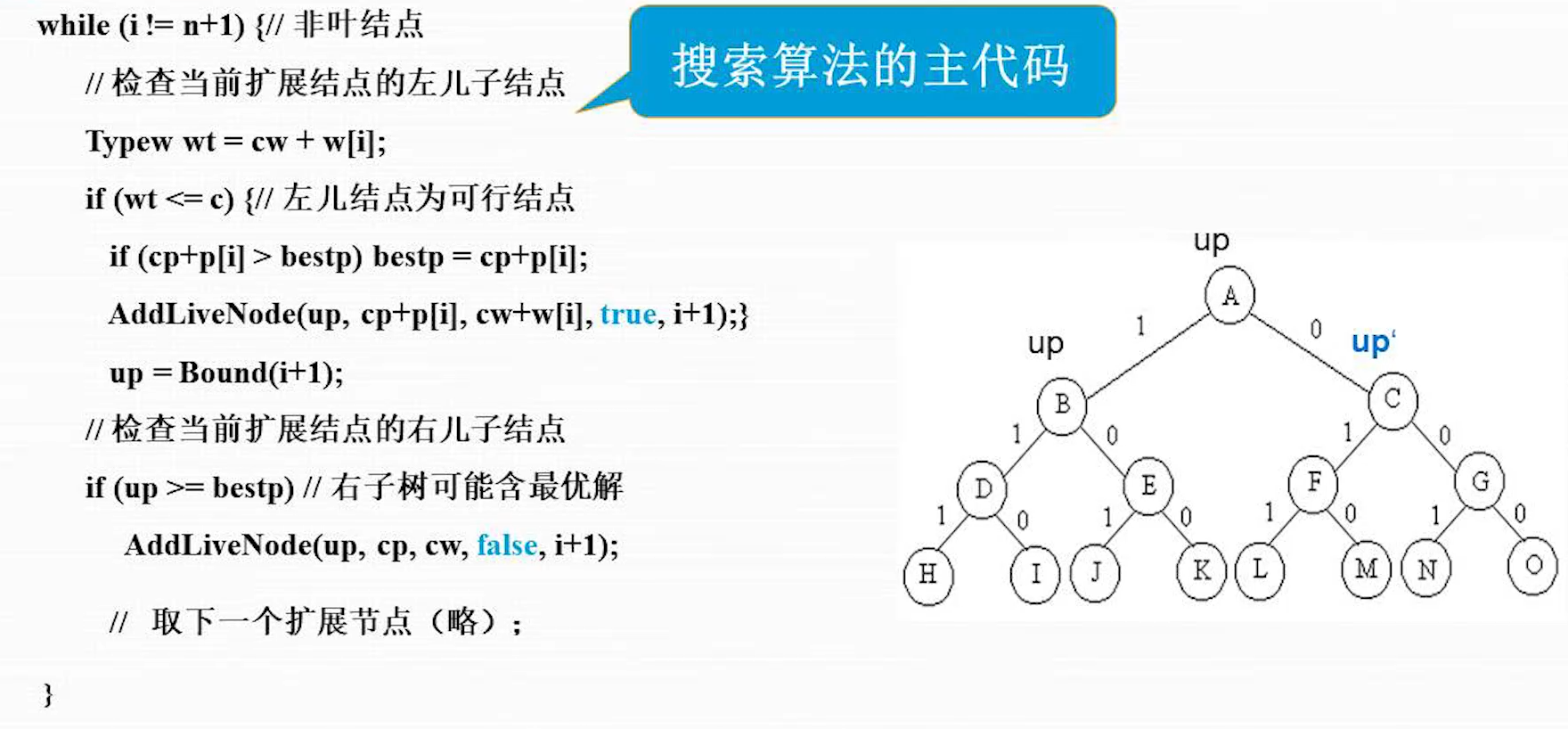 > 这个要拓展到叶子节点:第 n 层;循环在 n+1 时停止 > wt 是加上当前节点的总重量,重量小于背包容量 c,可以进入左儿子节点;先比较加上当前物品的总价值是否更优,再添加子节点到队列,其中 up 是优先级,$cp+p[i]$ 是总价值,$cw+w[i]$ 是总重量,true 是左儿子节点标记,i+1 是下一个物品是第 i+1 个物品 > 然后计算 i+1 优先级就是右子树的优先级 (价值上界),因为右子树不选择当前物品,优先级会变化;左子树优先级和父节点一致,因为选择了当前物品,价值上界没有变化 > 右子树的优先级(价值上界)必须高于最优解,才可能有更优解 **思考** 如果优先级设定为当前位置的背包内物品机制,算法是否可以在一个叶子节点成为拓展节点时算法结束? 不可以,当前背包价值,不能反应后续背包的价值上限 ## 6. 旅行售货员问题实例  **解空间树是排列树** 1. 指定一个城市作为起点 2. 把 n-1 层看作叶子节点 因为路线是环路,初始城市是哪一个都可以  ## 算法描述 算法开始时创建一个最小堆,用于表示活结点优先队列 堆中每个活结点的优先级为:**cc+lcost**。Cc 是出发城市到当前城市的路程,lcost 是当前顶点(当前城市)最小出边+剩余顶点(城市)最小出边和(禁忌除外) 每次从优先队列中去除一个活结点成为拓展节点(s 层节点), **当 s=n-2 时**,拓展出的节点是排列树中某个叶子节点的父节点 该叶节点相应一条可行贿赂且费用小于当前最优解 bestc,则将该节点插入到优先队列中,否则舍去该节点 **当 s<n-2 时**,产生当前拓展即欸但的所有儿子即欸但。可计算可行儿子节点的优先解 cc+lcost 及相关信息。当 cc+lcost<bestc 时,将这个可行儿子节点插入到活结点优先队列中 该拓展过程一直持续到优先队列中取出的活结点是一个叶子节点为止 **最小出边(禁忌除外)的解释** 对于刚拓展处得顶点,其前已经选的所有顶点是禁忌的(不能选)|就是不能走回头路 对于未拓展出的顶点,其前已经选择(顶点 1 除外)的顶点是禁忌的 | 就是说在选择下一个顶点的时候不能选已经走过的,1 顶点能选,是最后构成环路的时候选 > 其实就是在表格里面,已经到达的城市的列是不能选的,但是第一个城市是例外;可以如果到第一个城市是最短距离,是可以选的 **算法演示** LB (下限)=当前路径长度+当前拓展出的顶点及其后顶点*可选*最小出边和 > 这个是计算出当前节点的优先级,根据当前节点计算出粗略的整个路径的长度下限,下限越低,优先级越高;这个下限是不准确的,一个粗略值  > 具体计算, > 1. 第一个城市是例外,直接计算每一行最小值就可以 > 2. 两个城市的时候因为需要避免回头路问题,第一列要屏蔽掉,然后屏蔽掉选择的路线的行和列;如 1,3 ,屏蔽掉第一列,第一行,第三列,从剩余的数据选择每一行最小值,再加上已经走过的 1,3 代表的数值,组成 LB > 3. 其余情况,去掉所有路线所在的行和列(不需要去掉第一列),从剩余的数据中找每一行最小值,再和已走过的距离加到起来;如 1,3,2, 屏蔽掉第第 1,3 行,第 2,3 列,剩余每行最小值:第二行的 7,第四行的 2,第五行 4,和为 13,加上 1 到 3 和 3 到 2 的距离 4+5+13=22 >