模仿学习是存在一个专家模型,可以提供一系列的状态动作对,模仿者需要利用专家数据来训练,训练出一个接近专家的策略
模仿学习分类
- 行为克隆(behavior cloning,BC)
- 逆强化学习(inverse RL)
- 生成对抗模仿学习(generative adversarial imitation learning GAIL)
其中逆强化学习计算复杂度较高,实际应用价值第,这里不介绍
行为克隆
行为克隆直接使用监督学习,将专家数据中 中的 看作样本输入, 看作标签,学习目标为
其中 是庄家的数据集, 对应监督学习框架下的损失函数,若动作是离散的,损失函数可以通过最大似然估计得到;若是连续的,可以使均方误差函数
当训练数据量比较大的时候,BC 能够学习到不错的策略,如 AlphaGo。通常是跟据专家数据快速达到一个较高水平,为接下来的强化学习创造一个高起点
BC 也存在很大的局限性,当数据量较小是很明显。BC 训练只是拿一小部分数据进行学习,而强化学习是序冠决策据问题,BC 学习到的策略不可能死完全最优,只要有一点偏差,就会导致下一次的状态是专家数据中没见过的,导致下一状态偏离专家策略遇到的数据分布,在真实环境下不能取得比较好的效果,称为复合误差
生成对抗模仿学习-GAIL
生成对抗模仿学习是基于生成对抗网络的模仿学习,他解释了生成对抗网络的本质就是模仿学习。
GAIL 是模仿了专家策略的占用度量 ,即尽量使得策略在环境中的所有章台动作对 的占用度量 和专家策略的占用度量一致。为了达成这个目标,需要和环境交互,收集下一个状态的信息,并进一步做出动作。这与 BC 不同,BC 不需要和环境交互。
GAIL 算法中有一个判别器和一个策略,策略 相当于生成对抗网络中的生成器,给定一个状态,策略会输出这个状态下应该采取的动作,判别器 将状态动作对 作为输入,输出一个 0 到 1 的实数,表示认为改状态动作对 是来自智能体策略而非专家的概率
判别器 的目标是尽量将庄家数据的输出靠近 0,将模仿者策略的输出靠近 1,这样就可以两组数据分辨开来。于是判别器
其中, :是智能体策略的判别器的交叉熵项, 目标需要接近 1,让 变小 :是专家数据的判别器输出的交叉熵项, 目标需要接近 0,让 变小
这样,用模仿者在环境中采样到状态 , 并且采取动作 ,此时该状态动作对 (s, a) 会输入到判别器 中,输出 的值,然后*设置奖励 为
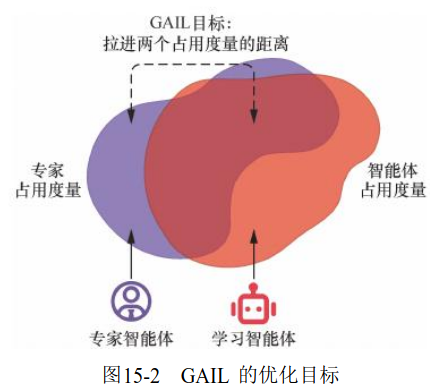
智能体策略可以使用任意强化学习算法,使用这些数据继续训练模仿者。最终在过程不断进行后,模仿者策略生成的数据分布将接近真实的组寒假数据分布,达到模仿学习的目标
GAIL 可以在少量专家数据的情况下,获得更好的效果