DDPG 和 TD 3 方法是针对连续动作空间的方法,使用链式求导更新网络参数。当动作是离散的或者策略本身是随机策略,这时候怎么办呢?
回顾
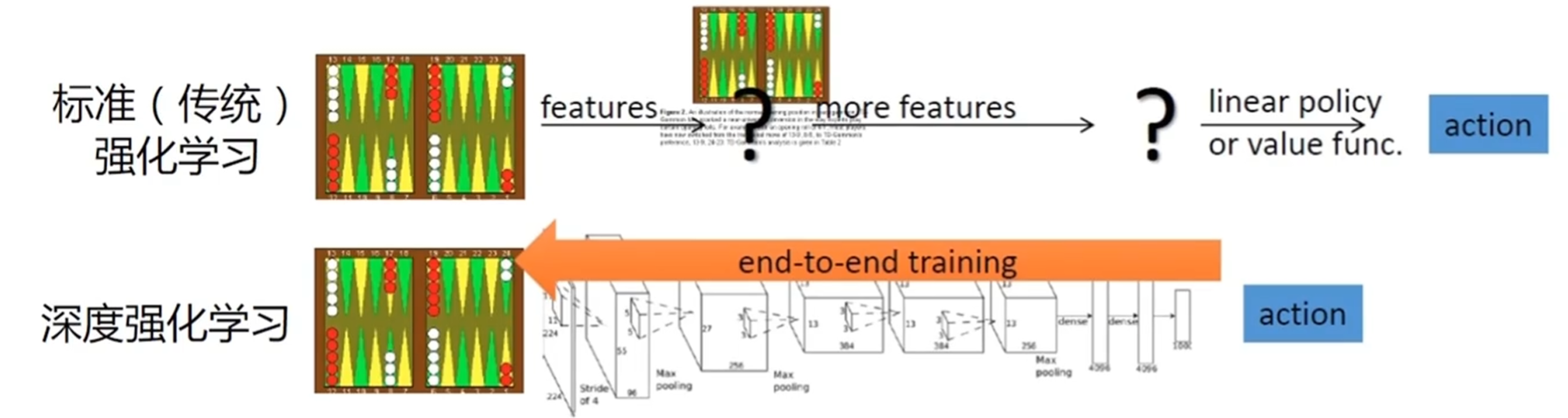
深度强化学习
- 直面理解:深度学习+强化学习
- 深度强化学习使强化学习算法能够以端到端的方式解决复杂问题
- 真正让强化学习有能力完成实际决策任务
- 比强化学习和深度学习都更加难以驯化
- 基于价值函数的深度强化学习
- DQN:一次输入多个行动 Q 值输出、目标网络、随机采样经验
- Double DQN:解耦合行动选择和价值估计、解决 DQN 过高估计问题
- Dueling DQN:精细捕捉价值和行动的细微关系、多种 advantage 函数建模
深度强化学习的分类
-
基于价值的方法
- 深度 Q 网络及其扩展
-
基于确定性策略的方法
- 确定性策略梯度(DPG),DDPG,TD 3
-
基于随机策略的方法
- 使用神经网络的策略梯度,自然策略梯度,信任区域策略优化(TRPO),近段策略优化(PPO),A 3 C
基于神经网络的策略梯度
复习:策略梯度定理

策略网络的梯度
对于随机策略,一般采样到每一个行动的概率由 Softmax 实现
- 其中 是对状态-行动对的打分函数。由 参数化,这可以通过一个神经网络实现
其 log 形式的梯度为
可以看成当前动作的梯度减去当前状态下策略梯度的期望
策略网络的梯度为
策略梯度和 Q 学习的对比

Q 学习|基于价值学习可以更快的拟合,基于策略梯度更难学习,但是最终效果会优于 Q 学习
复习 Actor-Critic

复习 A 2 C: Actor-Critic
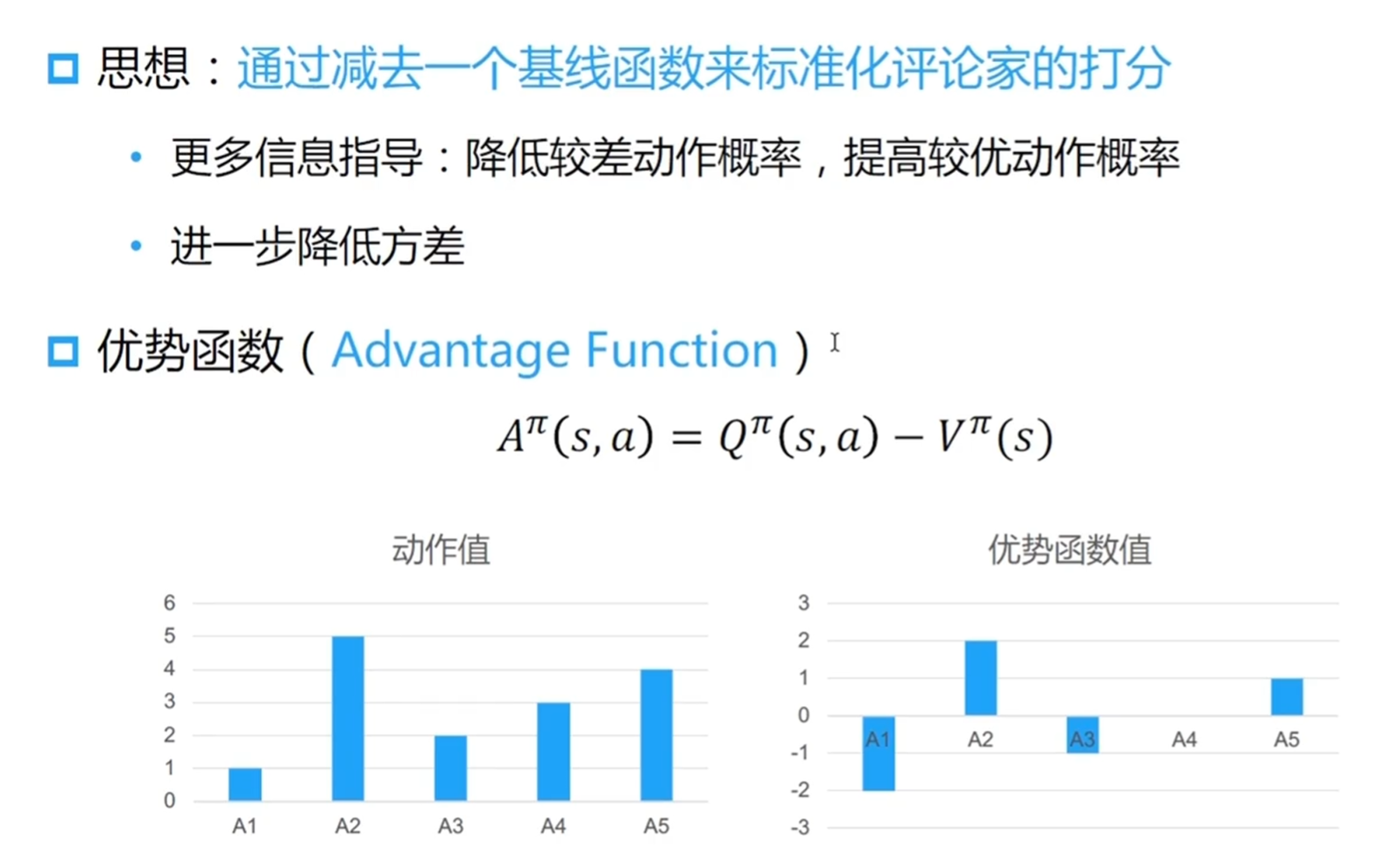
使用 A 函数和 V 价值函数可以避免拟合 Q 函数,V 价值函数更加易于学习,以为输入只有状态 S,数值稳定性更好
A 3 C:异步 A 2 C 方法
A 3 C 代表了异步优势动作评价(Asynchronous Advantage Actor Critic)
- 异步(Asynchronous):因为算法设计并行执行一组环境
- 优势(Advantage):策略更新使用优势函数
- 动作评价(Actor Critic):使用 AC 方法,设计一个在学得的状态值函数帮助下进行更新的策略
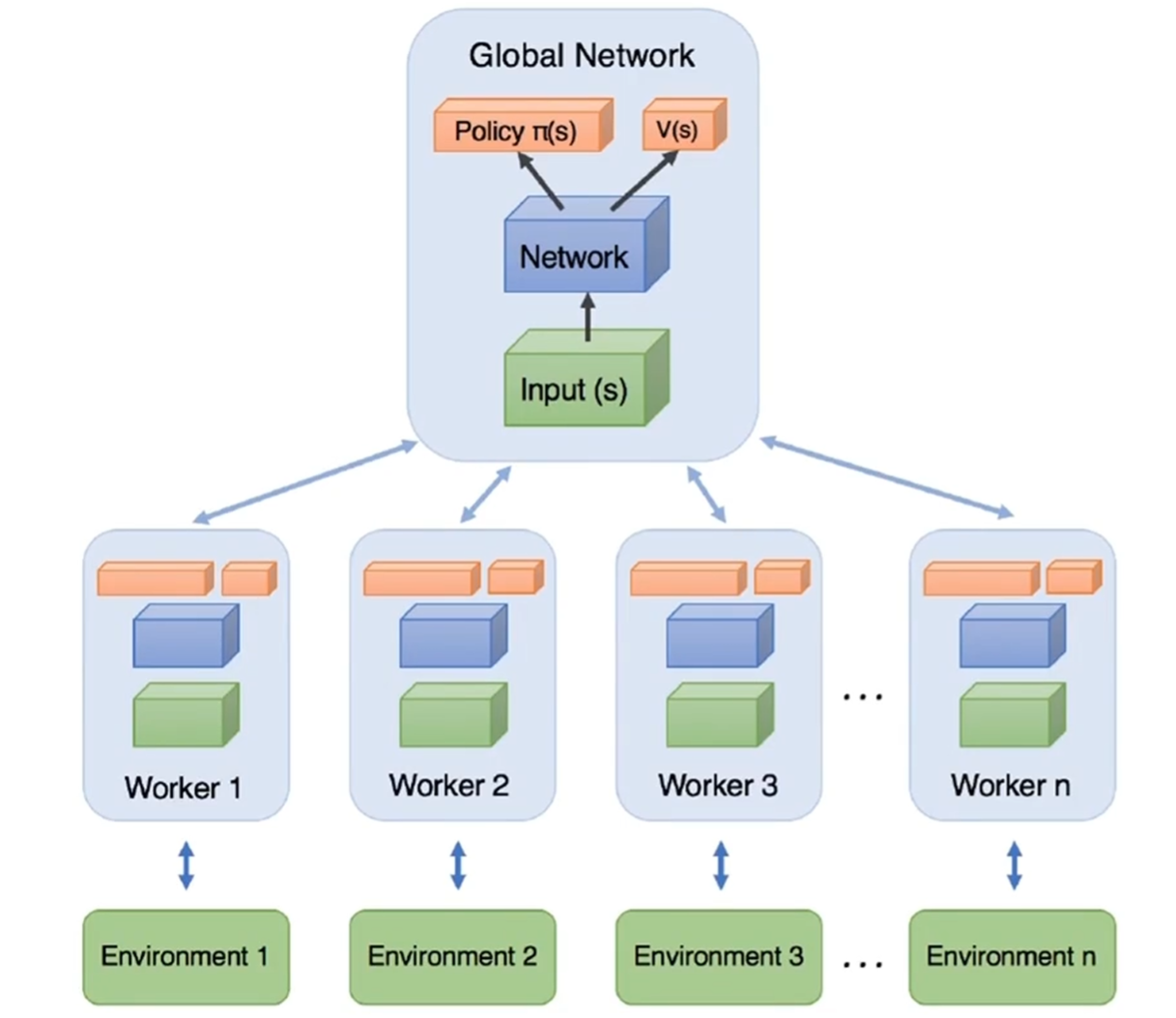
A 3 C 对比实验
A 3 C 是并行训练的方法,后来发展出了深度学习的并行框架 参数服务器
确定性梯度策略
当策略做策略梯度的时候,策略如果是神经网络,会存在什么问题
策略梯度算法回顾

策略梯度的缺点
适合的步长在策略梯度中难以确定
- 采集到的数据的分布会随着策略的更新而变化
- 较差的步长产生的影响大
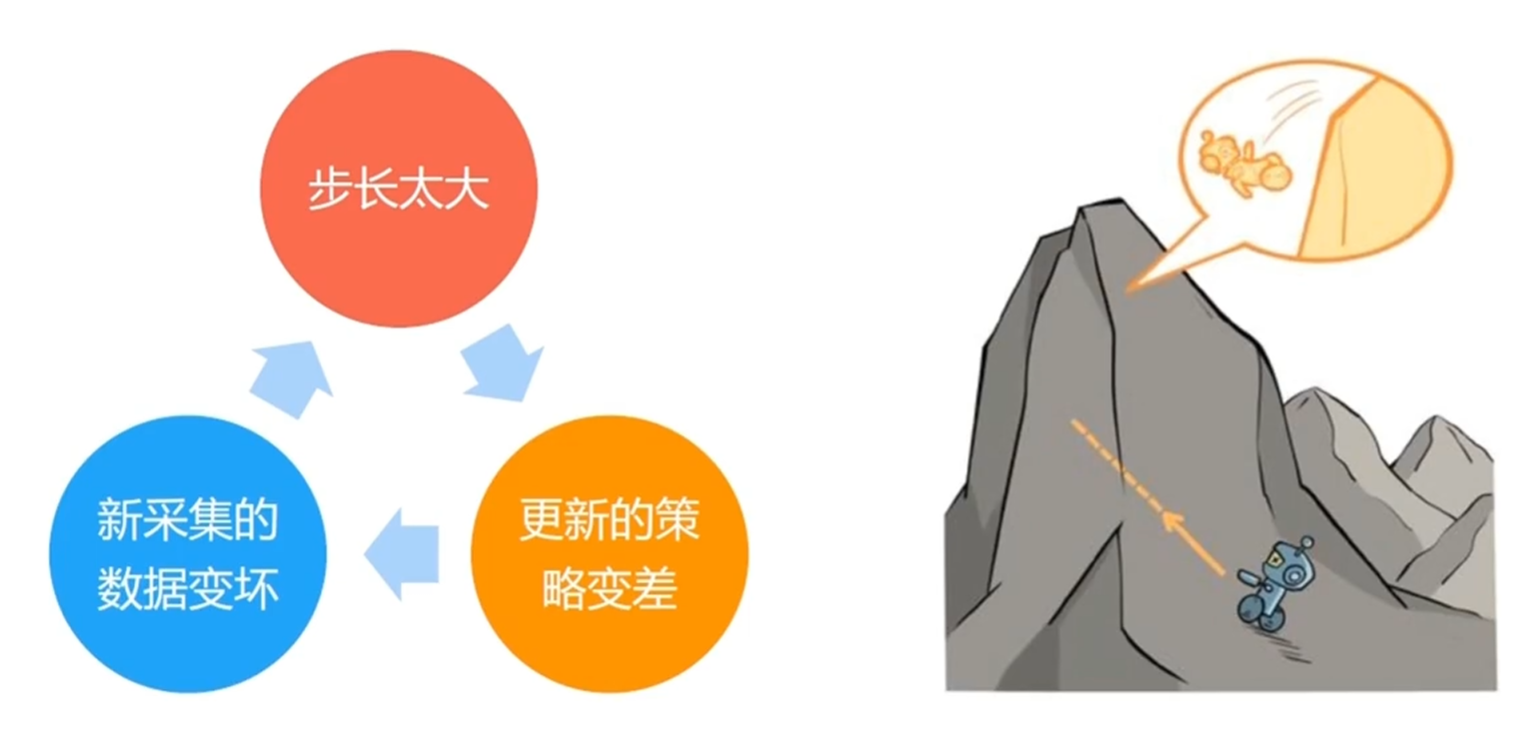
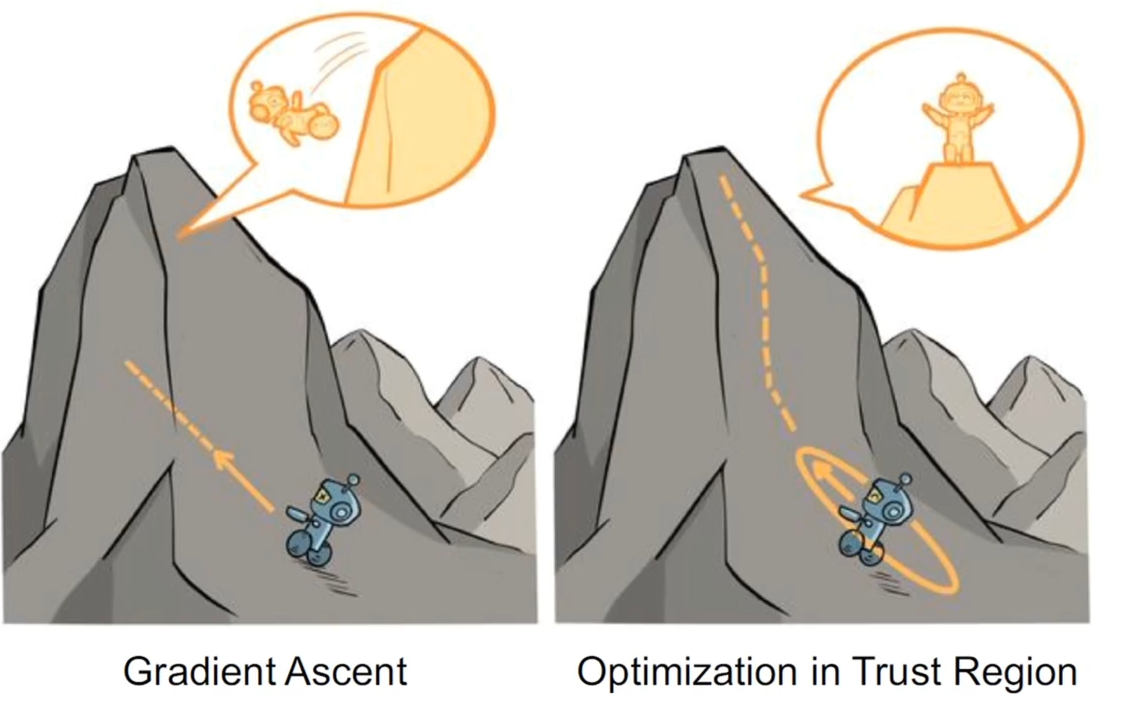
问题在于,这种更新方式不能提前感知当前更新的方向是不是悬崖,按照策略梯度的固定步长可能会踏入到一个悬崖中,当进入悬崖之后,后续学习会在悬崖下采集数据,更差的数据导致学习变的更加低效,TROP 用来解决这个问题
TROP
策略梯度的优化目标
优化目标的两种形式
- 第一种:
- 因为
- 所以优化目标的第二种形式是:
第 1 种方式中的 Q 使用后续多条走 k 步的轨迹的期望来表示值函数
相关定义: :轨迹 :初始状态 : 时刻的状态,动作和奖励 :使用的策略 :表示策略使用的参数 和 :策略 下的 Q 值与状态值函数
优化目标的优化量

是新的网络的参数,是我们希望学习的方向的参数。以上是当前网络和网络最终的参数之间的误差|损失差
因此 一开始是未知的,所以我们也没有办法来采样它的数据轨迹,这时候为我们进行一步近似,使用 采样,在使用重要性采样(这里近似的方法是强化学习的思想)
使用重要性采样
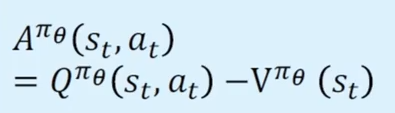
状态 S 依然使用 来采样,动作使用重要性采样 上式把轨迹转换成当前状态和后续所有动作的期望
忽略状态分布的差异
我们默认使用当前的 来采样,而不是最终的 ,这里进行了近似
当策略更新前后的变化较小时,可以令
- 假设使用确定性策略,当 的概率小于 时
- 或者假设使用随机策略,当 的概率小于 时
最后一步近似, 这里证明了==当两个 的差距不是很大的时候,他们的误差是可以被确定限制在一定的范围之内==
这样状态 s 的采样也使用 采样来近似
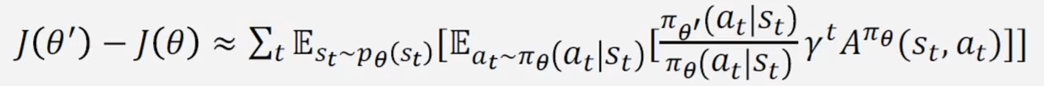
这里的重要性采样,实际上不能真正的计算,因为 未知,但是我们要知道进行这个操作。
约束策略的变化
使用 KL 散度约束策略更新的幅度
代表数据缓冲池里面的数据, 是当前学习的参数, 越大越好,说明学习到了更多 散度是衡量两个分布的相似程度: 两个分布差距越大,值越大
这里限制两个策略,防止差距过大,差距过大需要更加谨慎 实际使用中,在 TRPO 是把这个限制条件作为惩罚项 ,这样直接梯度更新就可以
KL 散度的约束条件,是保证两个策略不要差距太大,这样可以更好的进行忽略状态分布的近似,保证能够近似,以为散度约束的前后策略相似度要很高
TRPO 原理
通过计算当前位置的时候会考虑向海森阵一样的, 一个具体的周围的曲率. 考虑到曲率之后,曲率越大,说明特别容易踏空,周围的曲面非常扭曲,此时的梯度步长需要小一点|谨慎一点,防止踏空; 如果周围曲率很小,是平路, 步长大一点也没事
策略改进的单调性保证
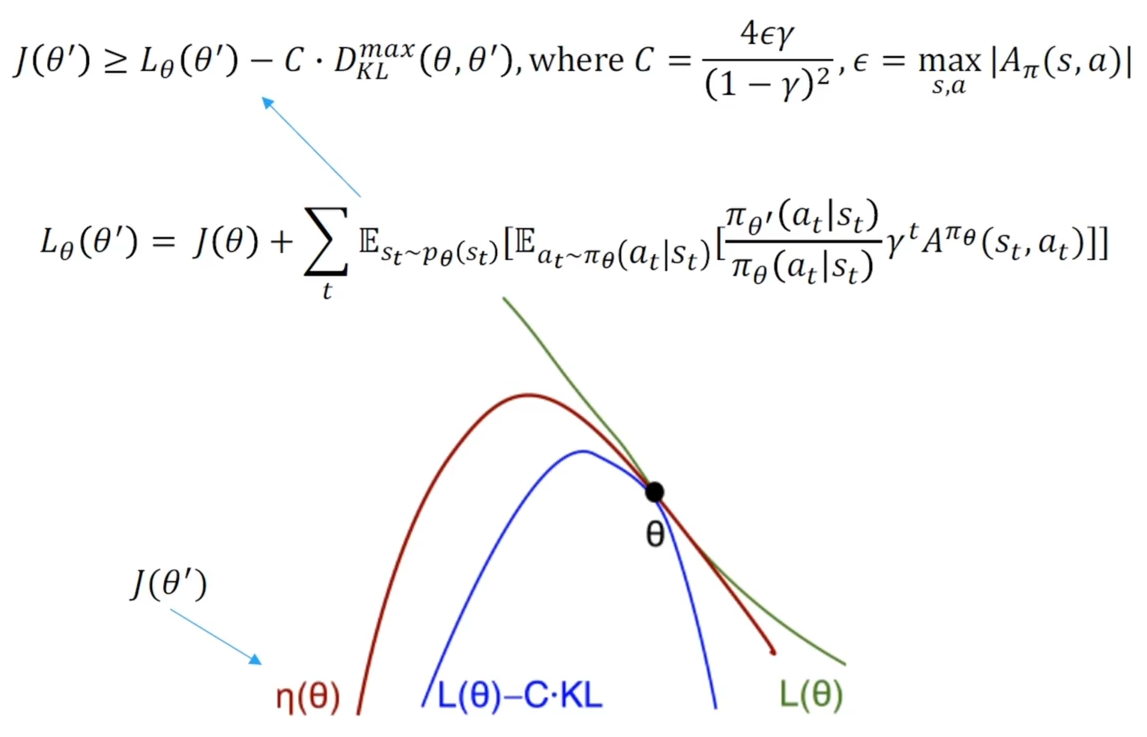
是当前状态下周围最大的散度 首先 是设定了一个下界,随着学习的进行,散度惩罚会越来越小,这个下界会逐渐接近 ,同时梯度会向上移动,更接近最优位置
实验结果
训练曲线
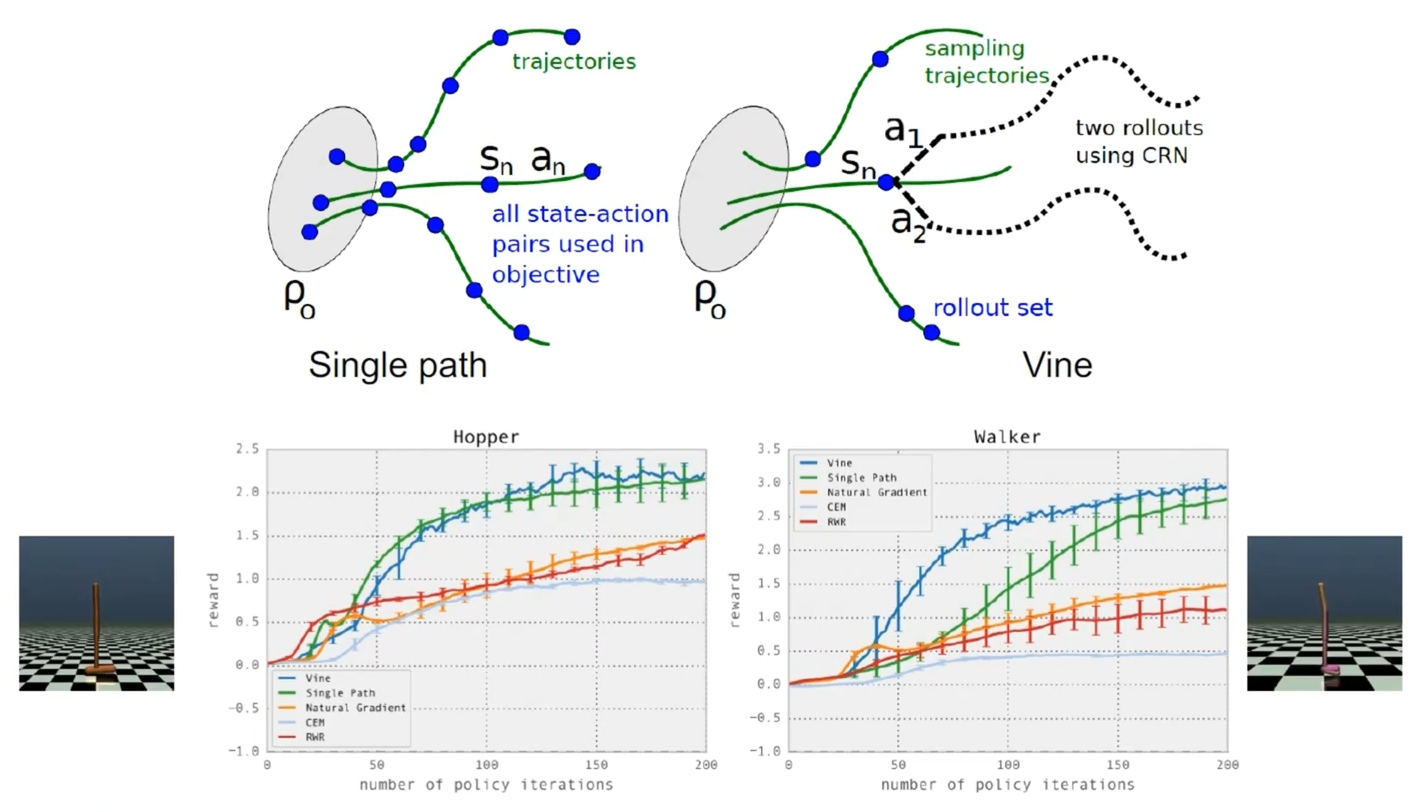
Trick:在一个节点 roll out 采样多个轨迹
结果比较
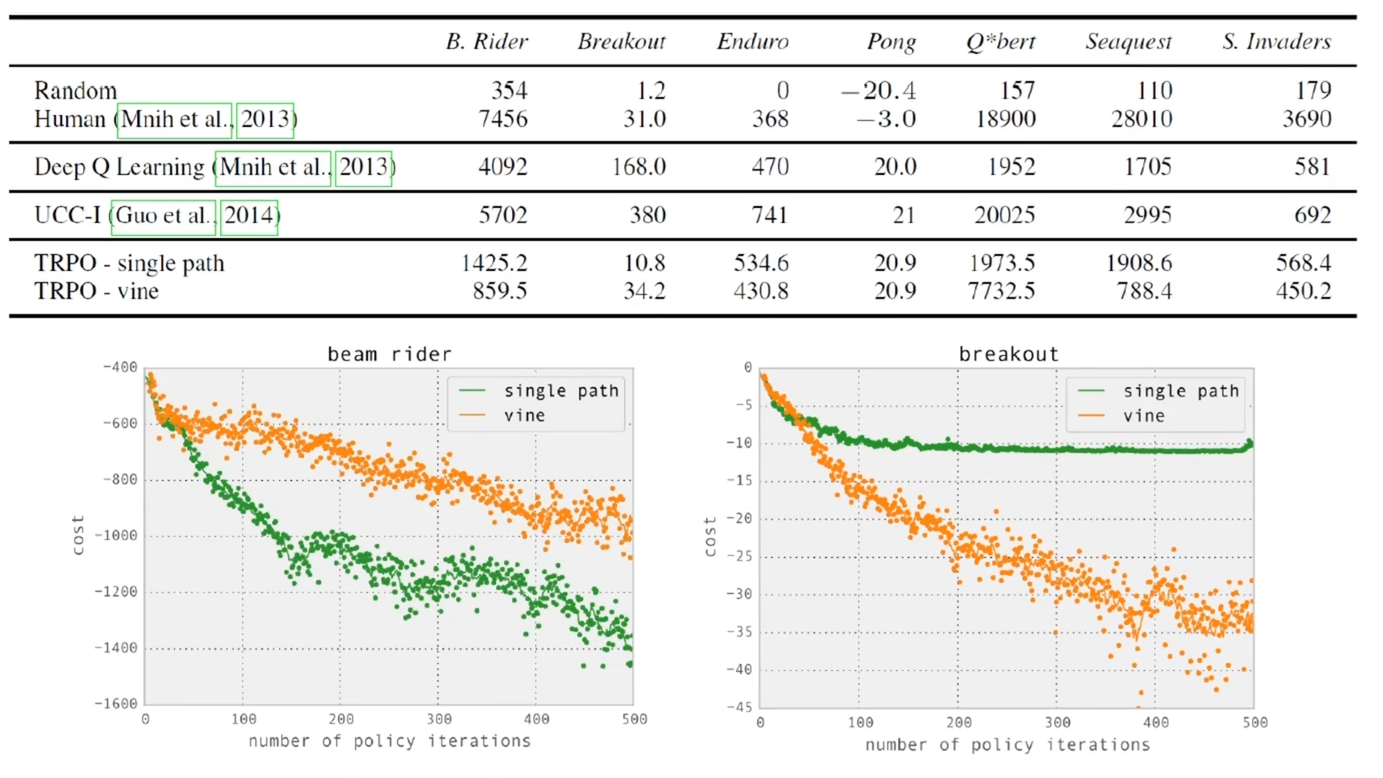
TROP 解决的一个核心问题,策略一旦被更新,效果可能会适得其反(即不小心走进悬崖的情况),无法确定步长大小
PPO-Proximal Policy Optimization
近端策略优化
回顾TRPO
TRPO 使用 KL 散度约束策略更新的幅度
- 使用 constraint violate as penaly(把限制条件|限制冲突作为惩罚项)
1. 优化上式,更新 $\theta^\prime$
2. 更新 $\lambda\leftarrow \lambda+\alpha(D_{KL}(\pi_{\theta^\prime}(a_{t}|s_{t})||\pi_{\theta}(a_{t}||s_{t})-\epsilon)$
TRPO 的不足
- 重要性比例带来的大方差
- 求解约束优化问题的困难
更新 的式子取了 max 操作,保证两个分布之间的最大的散度小于
重要性采样的相乘的方式会带来更大的方差 求解约束需要单独计算非常麻烦,原版的计算算法中使用泰勒展开, 然后用共轭梯度的方法。后面对他进行了优化
PPO 在 TRPO 基础上的改进
1 . 截断式优化目标

首先原本的 的估计就是不准确的,且重要性采样会带来方差,这两个数据本来就不准确,不如强行限制重要性采样的缩放数值,出让一定的偏差|bias 来减小方差|vanriance,这样做一个权衡 这样 可以被限制更大大的数值
2 . GAE-Generalized Advantage Estimation
优势函数 选用多步时序差分
- 每次迭代中,并行 N 个 actor 收集 T 步经验数据
- 计算每步的 和 ,后称 mini_batch
- 更新参数 ,并更新
3. 自适应的 KL 惩罚项参数
动态调整 方法
- 计算 KL 值 A) 如果 ,更新 B) 如果 ,更新
这里是计算的当前的散度,和之前的散度相比,如果散度已经是原来的 2/3,那么 也要缩小(惩罚变小,别变得更加松散);同样散度变大了, 也要变大(惩罚加大,变得更加谨慎)
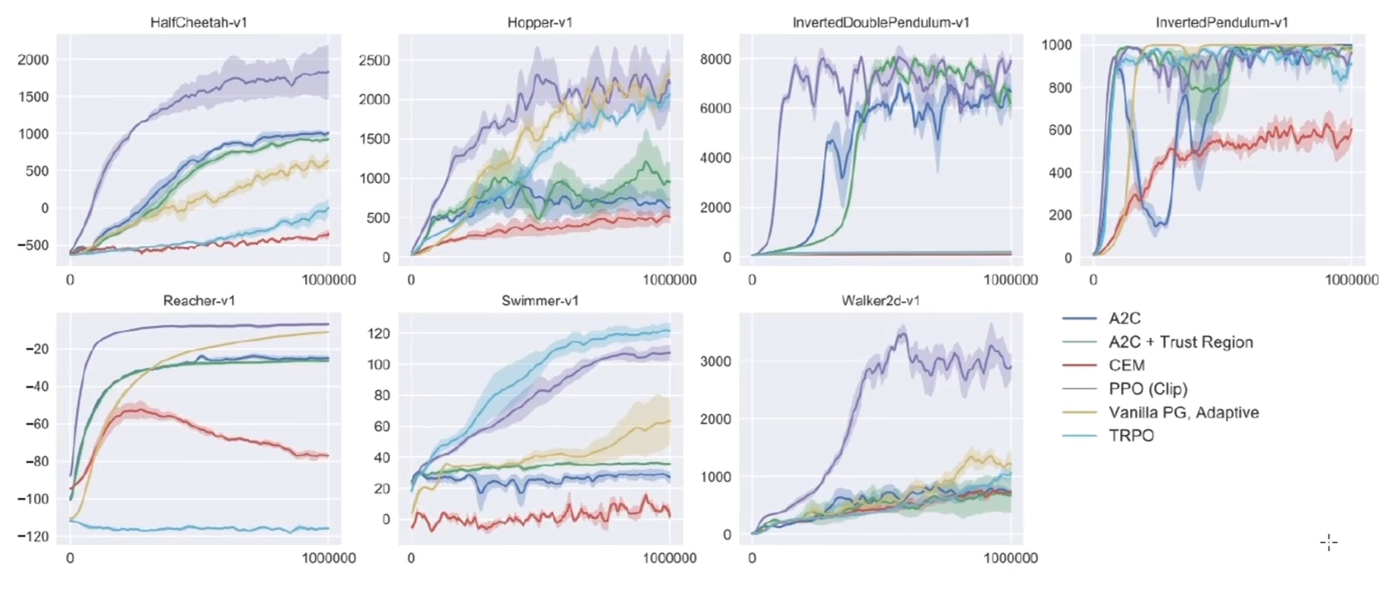
PPO 实验对比
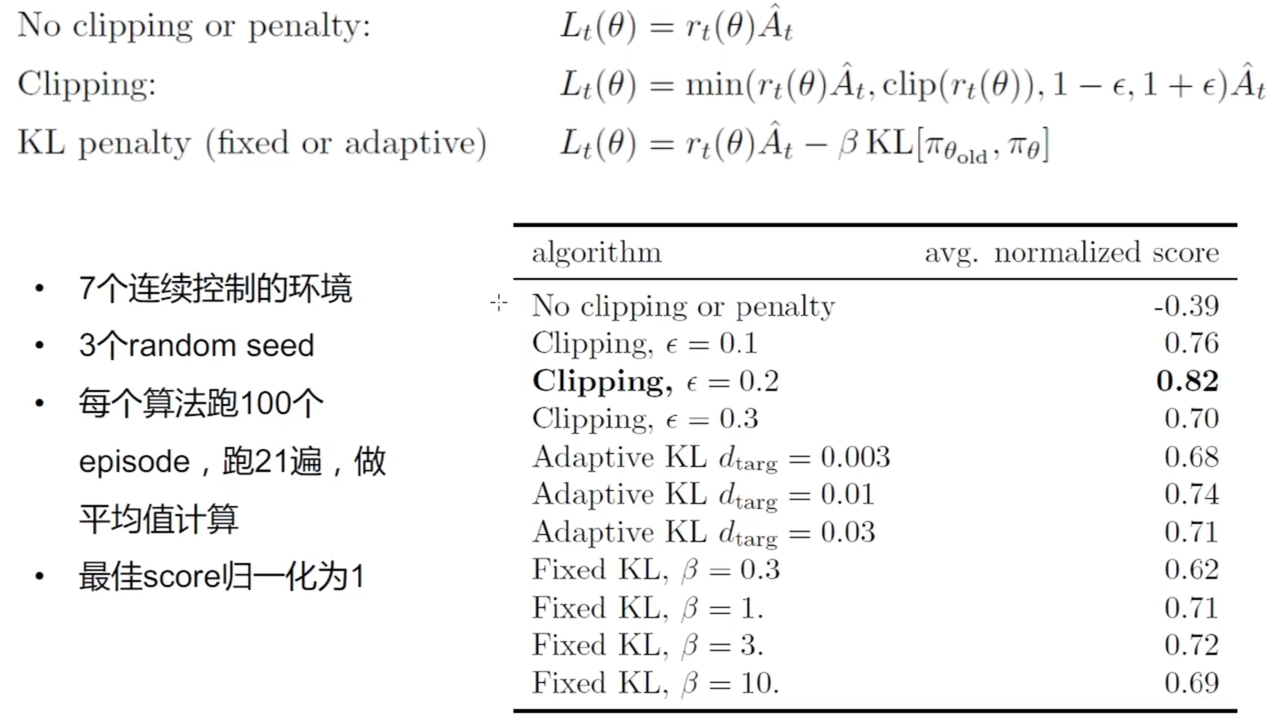
- 在 MuJoCo 实验环境中的对比结果(训练 100 万步)
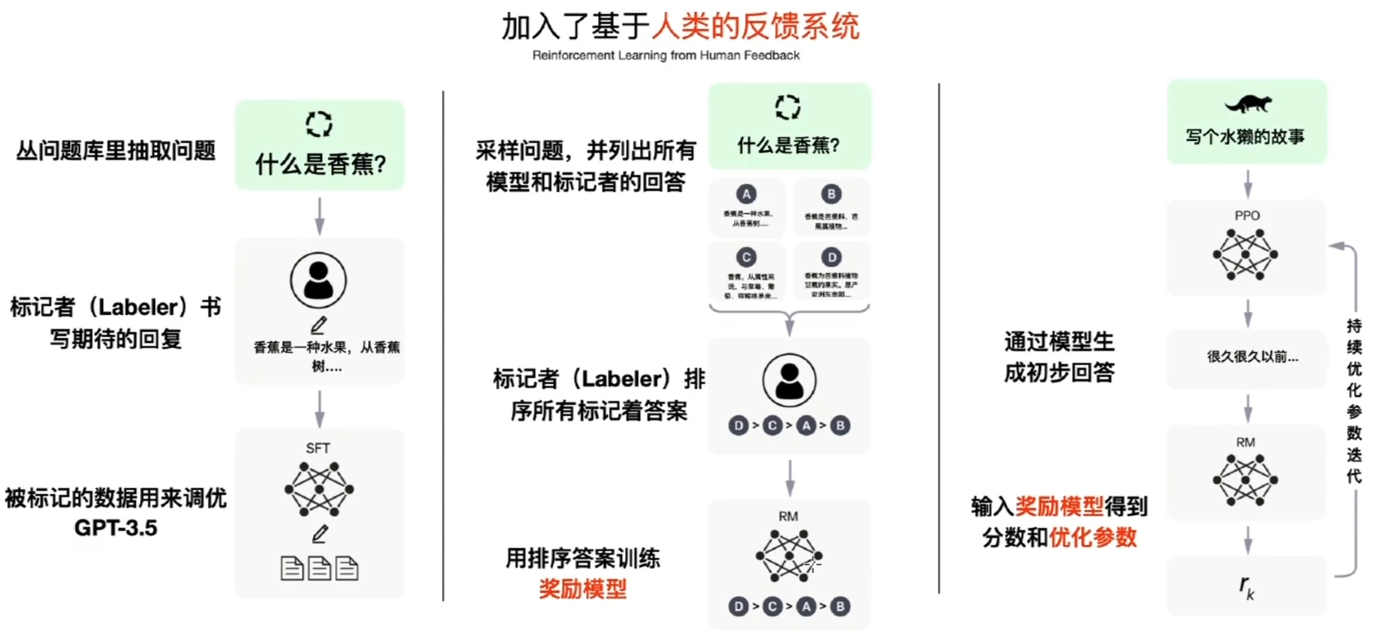
PPO 在ChatGPT 中的使用
总结深度策略梯度方法
- 相比价值函数学习最小化 TD 误差的目标,策略梯度方法直接优化策略价值的目标更加贴合强化学习本质的目标
- 分布式的 actor-critic 算法能够充分利用多核 CPU 资源采样环境的经验数据,利用 GPU 资源异步的更新网络,这有效提升了 DRL 的训练效率
- 基于神经网络的策略在优化时容易以为异步走的太大而变得很差,进而下一轮产色行很低质量的经验数据,进一步无法学习好
- Trust Region 一类方法限制一步更新前后策略的差距(用 KL 散度),进而对策略价值做稳步提升
- PPO 在TRPO 的基础上进一步通过限制重要性采样的 range,构建优化目标的下界,进一步保证优化的稳定效果,是目前最常用的策略梯度算法