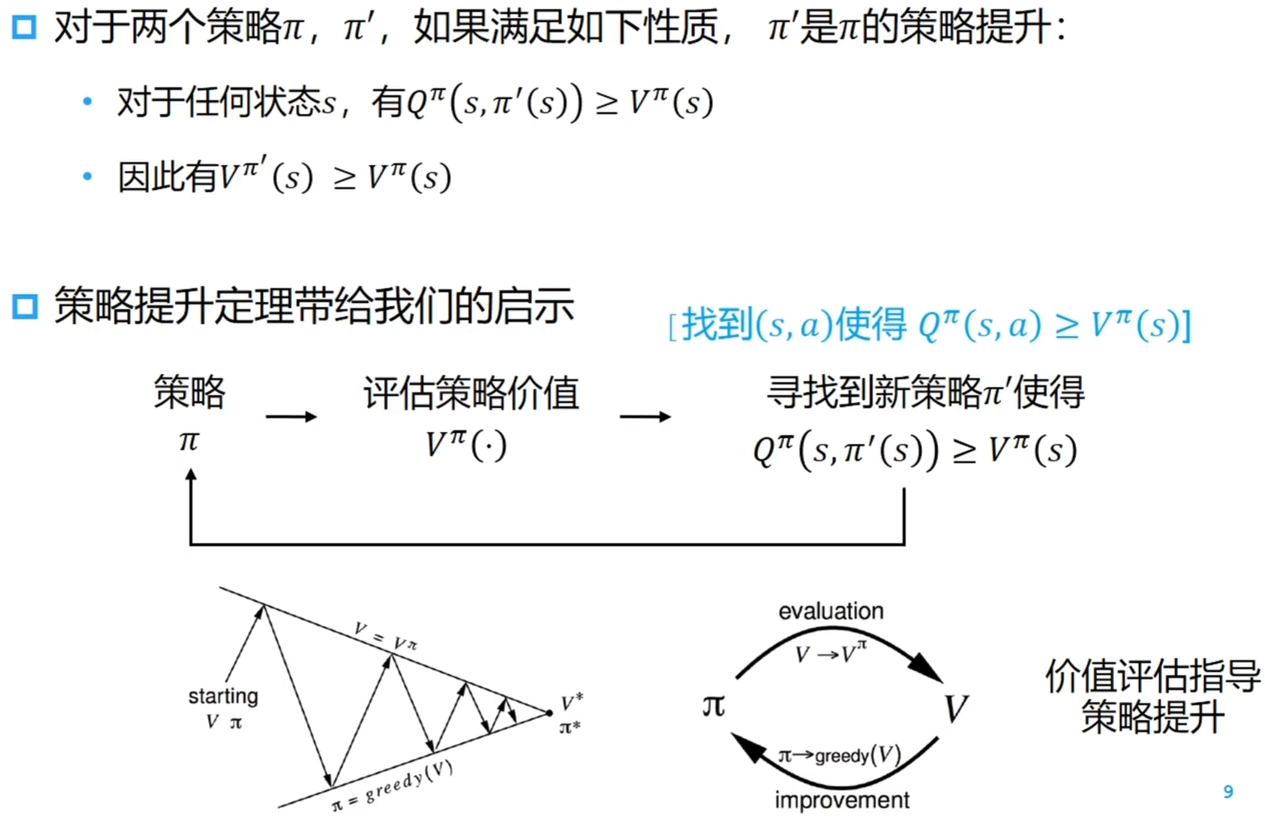
回顾

策略值函数估计

策略提升

策略提升定理


规划与学习:入门算法和介绍
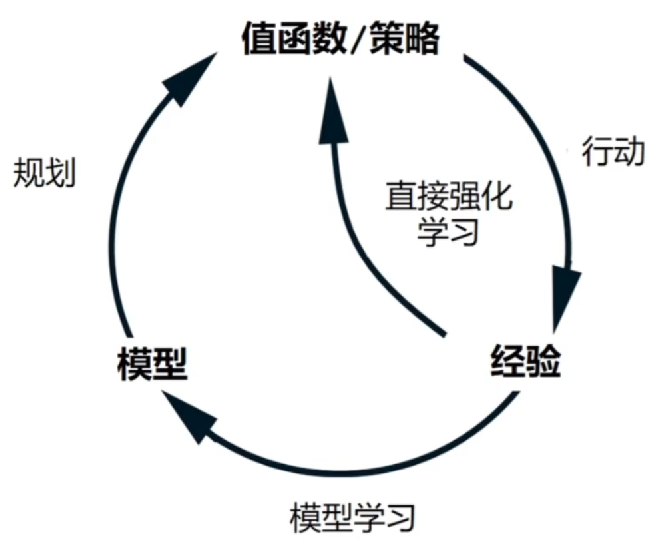
我们的策略改进一点之后,所有原本的价值函数都需要重新评估,这是非常贵的过程,哪有没有办法更好的评估它?这就为什么要做规划
我们会在环境模型下,做出规划的推演,强化模型中 model 都是环境模型
模型
- 给定一个状态和动作,模型能够预测下一个转台和奖励的分布:即
- :给定的状态和动作
- :奖励
- :下一个状态 模型的分类
- 分布模型
- 描述了轨迹的所有可能性及其概率
- 样本模型-黑盒(如神经网络构建)
- 根据概率采样,只产生一条可能的轨迹
- 举例-掷骰子
- 分布模型
- 得到骰子数字总和的所有可能性及其概率
- 样本模型
- 只采样得到一种骰子数字综合
- 分布模型
模型的作用
- 得到模拟的经验数据
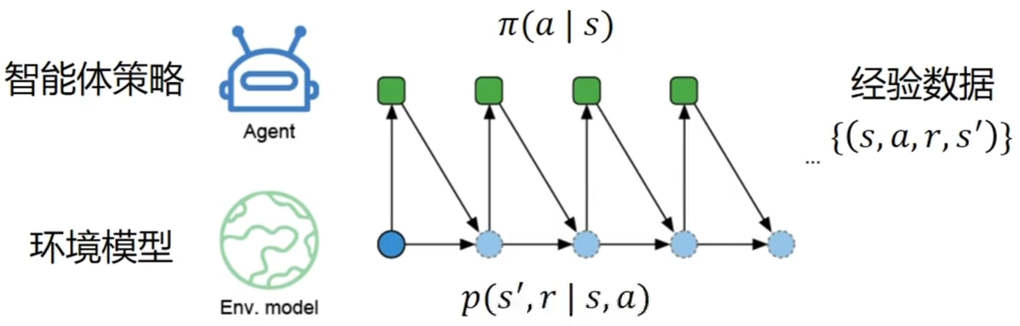
智能体可以和环境模型交互。每次智能体基于当前状态选择一个动作,基于这个状态和动作,模型和真的环境一样可以采样下一个状态和收益,智能体不断地和环境模型交互
基于和模型的交互可以做规划(planning)
规划(Planning)
- 输入一个模型,输出一个策略的搜索过程
 规划的分类
规划的分类 - 状态空间的规划(state-space planning)
- 在状态空间搜索最佳策略,本课程重要围绕这中
- 规划空间的规划(plan-space planning)
- 在规划空间搜索最佳策略,包括遗传算法和偏序规划
- 这是,一个规划就是一个动作集合及动作顺序的约束
- 这是的状态就是一个规划,目标状态就是能完成任务的规划
状态空间的规划是站在一个状态上转到另一个状态 规划空间的规划是站在一个序列|轨迹|动作序列上规划, 面对确定性的环境,如机器人
文本生成的时候两种方式相同,都是基于序列数据
规划的通用框架
- 通过模型采样得到模拟数据
- 利用模拟数据更新值函数从而改进策略

举例
- 动态规划
- 搜索整个状态空间,生成所有的状态转移分布
- 状态转移分布回溯更新状态的值函数
规划的好处
- 任何时间可以被打断或者重定向
- 在复杂问题下,进行小且增量式的时间步规划是很有效的
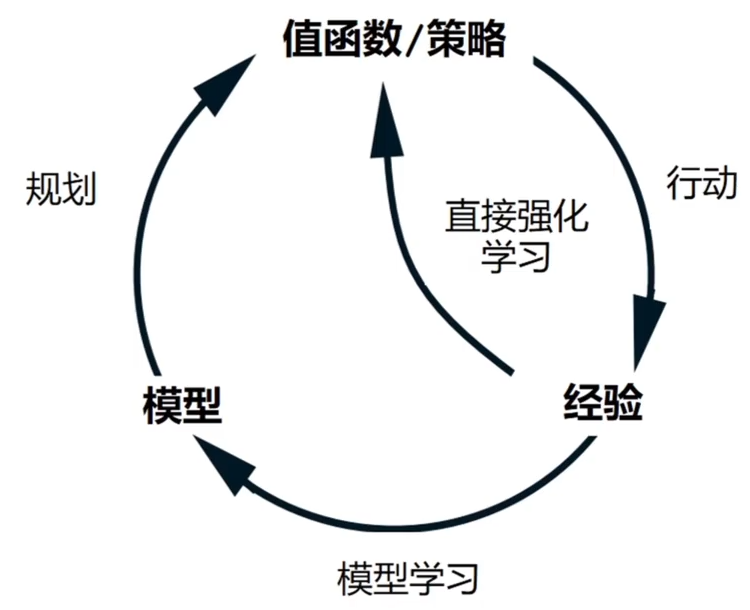
规划与学习
- 不同点
- 规划:利用模型产生的模拟经验
- 学习:利用环境产生的真实经验
- 相同点
- 通过回溯(back-up)更新值函数估计
- 统一来看,学习的方法可以用在模拟经验上

Q 规划算法类比 Q 学习算法同样使用四元组 ,只是 是基于模型产生的
Dyna(集成规划、决策和学习)
经验的不同用途
- 更新模型
- 模型学习,或间接强化学习
- 对经验数据的需求少
- 更新值函数和策略
- 直接强化学习(无模型强化学习)
- 简单且不受模型偏差影响
Dyna 的框架
-
和环境交互产生真实经验
-
左边代表直接强化学习
- 更新值函数和策略
-
右下角落边代表学习模型
- 使用真实经验更新模型
-
右边代表基于模型的规划
- 基于模型随机采样得到的模拟经验
- 只从以前得到的状态动作对随机采样
- 使用模拟经验做规划更新值函数和策略
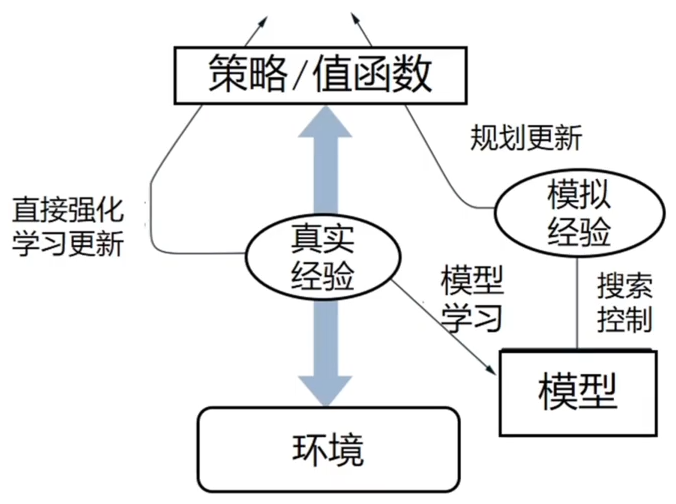
- 基于模型随机采样得到的模拟经验
-
:预测 对的下一个状态和奖励
-
步骤 (5),(6) 去掉就是一时间步表格 Q 学习

基于值函数策略提升和规划可以一起做
Dyna-Q 是一步的 Q 学习和多步的 Q 规划
(6)Q 规划是 n 个一步的模拟,模型模拟多步通常会出现符合误差问题(误差累积),模型只模拟一步
(5)是更新模型的参数,训练模型拟合环境
举例 1: 迷宫
-
环境
- 四个动作(上下左右)
- 碰到障碍物和边界静止
- 到达目标(G),得到奖励+1
- 折扣因子 0.95
-
结果
- 横轴代表游戏轮数
- 纵轴代表到达 G 花的时间步长
- 不同曲线代表不同的规划步长
- 规划步长越长,表现收敛越快
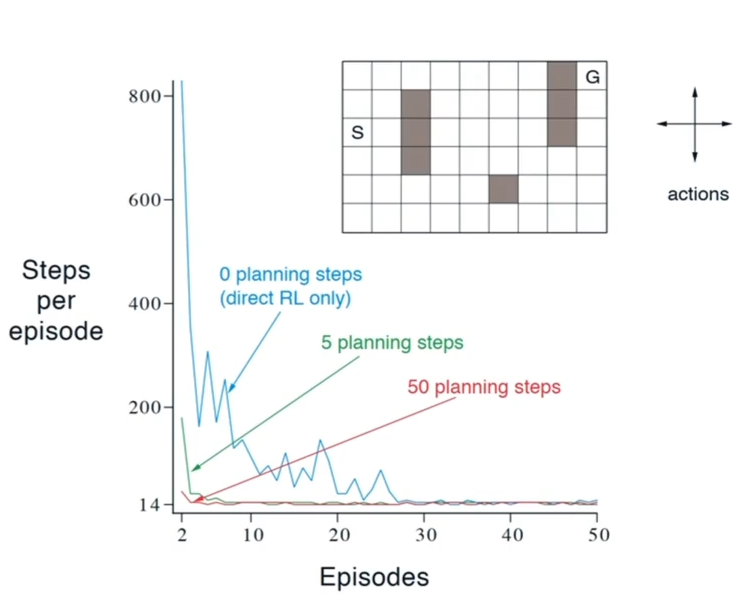
为什么更快
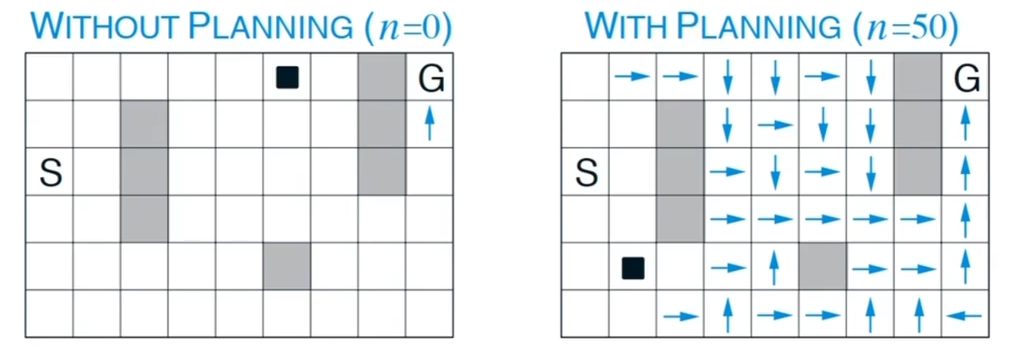
当智能体可以看的更远的时候,可以做 back up ,步长是 1 的时候一次只能更新一个状态(如左图),当步长更长的时候;更新可以影响到沿途的所有状态(如右图),使得学习更快
Q 学习是一步的,但是Q规划是多个一步,每次从之前采样的 s 出发
举例 2: 阻碍迷宫
- 环境
- 1000 步障碍向右移动
- 结果
- 横轴代表时间步
- 纵轴代表累计的收益
- Dyna-Q+加了探索
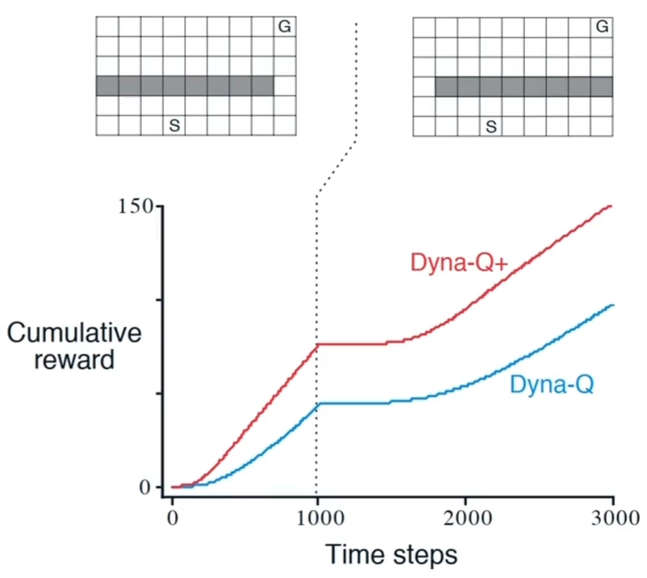
Dyna-Q+
- 将奖励更改为
- :原来得奖励
- :小的权重参数
- :某个状态多久未到达过了
可以让智能体在规划的时候,更多的尝试没有走过的位置 当环境发生改变的时候,能够更快的适应
举例 3:捷径迷宫
- 环境
- 3000 步出现捷径
- 结果
- Dyna-Q+能够发现捷径
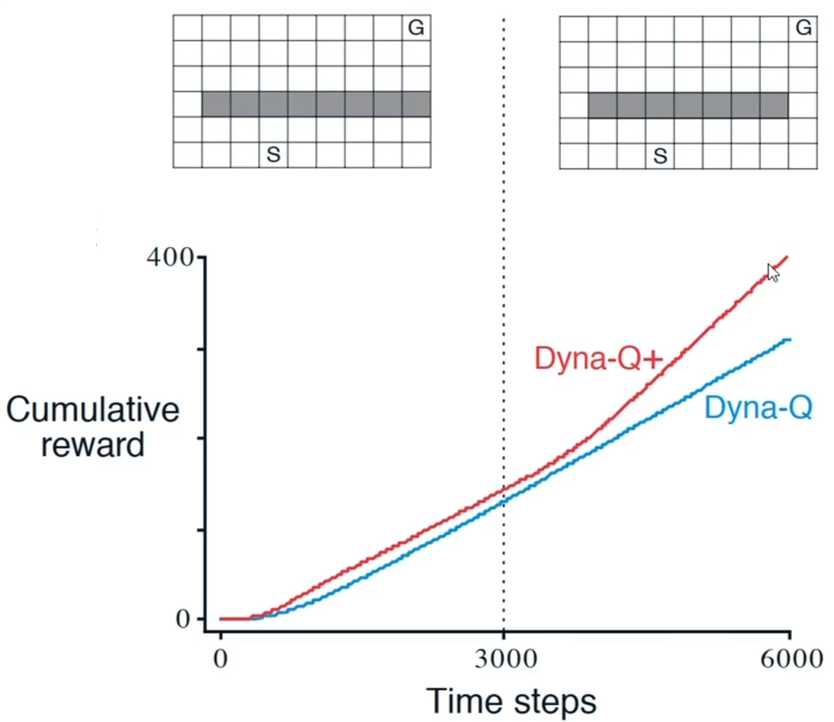
采样方法
常用的采样方法
- 均匀随机采样
- 模拟经验和更新集中在一些特殊的状态动作
随机采样的问题在于初始多数状态收益为零,如下图,初始可以更新的位置只有 useful 的点,其他位置需要等待收益从 useful 慢慢延伸过来,如果随机采样,学习效率很低
我们已经有了模型,可以让智能体对优先走的点做出判断
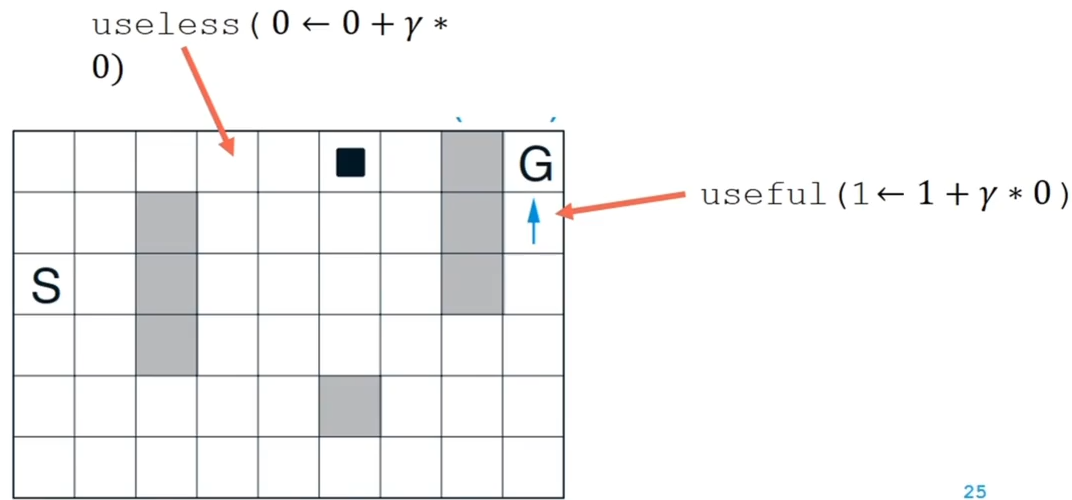
更好的采样方法
- 后向聚焦 (backward focusing)
- 很多状态的值发生变化带动前继状态的值发生变化
- 有的值改变很多,有的改变很少
- 因此需要根据紧急程度,给这些更新设置优先度进行更新
让模拟数据更加关注能让状态值发生改变的位置上 优先级采样
- 设置优先级更新队列
- 根据值改变的幅度定义优先级:
采样方法:优先级采样

从环境采样出四元组,查看更新项的绝对值(价值函数的变化值),若超过阈值,将其插入到队列中,之后检查所有能够到达当前状态的状态,这些递归检查的状态使用模型生成的 来更新价值
前提需要环境模型,如果基于之前的采样数据数据可能不支持这样做(无法得知前一个状态的 )
举例:迷宫
- 横轴代表格子世界的大小
- 纵轴代表收敛到最优策略的更新次数
- 优先级采样收敛更快
局限性及改进
- 随机环境中利用期望更新(expected updates)的方法
- 浪费很多计算资源在一些低概率的状态转移上
- 引入采样更新(sample updates)
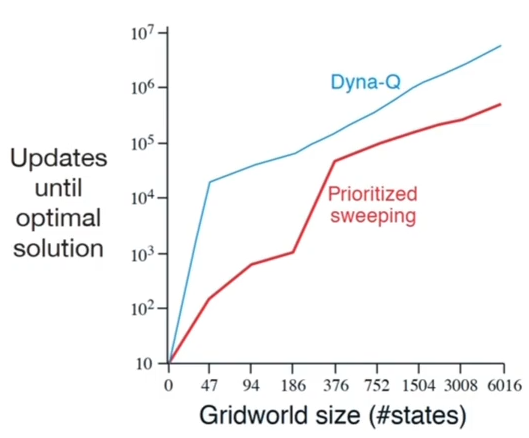
Dyna-Q 的效率已经很高了,如果在 plan 的过程中使用优先级采样,效率会更高,需要的数据更小(如上图)
采样方法:期望更新和采样更新
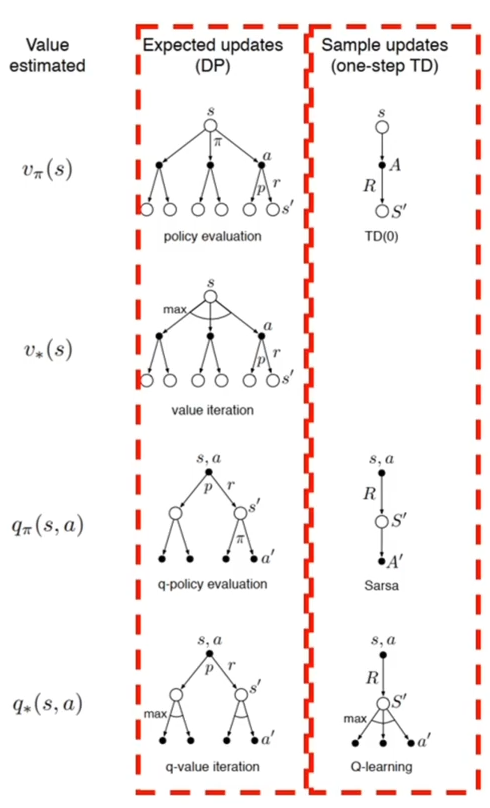
- 值函数
- 动作值函数:
- 期望更新或者采样更新
比较
- 期望更新
- 需要分布模型
- 需要更大的计算量
- 没有偏差更准确
- 采样更新
- 只需要采样模型
- 计算量需求低
- 受到采样误差(sampling error)的影响
期望更新需要直到状态转移概率,让环境模型学习的比较准,才能做好更新 采样更新不需要直到具体的概率分布,只需要用它采样出数据,进行类似 Q-planning 的方法,对 Q 函数进行更新,他的优势是它对环境模型的要求很低,他的更新速度很快,他没有动态规划那么准,但是实际中发现,环境模型不准是常态的,需要对环境模型本身有一个限制性的使用,比如 planning 的长度不要太长,当模型不太准的时候,近处的采样可以使用多次
采样方法:轨迹采样
- 动态规划
- 对整个状态空间进行遍历
- 没有侧重实际需要关注的状态上
- 在状态空间中按照特定分布采样
- 根据当前策略下所观测的分布进行才采样
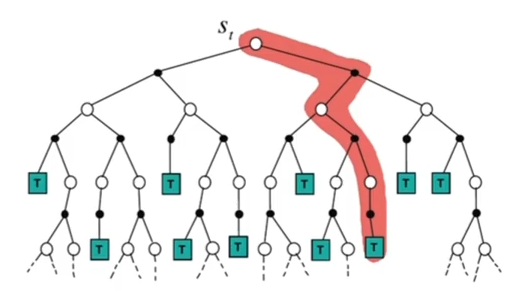
轨迹采样
- 状态转移和奖励由模型决定
- 动作由当前的策略决定
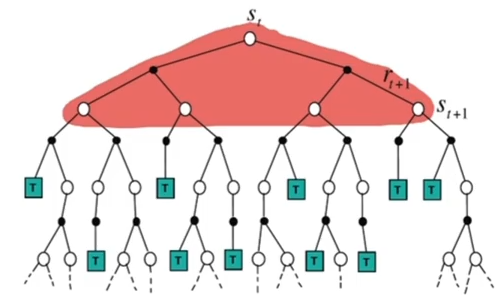
- 优点
- 不需要知道当前策略下状态的分布
- 计算量少,简单有效
- 缺点
- 不断重复更新已经被访问的状态
优点是简单,缺点是不知道概率分布,容易采样到概率高的样本,假设概率很低的一个样本奖励为-10000,实际是影响很大的样本,很可能采样不到,这样智能体对当前的估计是不准确的
使用采样还是哪怕使用重要性采样,也要让后继节点被采样到,要区 分它们的优劣
决策时规划
实时动态规划 (RTDT)
- 和传统动态规划的区别
- 实时的轨迹采样
- 只更新轨迹访问的状态值
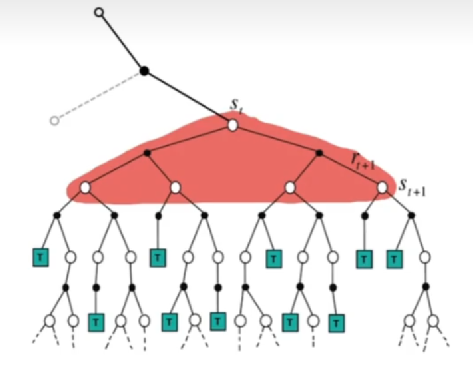
- 优势
- 能够跳过策略无关的状态
- 在解决状态集合规模大的问题上具有优势
- 满足一定条件下可以以概率 1 收敛到最有策略
跑道问题
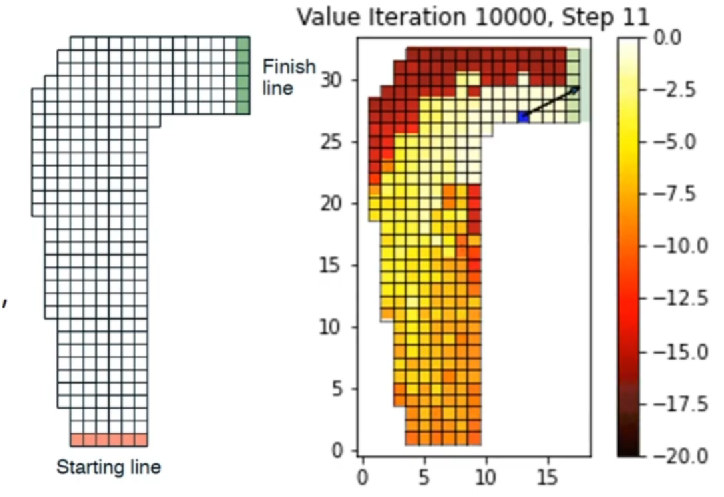
-
环境
- 任务:从起点到重点
- 状态:二维坐标、二维速度
- 动作:每维速度+1,-1,不变
-
结果
- 可到达状态
- 随机策略:9115
- 最优策略:599
- 更行次数少了一半(见下图)
- 可到达状态

计算量明显减少,且在状态空间很大时有优势
-
背景规划(Background Planning)
- 规划是为了更新很多状态值供后续动作选择
- 如动态规划,
-
决策时规划(Decision-time Planning)
- 规划只着眼于当前状态的动作选择
- 在不需要快速反应的应用中很有效,如棋类游戏
启发式搜索(Heuristic Search)
- 访问到当前状态(根节点),对后续可能的情况进行树结构展开
- 叶节点代表轨迹的值函数
- 回溯到当前状态(根节点),方式类似于值函数的更新方式
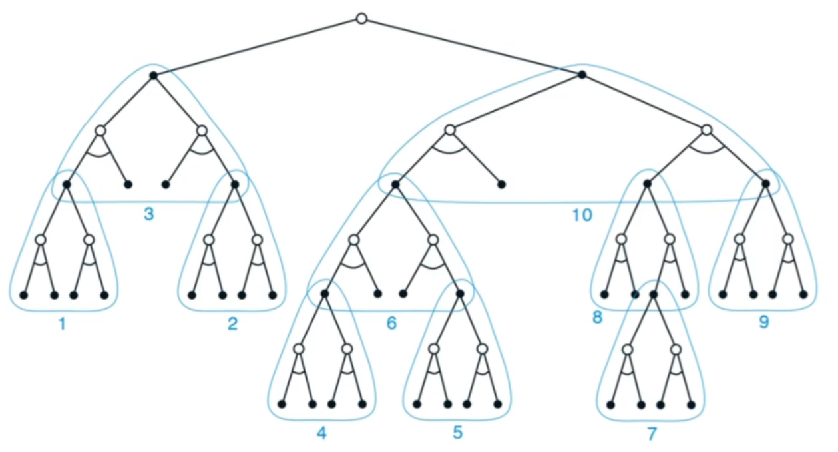
启发式搜索,就是站在当前状态,向后探索分支,理论上探索越多越准确
- 决策时规划,着重于当前状态
- 贪婪策略在但不情况下的扩展
- 启发式搜索看多步规划下,当前状态的最优解
- 搜索越深,计算量越大,得到的动作越接近最优
- 性能提升不是源于多不更新,而是源于专注当前状态的后续可能
搜索的策略是 tree policy,不是随机策略探索;搜索的深度有限制;Rollout policy 可以综合价值函数和 MCTS 两者综合评估当前节点的价值
Rollout 算法
- 从当前状态进行模拟的蒙特卡洛估计
- 选取最高估计值的动作
- 在下一个状态重复上述步骤
特点
- 决策时规划,从当前状态进行
- 直接目的类似于策略迭代和改进,寻找更优的策略
- 表现取决于蒙特卡洛方法估值的准确性
在搜索一颗树的时候有两种算法,一种是 tree search|tree policy,把一棵树展开到一定级别来计算;另一种是 Rollout 算法,站在当前一个 tree 的 node 之上,在之后可以选择不去强行展开每一棵树的节点,而是直接通过快速采取行动的方法走到游戏的终局, 走到这个轨迹的终止状态, 去看到终局的结果, 在回溯到当前节点,对其更好的评估
时间复杂度
- A:决策的动作空间
- K: 一个轨迹的时间步数
- :在第 步下,估计 值函数的时间
- : 每步做出的决策空间
- : 轨迹的次数
算法,会进行 次尝试,即产生 条轨迹,每条轨迹有深度限制,在每一条轨迹上,智能体都会直接采取动作(如每次采取最优 Q 值函数选择动作)直到终止状态或者到达深度限制,在有了 条轨迹之后可以对当前状态进行评估
Rollout 算法的加速方法
- 多个处理器并行采样
- 轨迹截断
- 剔除不可能成为最佳动作的动作
条轨迹是互不干扰的,可以并行处理采样
蒙特卡洛树搜索
- 选择:根据树策略(动作价值函数)遍历树到一个叶节点
- 扩展:从选择的叶节点出发选择未探索过的动作到达新的状态
- 模拟:从新的状态出发按照 策略进行轨迹模拟
- 回溯:得到的回报回溯更新树策略, 访问的状态值不会被保存
- 重复上述步骤直至计算资源耗尽,从根节点选择最优动作
- 得到新状态保留原有树的新状态下的部分节点
- 重复上述步骤直至游戏结束
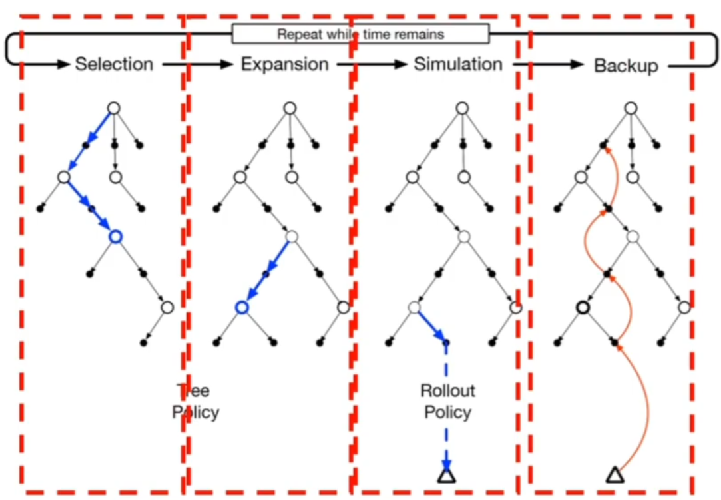
- 蒙特卡洛控制+决策时规划(类似于 )
- 保留了过去一部分的经验数据
- 下一个状态树的初始树是上一个状态树具有高回报的部分
应用
- AlphaGo
- 16 年五番棋比赛中 4:1李世石
- 17 年乌镇围棋峰会中 3:0柯洁
给予规划的强化学习的方法总结
-
模型和规划
-
模型是什么
-
规划是什么
-
基于模型的算法
- Dyna-Q
- Dyna-Q+
-
期望更新和采样更新
- 优先级采样
- 轨迹采样
-
实时动态规划
-
决策时规划
- 启发式算法
- 完全遍历到一定深度
- Rollout 算法
- 蒙特卡洛树搜索
- 启发式算法
Dyna-Q+相关的算法、一步 Q-learning、多步 Q-planning 实时决策的方法MCTS、MCS 方法