回顾:动态规划(DP) 和时序差分( TD) 的关系
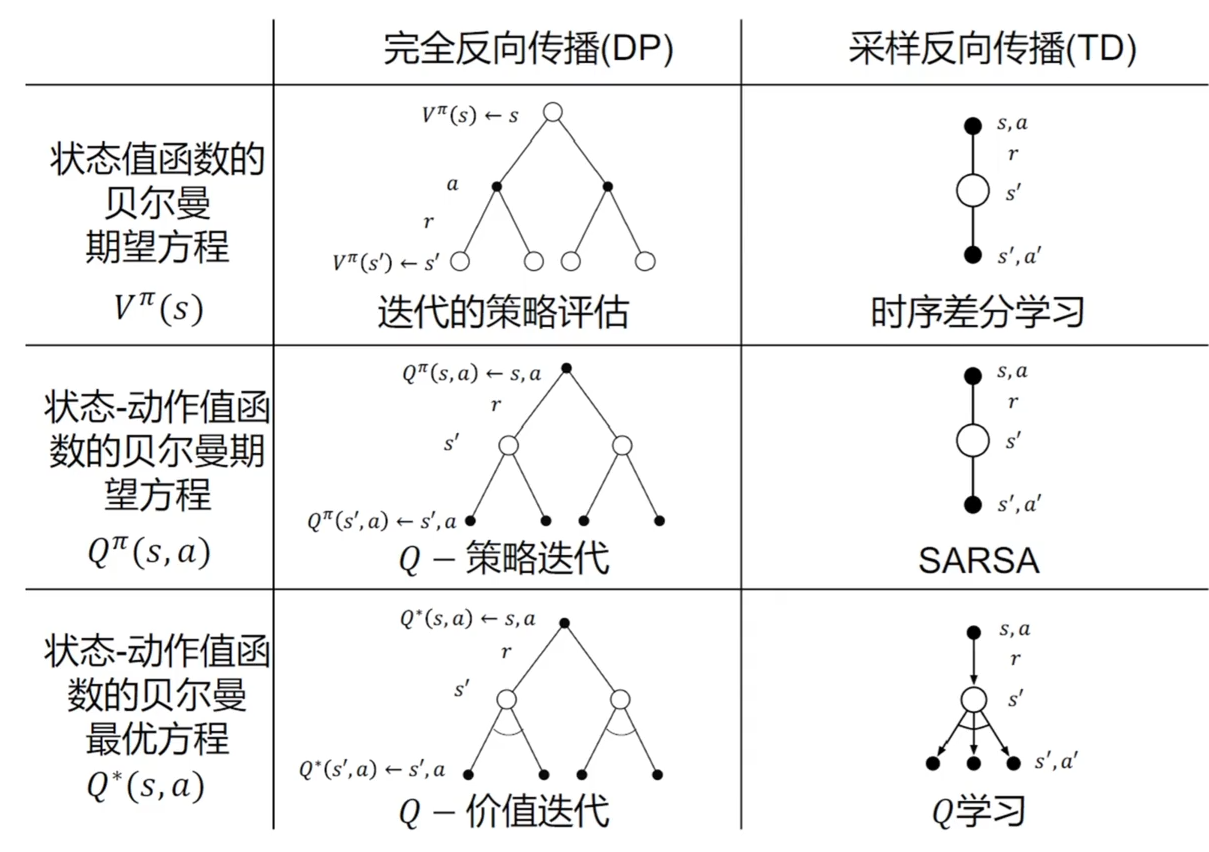
区别在于 DP 可以看到所有状态,基于所有状态的价值来学习;T D 通常不能获得所有的状态,通过采样数据更新价值函数
回顾:动态规划(DP)和时序差分(TD)的区别

DP 基于期望来计算,因为它能看到所有状态的价值;TD 基于采样数据估计出来的价值函数来做策略提升
回顾:蒙特卡洛方法&时序差分

介于两者之间的是 n 步时序差分法,下文多步时许差分预测
多步时序差分
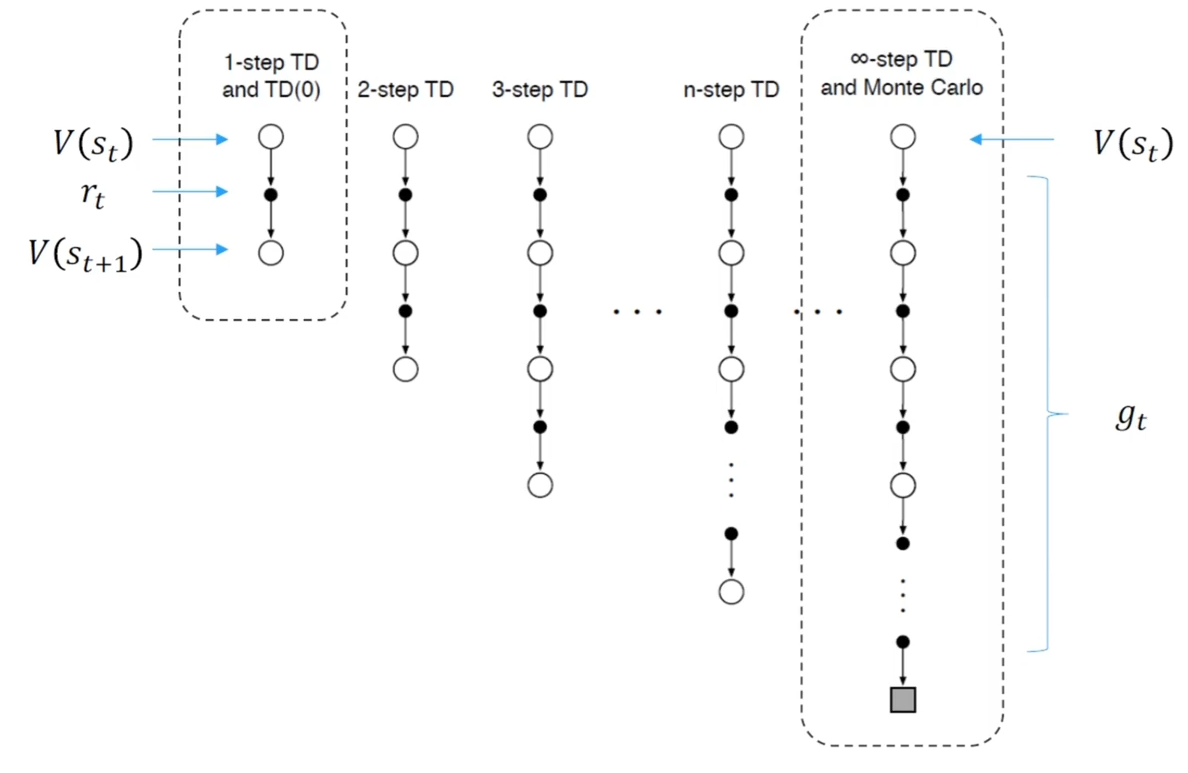
多步时序差分可以采样多步后续数据,整合到 ,n 代表采样步数 N 足够大时相当于蒙特卡洛
N 步累积奖励
-
考虑下列 n 步累计奖励,
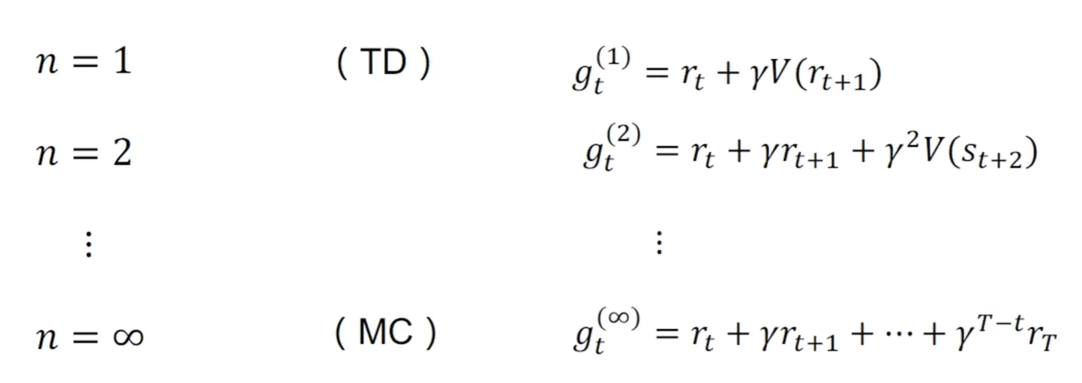
-
定义 n 步累积奖励
-
N 步时序差分学习
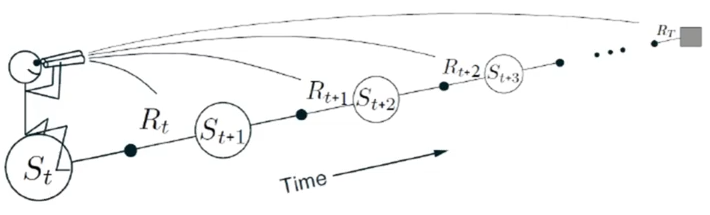
随机游走的例子里面使用 n 步时序差分
多步时序差分法的表现
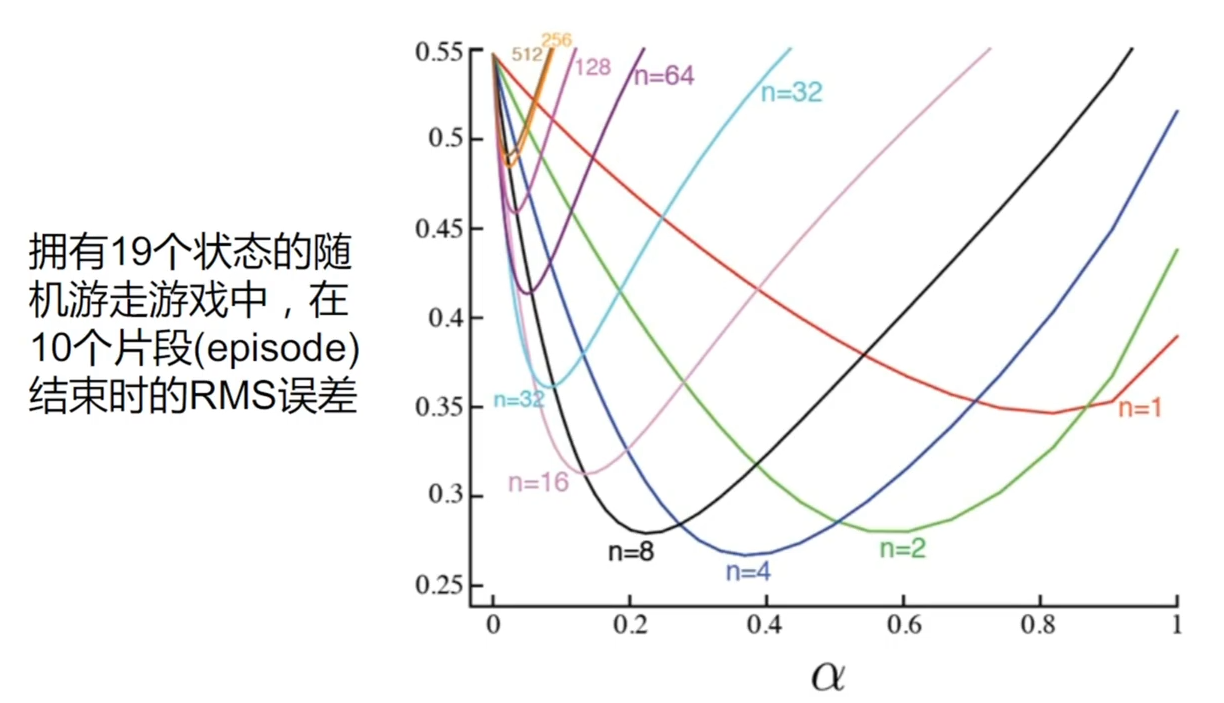
可以看到当 时表现最好 问题:到底选择几步比较好? 下面有介绍综合多个长度采样数据的方法
平均 n 步累积奖励
- 我们可以对不同的 n 下的 n 步累计奖励求平均值
- 例如,求 2 步和 3 步的平均累计奖励
- 上式结合了两种不同的时间步长的信息
- 我们能否结合所有不同时间步长的信息?可以
使用平均 n 步累计奖励的 算法
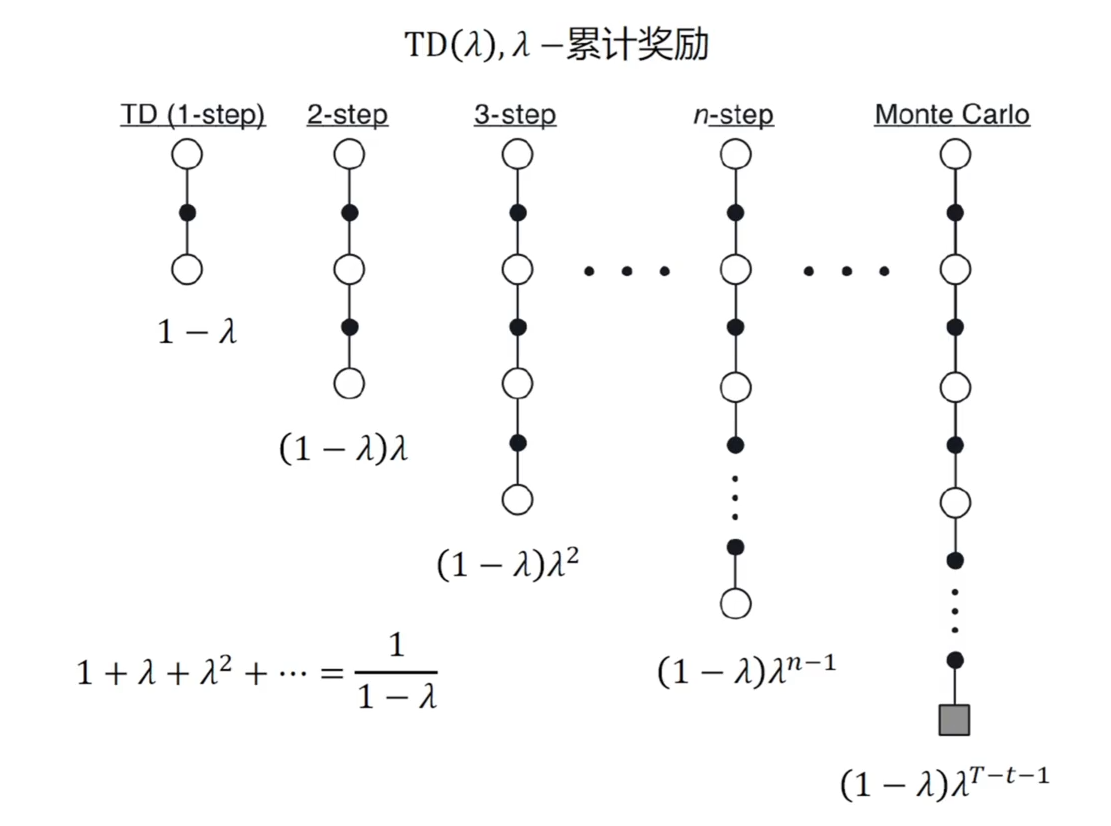
先给对应的步长奖励乘上上 ,再统一乘上 进行归一化,因为系数和是 当 越大,越看短期的短距离的 TD ; 越小,越看长期的长距离的 TD
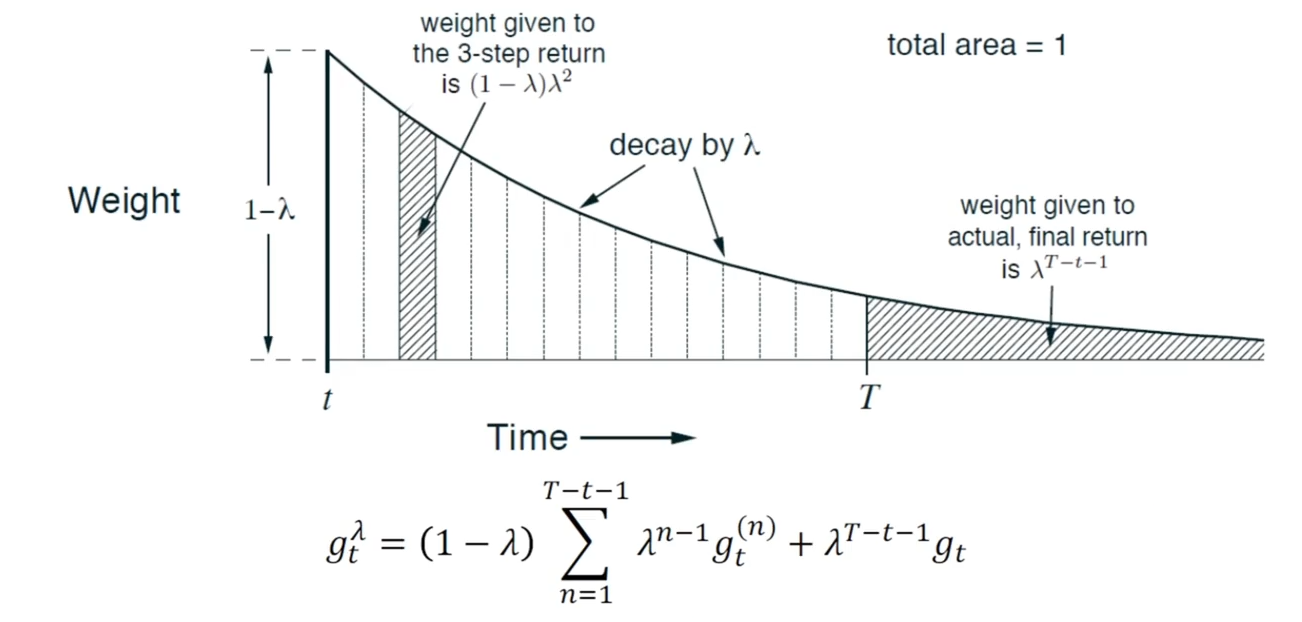
上图是 系数随着时间步的变化
当 时,, 相当于蒙特卡洛 当 时,,相当于单步时序差分方法
步时序差分
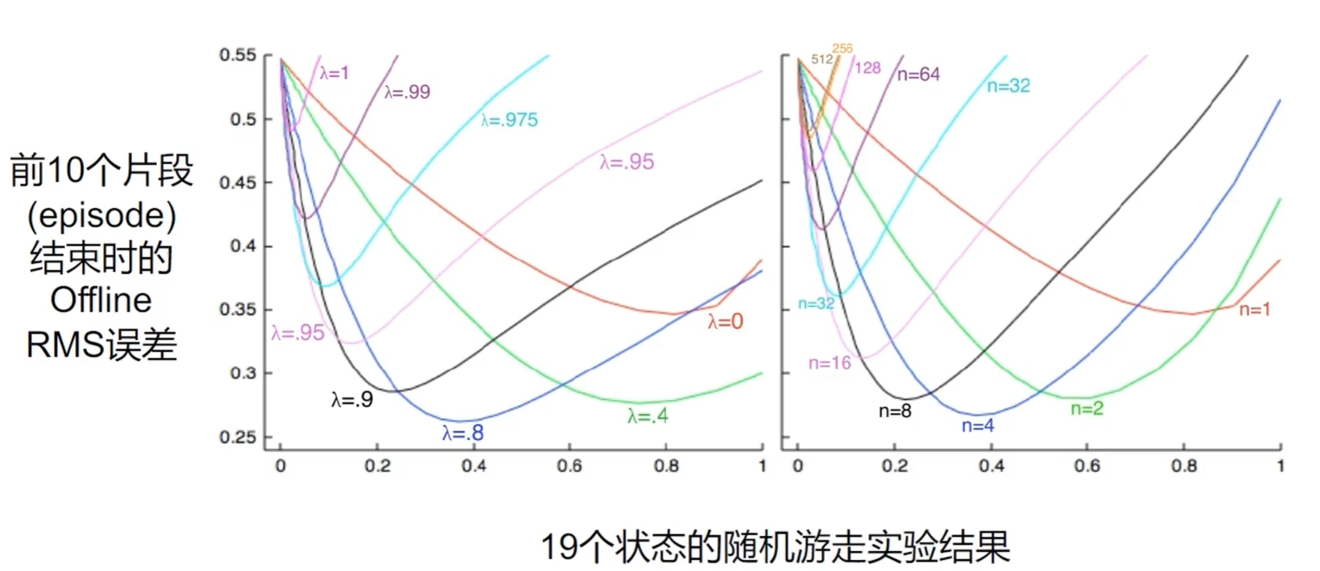
左边时序差分在 时表现更好,且比多步时许差分损失更低
- 使用最佳的 和 值时,离线 累计奖励算法具有稍好一点的实验结果
多步 SARSA
-
N 步的思想是否只能用在预测上?能不能把这种思想放在控制上?这样我们得到了n步 SASAS 算法
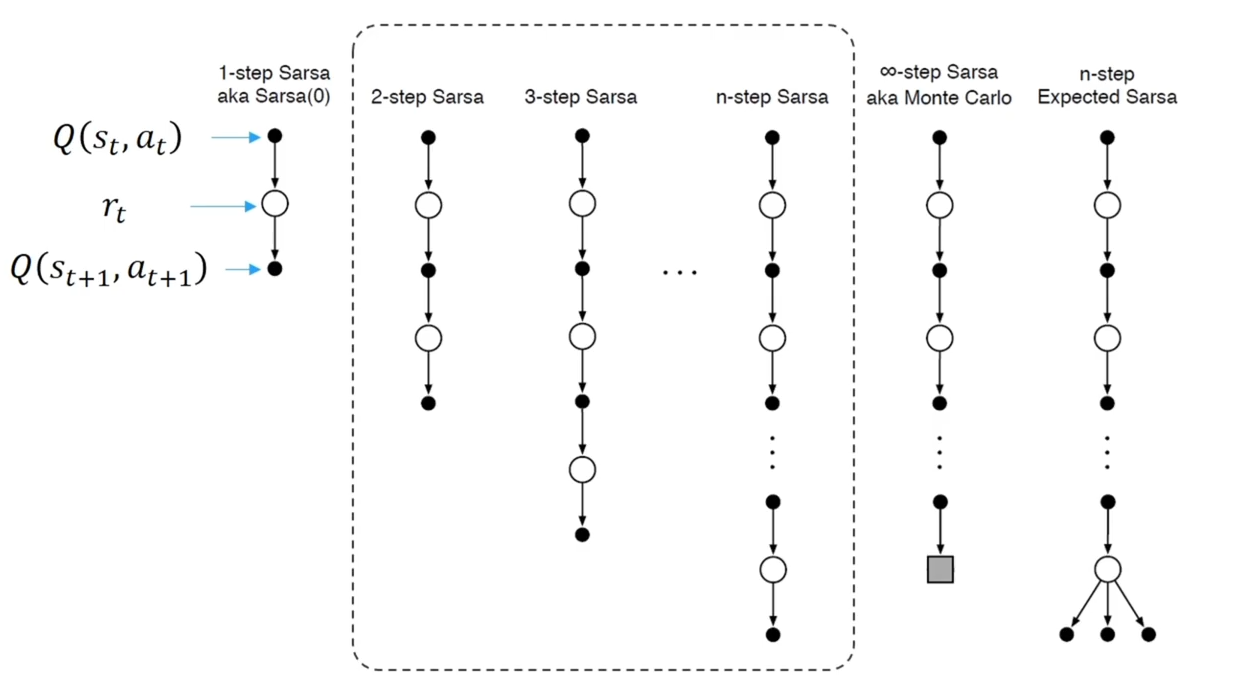
-
类似 n 步 TD,我们有:
多步 SARSA 的例子
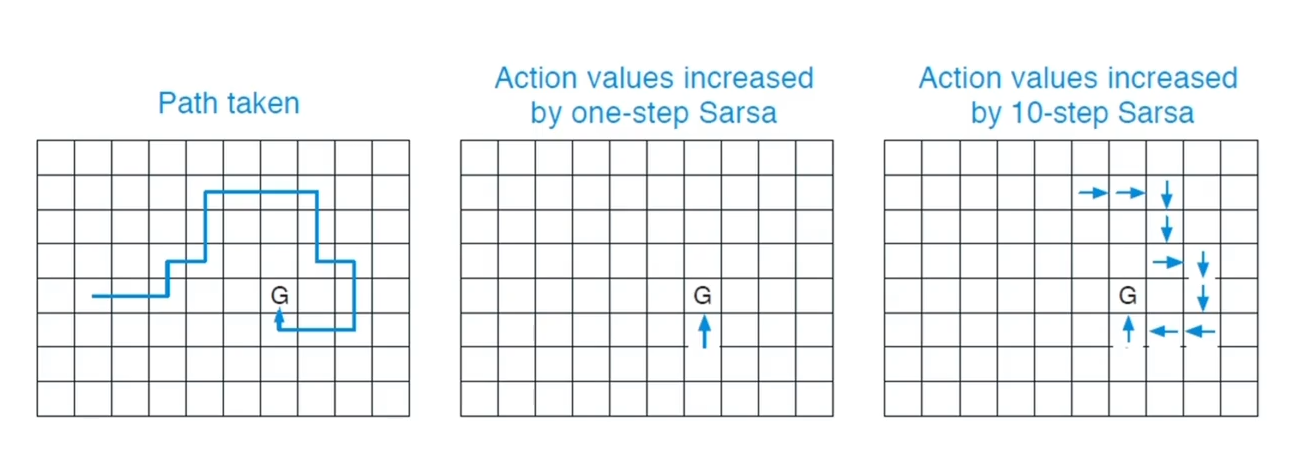
当只有一步 TD 的时候,如果进行了一步四周的收益都一样没有收益,那智能体看的很近,Q 函数值也很少更新,如果使用多步 TD 他就可以跨过一些步数看的更远,看到更远的收益,那么反向传播回去,整个路线上的 Q 函数都会更新值,学习的反而更快
使用重要性采样的多步离线学习法
多步的异策略学习 异策略学习法的一个中心问题是当前策略和采样策略之间数据分布不一致,因此可能需要进行重要性采样
回顾:采用重要性采样的离线学习
-
离线学习下通常需要两个策略
- :通常是对于当前的动作值估计函数的一个贪婪策略(也可能是随机策略)
- :用来收集数据,更有探索性的一个策略(常用 实现)
-
由于收集数据的策略和我们要实际优化的策略不是一个策略,我们需要加上一项修正(值函数为例)
- 在重要性采样的角度对值函数的推倒

- 对于状态值函数 V:
- 对于动作值函数 Q:
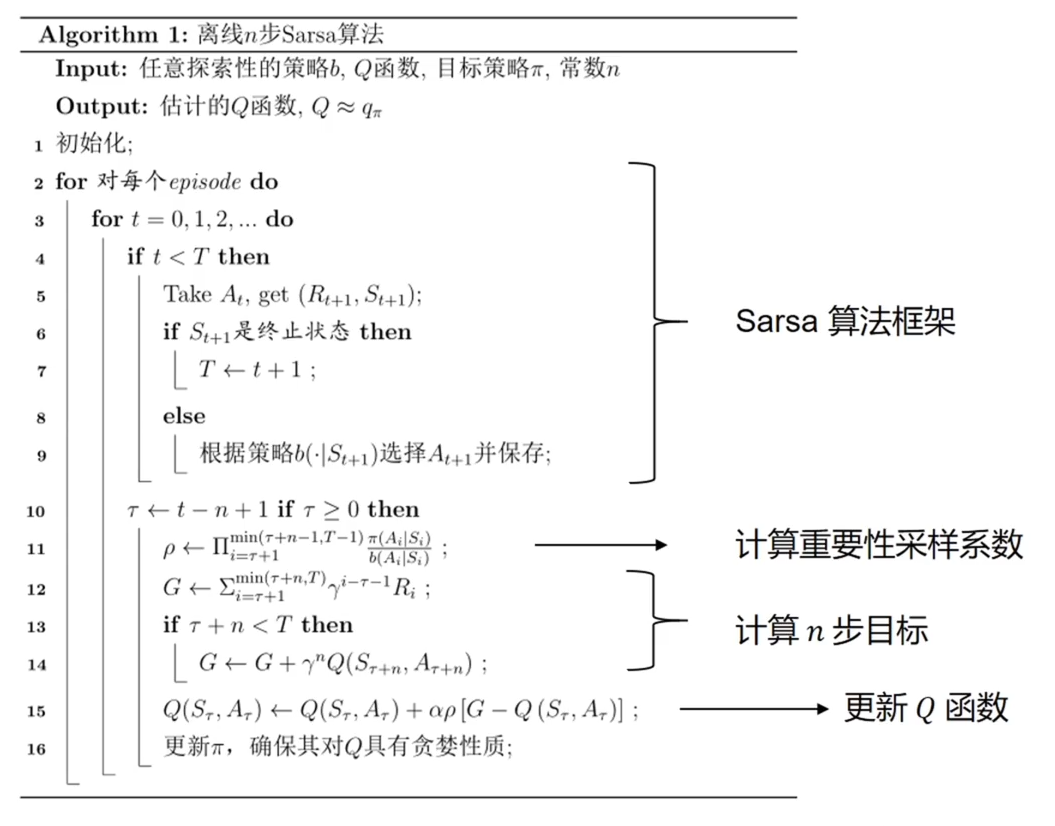
当使用多步 S A R S A 的步数比较大的时候,由于重要性采样连乘,产生的方差是比较大的,是比较危险的方法
但是好的地方在于数据是由 b 策略采样出来的,b 策略通常是在几轮之前的 策略,这样 策略采样的数据分布和当前数据是比较接近的,可以通过选 b 策略采样数据的训练轮次,平衡重要性采样产生的偏差
多步SARSA 采样数据的效率变高了,数据的效率变高了(可以使用多轮),节约了数据;问题是带来了方差
不产生方差|不适用重要性采样的方法,即下面的多步树回朔算法
多步备份|回朔树算法(N-step Tree Backup Algorithm)
- 是否存在一种不需要使用重要性采样的离线算法?
- Q 学习和期望S A R SA
- 我们可以把这种形式拓展到 n 步,称为多步树回朔算法
- 以 为例

对于 Q 学习使用四元组来学习,使用当前的 S 和 A 和 R,下一步要做的动作不用策略 b 采样的数据,而是使用 Q 函数来自举,这样可以避免使用重要性采样来修正
在多步的情况下显然不能继续像 Q 学习一样直接自举,这里我们可以获取到一条轨迹,这条轨迹是策略 b 采样得到的,在学习的时候不能直接使用策略 b 的数据分布学习,我们需要使用期望来规避重要性采样
依然按照策略 b 采样到的数据轨迹,但是在 状态下,上图有三个动作可以选择,我们不知道哪一个是符合当前策略的,因此直接计算他们的期望,中间的数据我们使用 b 采样得到的动作价值表示,其余动作没有数据就使用 Q 自举动作价值,然后分别乘上对应的概率分布(策略 中各个动作的概率分布),轨迹上的动作如 ,采取后的价值包括当前动作价值和后续的多个动作的期望,类似上一层的表示,可以嵌套表示
这里直接使用动作 的价值相当于直接从当前的策略的历史记录(前几轮的策略的记录,即收集数据的 b 策略)中找 的价值
多步树回朔算法推导
- 对于 :
- 对于 :
- 推广到 n 步
无模型强化学习总结
在环境中寻找策略提升点,来更新价值函数的方式,目标是更新价值函数,完成策略提升
如果使用 V 价值函数,绕不开动态环境去更新策略,使用 Q 函数可以直接绕开环境动态
这一节分为两个问题,预测和控制
使用无模型强化学习做控制的时候,通常使用更新 Q 函数
可以使用多步 TD 方法来提升对于一步的稳定和学习效率的提升;也许可以出让一定的方差来提升学习效率,一定的方差,有助于
- 无模型强化学习在黑盒环境下使用,往往有更广的应用范围
- 蒙特卡洛方法采用直接估计价值函数
- 时序差分学习通过下一步的价值估计来更新当前一步的价值估计
- 无模型强化学习的 on-policy 和 off-policy 算法区别
- SARSA、Q 学习
- SARSA 需要学习一次采样一次,它的目标是后续的SA
- Q 学习不需要频繁采样,目标是自举
- SARSA、Q 学习
- 多步自助法可以看作介于蒙特卡洛方法和单步时许差分之间的一种方法
- 讨论:无模型强化学习和基于模型的强化学习方法之间的对比
以上都是基于估计,下面是基于规划,构建环境,