从知道什么是好的,到如何做好行动
- 知道什么是好的:估计
- 基于 V 函数,如何选择好的行动?
是需要知道的环境模型(状态转移矩阵),无模型的情况下 未知,所以基于价值函数的策略改进方法不能使用
- 基于 Q 函数,如何选择好的行动?
Q 函数不需要环境模型,**估计 Q 函数对直接做行动(控制)有直接的作用**
这样只需要更好的估计Q 函数,就相当于在做策略提升,策略一直在提升,我们就要注意到海量的数据的策略和正在学习的策略之间的关系
我们初步采样得到的数据和优化的策略需要的数据的分布是不完全一致的,所以要对数据做一些改进,让学习的策略能够着重学习优化策略的数据,这里有两个方法
SARSA-on-policy(同策略学习|在线学习)
对于当前策略执行的每个(状态-动作-奖励-状态-动作)元组
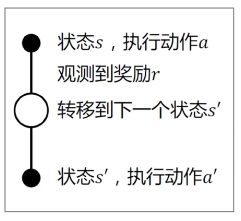 SARSA 更新状态-动作值函数为
SARSA 更新状态-动作值函数为
用五元组来估计 Q 函数
使用 SARSA 的在线策略控制
每个时间步长
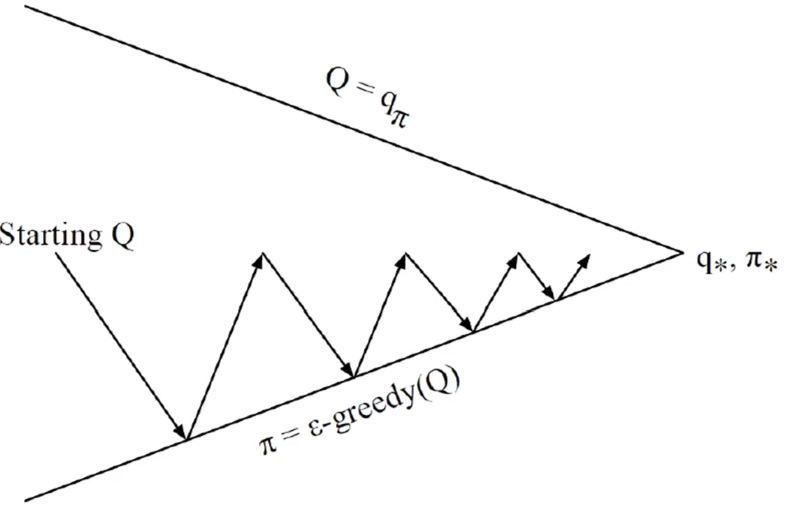
- 策略评估:SARSA
- 策略改进: 策略改进
总结:使用更新五元组的方式估计 Q 函数,使用一步 TD(时序差分)来更新 Q 函数。更新一次 Q 函数相当于策略进行了改进,原本的采样数据的策略已经和现在不一样了,需要重新进行采样
SARSA 算法

注意:在线策略时序差分控制(on-policy TD contral)使用当前动作进行采样。即,SARSA 算法中两个 A 都是当前策略选择的
两个 A 是指当前状态的 和下一个状态 中的 和
SARSA 示例:Windy Gridworld
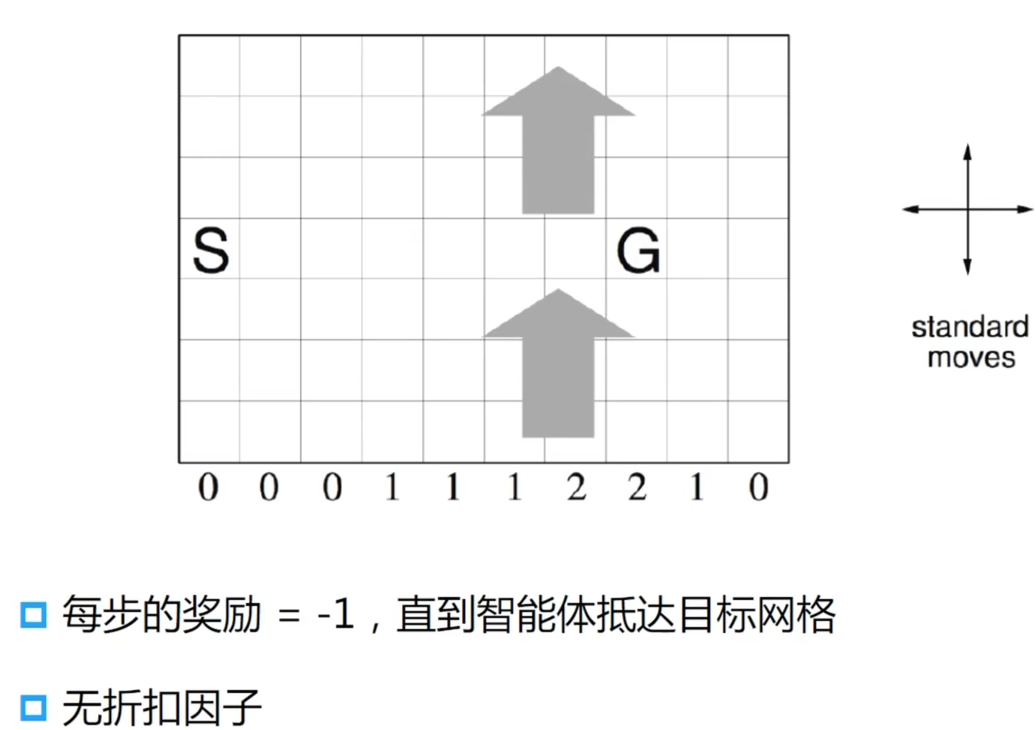
学习到的策略
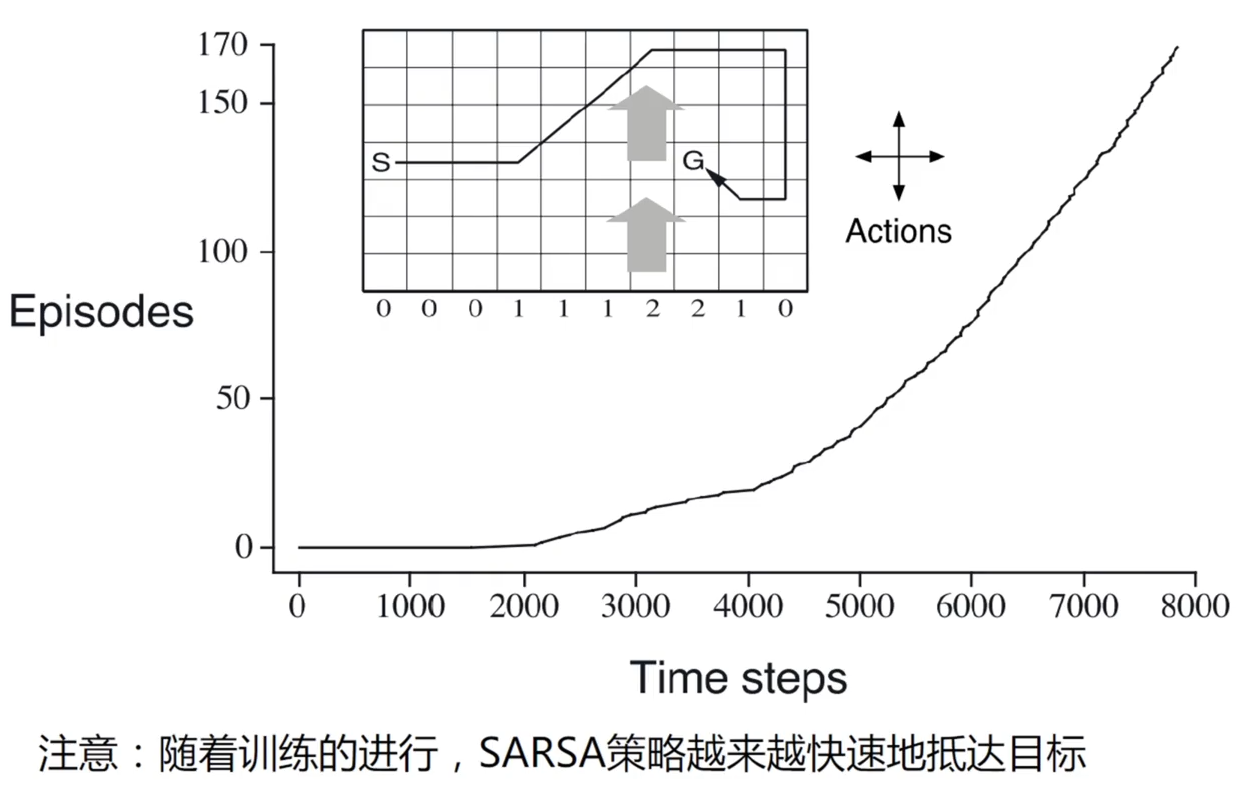
斜率越陡,代表智能体需要的步数越少
Q 学习算法及其收敛性-off-policy(异策略学习|离线学习)
可以使用不一样的数据分布的数据来训练当前策略
Q 学习
学习状态-动作值函数 ,不直接优化策略 一种离线策略学习方法

如果是异策略学习采集的数据在使用了一次之后,策略进行改进,之前的数据就不能使用了,需要重新采集数据,因此这样是非常贵的
而异策略学习希望数据可以重复使用
离线策略学习
什么是离线策略学习
- 目标策略 进行值函数评估 ( 或 )
- 行为策略 收集数据: 为什么使用离线策略学习
- 平衡探索和利用
- 通过观察人类和其他智能体学习策略
- 重用旧策略所产生的经验
- 遵循探索策略时学习最优策略
- 遵循一个策略时学习多个策略
- 在剑桥 M S R 研究时的一个 xbox music 的例子
Q 学习
-
使用数据片段 不需要重要性采样,为什么?
-
根据行为策略选择动作
- 目标
-
更新 的值以逼近目标状态-动作值
$Q(s_{t+1},a^\prime_{t+1})$ 是策略 $\pi$ 的动作,不是采集数据的策略
总结:这里不使用 的原因,首先 和 时给定的初始状态, 是用来估计的策略选取的动作,但是这个动作在离线学习时是有采样策略得到的,他代表的 的策略,和我们要学习的策略没有关系。
所以这时候得到的数据是自举的,他没有相关性的更新,相当于使用的自己策略的历史数据,这样就不需要进行重要性采样来贴近学习的策略的分布
使用 Q 学习的离线策略控制
- 允许行为策略和目标策略都进行改进
- 目标策略 是关于 的贪心策略
- 行为策略 是关于 Q (s, a) 的 策略
- Q-学习目标函数可以简化为
- Q-学习更新方式-24:48
总结 不需要进行 , ~是要探索更多的状态,这里不需要探索更多下一步的状态直接 max 了
四元组更新不需要后续的动作 , 在状态 下选择从 到 的决策是采样|行为策略 的选择,不使用 策略选择的决策学习,就没有数据分布的问题,不需要重要性采样,它是自举的,类似在线学习的方式学习
不再站在新的状态下去使用老的数据做目标了,这里使用自举的数据(maxQ)做目标,杜绝了重要性采样的问题
模拟站在新的 上,基于当前的Q 构建的策略能够获取到最高的 value 值,这使得使用 Q 函数使用了历史数据(使用了 Q 函数自举目标,这里的 max 相当于进行了一次一步的采样|临时采样),但是做了一个类似在线学习的感觉(这里使用自举的方式模拟同策略的新采样)
在线学习有一个好处,当前的 S 和 A,是基于当前正在学习的策略采样出来的,正在学习的策略是基于当卡策略会遇到的情况进行改进的,这使得它的更新效果更好。
如果离线学习更新的更新的数据分布,距离当前的 太远,即使这个更新不需要重要性采样,Q 学习本身效率也是很低的,甚至无效(学习的策略获取不到它需要学习的状态数据,因此学习效果很差)
异策略学习的一个原则
采样行为策略 和当前策略不要相隔太远,保证当前策略能够学到东西
通常用之前数步的策略的版本采样出来的数据,把它存到数据缓冲池(data repaly buffer),每次从缓冲池中采样出数据,对当前的 Q 函数进行更新,数据缓冲池固定大小,满了之后,逐步把旧的数据割掉
如果收的紧(数据相差轮次小,甚至只是一轮,这样用到的数据是更新的,采样的策略和当前策略相差更小),更接近同策略学习 如果很松(数据相差轮次很大,采样的策略和当前策略相差更大),更接近离线学习 如果不松不紧(缓冲适中,数据相差几轮),更接近 Q 学习|异策略学习
定理
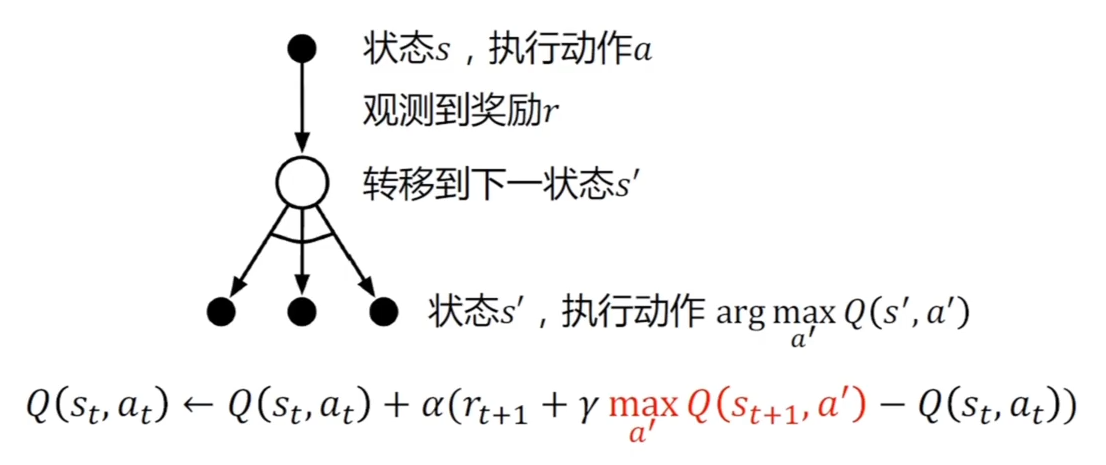
Q -学习控制收敛到最优状态-动作值函数
Q 学习有一个不动点的一个收敛的优势,对于任何一个(s, a)见到的足够多,Q 学习可以保证收敛到最优的状态-动作函数上
为什么不适用重要性采样
- 使用状态-动作值函数而不死使用状态值函数
- 使用四元组数据片段
Q 学习收敛性证明

SARSA 与 Q 学习对比实验
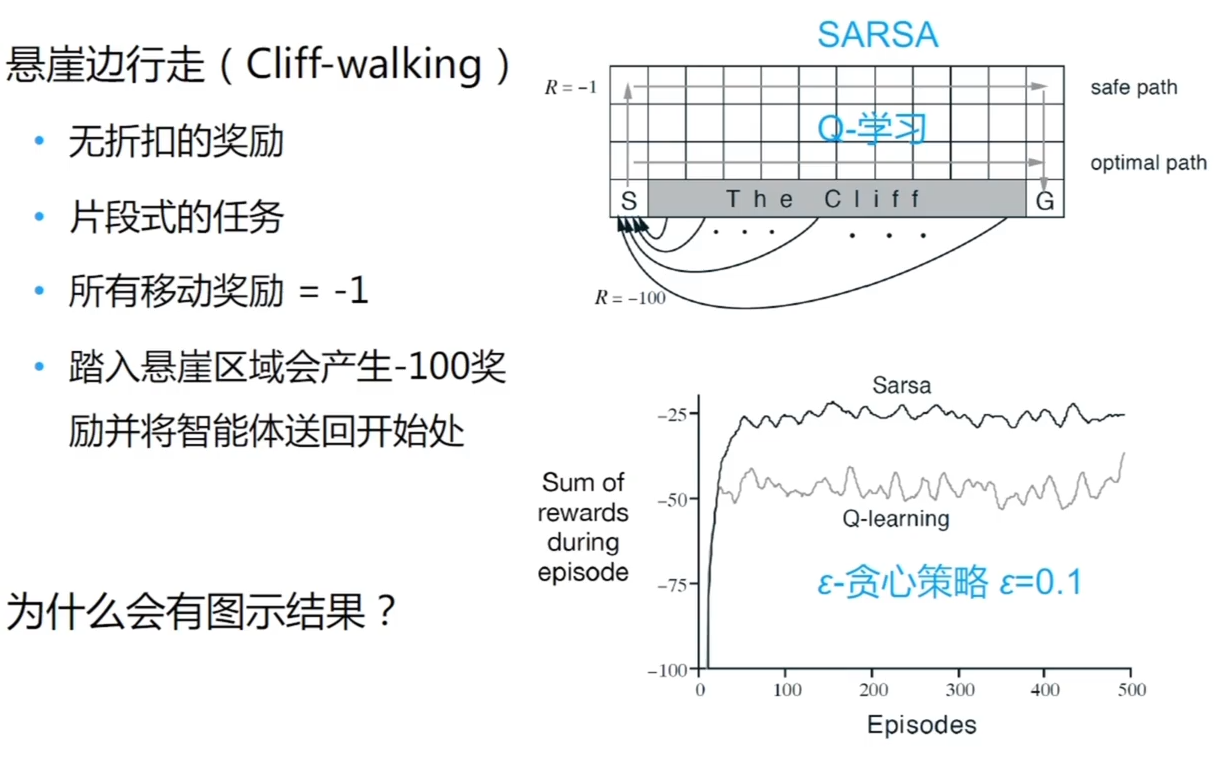
SARSA 学到的是保守路线,Q 学习到的是激进路线,但是最短
Q 学习是基于 基础上求 max 动作的一个操作,他不会发现掉落悬崖的风险(看不到风险,只看到最高收益的动作)
SARSA 不同,再学习过程中使用 策略会平衡好探索和利用,它沿着悬崖走是可能掉下去的(探索的时候随机选方向),掉下去会获得巨大的 r ,所以最后学得到表示是远离悬崖走的
在学习过程中,不一定获取的 value 比 Q 学习高,但是如果应用的环境中,如果还是带了 , 由于他学习的是保守性的规矩,走出来的 value 还会大于 Q 学习,原因是 Q 学习的时候是同策略的,根本不管探索与利用不管掉下去的风险,所以会走出激进的策略。但是如果 Q 学习部署到环境之后,还会有 , 那么 Q 学习这个路径就会有风险(这里是说训练和部署是要一致,Q 学习的路径不允许他去探索,不管学习还是部署)