策略值函数估计
给定环境 MDP 和策略 ,策略值函数估计如下
状态价值-贝尔曼等式-贝尔曼期望等式
是立即奖励 是时间折扣 是状态转移概率分布,包含了环境状态和选择动作的信息 是下一状态的价值 总结:这个贝尔曼期望方程是算的一个期望,包括所有动作产生的收益乘以对应被选取的概率。这里没有选择一个确定的动作,按照固定策略(如随机平均选择)选择动作
动作价值-贝尔曼等式-贝尔曼期望等式
MDP 中策略的目标
策略的目标:选择能够最大化累计奖励期望的动作
-
是折扣因子,调整未来奖励的折扣因子
-
给定一个确定性的策略
- 即,在状态 下采取动作
给策略 定义价值函数
寻找优化策略的方法:策略迭代和价值迭代
价值函数和策略相关
可以对最优价值函数和最优策略执行更新迭代
- 策略迭代
- 价值迭代
策略迭代
对于一个动作空间和状态空间有限的 M D P :
策略迭代过程 (基于 V 价值函数)
- 随机初始化策略
- 重复以下过程直到收敛
- 计算
- 对于每一个状态,更新
策略就是当前状态下,哪一个动作的价值函数最大(包括当前动作的价值和后续状态的价值),当前状态下的策略就是选哪一个动作
PS:更新价值函数会很耗时间
策略迭代过程 (基于 Q 价值函数)
- 随机初始化策略
- 重复以下过程直到收敛
- 计算
- 对每一个状态,更新
这样找到一个状态下的最优动作,动作价值函数 就需要更新一次
PS: 更新价值函数很耗时间
总结:在 MDP(有限马尔可夫决策)的情况下,状态 S 和动作 A 的状态空间是有限的,可以计算出每一个 状态的价值函数 和动作价值函数 ,这两个函数可以看成表格,保存着对应状态的价值
举例:策略评估

K 代表迭代次数
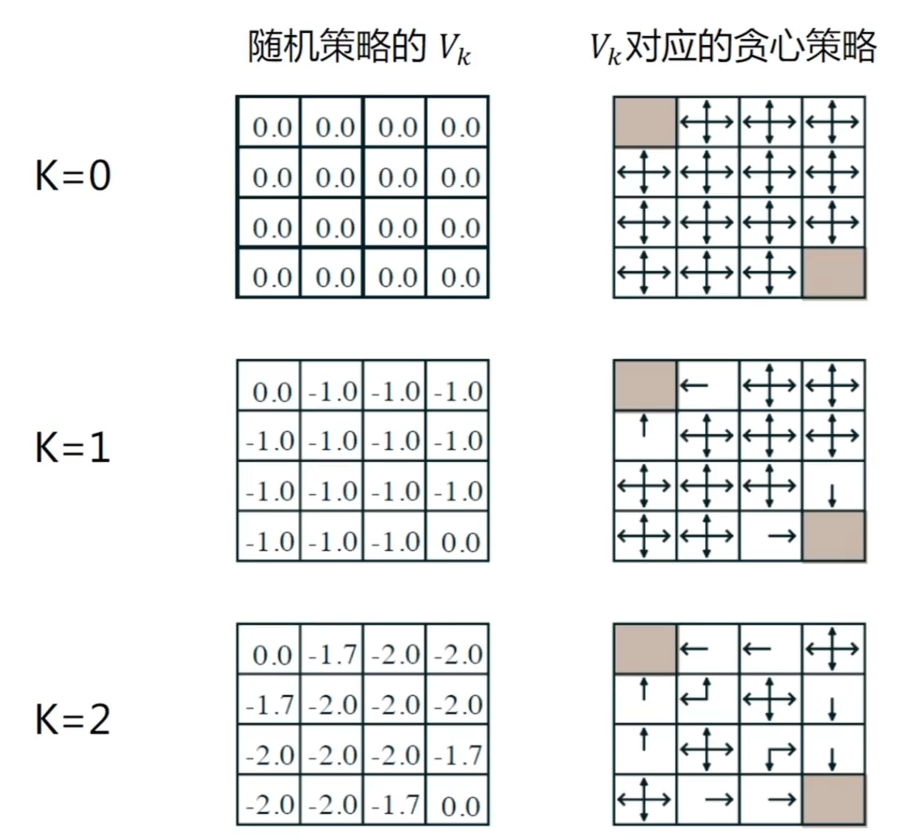
左边是学到的 V 价值函数(基于 V 价值函数)的值(对应位置对应价值的表格,这个值是移动一步的收益-1 + 对相邻的四个方向的价值函数的值求期望算出来的), =1,采用随机策略,每个方向概率 1/4 右边是学到的是策略(选择收益最大的方向)
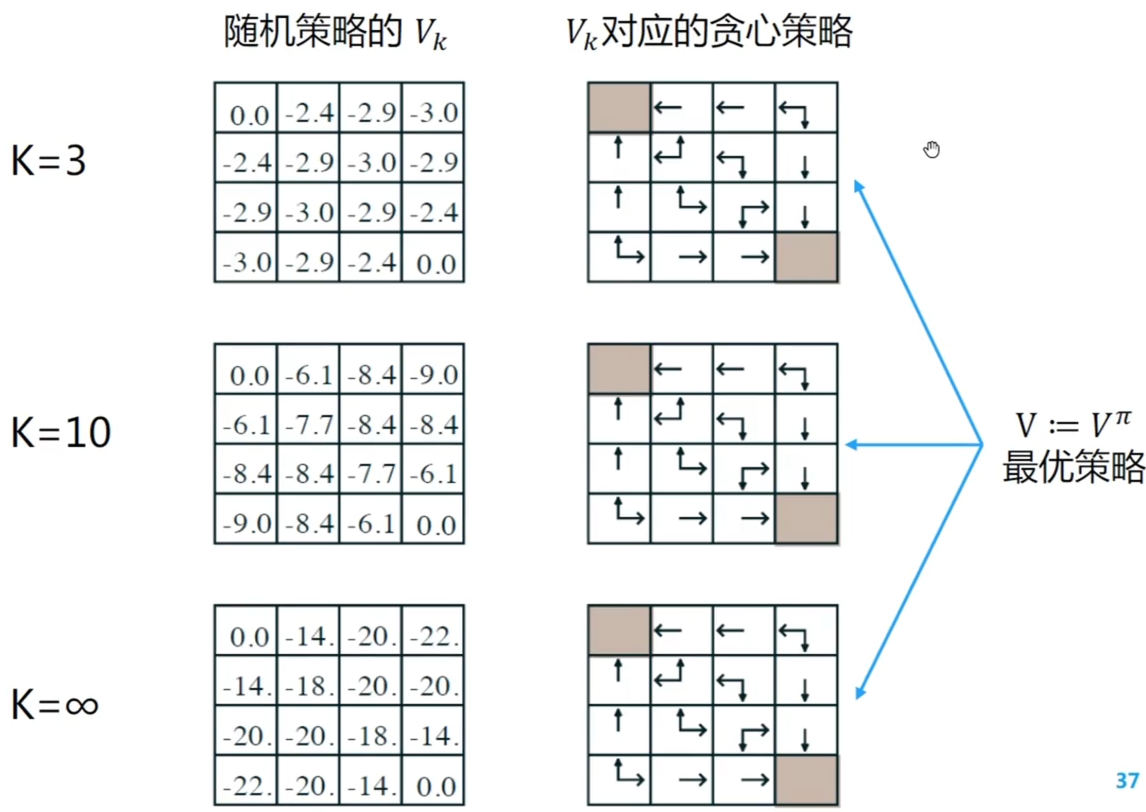
当 左边表格中的价值会收敛到确定值,所代表的含义是当用随机策略移动的移动到终点的步数的期望 右边会收敛到最优策略
总结:当前 ,收敛会比较慢,当 值比较小,如 会收敛的更快,此时更关注眼前的收益,减小关注未来收益 观察左边表格, 和 对比,虽然 时没有到达收敛值,但是已经可以对应真实价值函数 下的策略提升之后的策略,由于价值函数计算非常耗时间,可以不进行非常精确的计算就可以来改进策略,这样提升学习的速度,就是下面的价值迭代
价值迭代
价值迭代是策略迭代的加速版本,牺牲了评估价值函数的精度,换来了非常快速的更新 对于一个动作空间和状态空间有限的 M D P :
价值迭代过程
- 对于每一个状态 ,初始化
- 重复以下过程直到收敛
- 对每个状态,更新
贝尔曼最优迭代式会收敛到全局最优点
以上计算中没有明确的策略
总结:这里没有显示的出现策略 ,这表明不需要策略参与计算,只需要找到当前状态下选哪一个动作价值最大
举例:最短路径
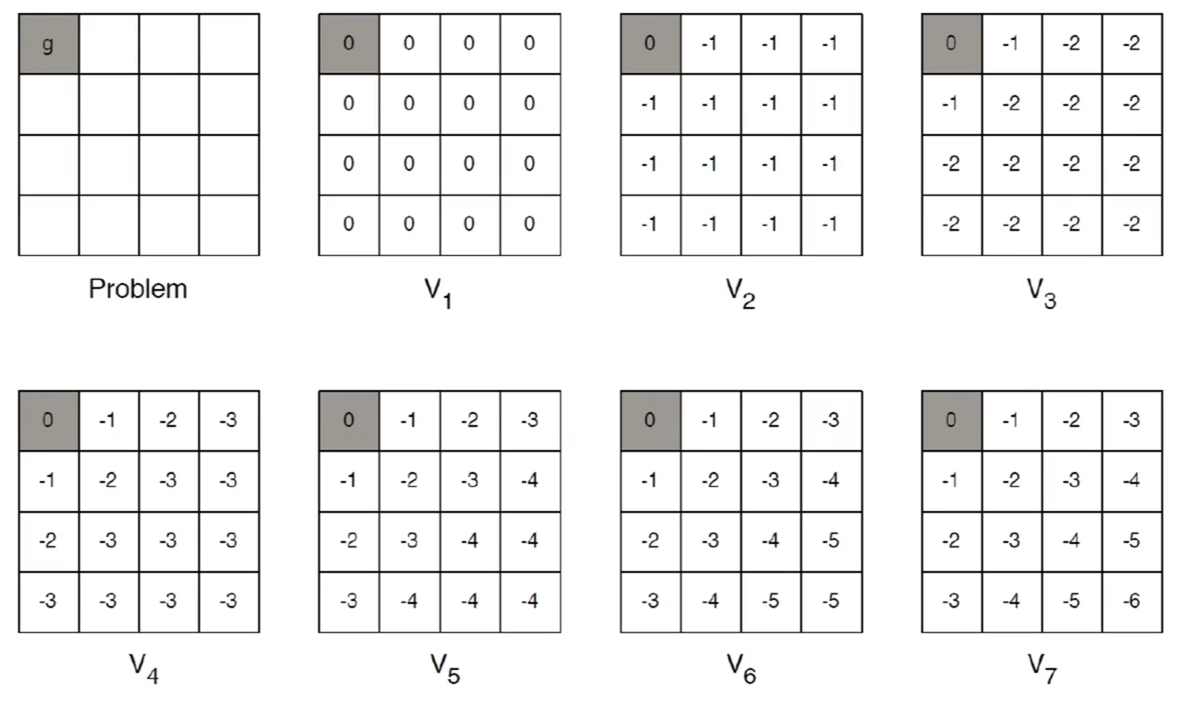
这样收敛很快,从更新公式上对比,价值迭代不需要计算复杂的价值函数的值,只需要把上一次的价值函数表格拿过来使用,就可以快速的收敛
对比策略迭代 策略迭代的问题在于我们直接得到的是一个策略的表格,更新策略表格需要用到价值函数的表格,价值函数还需要进行一步计算,由于策略更新,价值函数需要重新计算策略分布(选择动作概率的分布)和之前价值函数的期望,计算量很大
价值迭代只需要关注上一次价值表格中的数值,接着更新就可以,不需要基于修改的策略重新计算价值函数的表格,所以不依赖策略,并且大大加速了速度
最优价值函数
对状态 来说的最优价值函数是所有策略可获得的最大可能折扣奖励的和
最优价值函数的 Bellman 等式(Bellman optimality equation)
最优策略
对状态 和策略
这表明当我们的价值函数 收敛到最优价值函数 时,也会有一个最优策略 与其相对应,此时最优价值函数 V 有了意义。
在 V 没有收敛时,不能保证它的合理性,它可能没有实际意义
价值迭代 VS. 策略迭代
策略迭代
价值迭代
备注:
- 价值迭代是贪心更新法
- 相当于策略评估中进行一轮价值更新,然后直接根据更新后的价值进行策略提升
- 策略迭代中,用贝尔曼等式更新价值函数代价很大
- 对于空间比较小的 MDP,策略迭代通常很快收敛
- 对偶空间比较大的 MDP,价值迭代更实用|效率更高
- 如果没有状态转移循环,最好用价值迭代
基于模型的强化学习
学习一个 MDP 模型
当不知道环境数据时,通过采样获取到轨迹数据|序列数据
从经验中学习一个 MDP 模型
- 学习状态转移概率
- 学习奖励函数,也就是立即奖赏期望
学习模型&优化策略
算法
- 随机初始化策略
- 重复以下过程直到收敛
- 在 MDP 中执行 ,收集经验数据
- 使用 MDP 中累积经验更新对 和 的估计
- 利用 和 的估计执行价值迭代,的到新的估计价值函数
- 根据 更新策略 为贪心策略
在实际问题中,状态转移和奖励函数一般不是明确给出的 另一种解决方式是不学习 M D P,从经验中直接学习价值函数和策略 也就是无模型的强化学习(Model-free Reinforcement Learning)