简要介绍
- 直接将 “跨模态 Mamba” 用作融合器,提出双域同质融合策略以改善 LiDAR–Camera 融合的对齐与信息传递。该文把 Mamba 当作跨模态交换/聚合的核心模块
激光雷达和图像融合到 BEV 中的问题
- 高的计算成本和查询生成方面的挑战
- 两个域中的特征不对齐导致次优的检测精度
融合感知介绍 激光雷达使用点云改制精确的三维空间信息,摄像头通过捕获可监管类生成富含纹理细节的图像。通过利用机关雷达和摄像头的互补优势,基于融合的物体检测器在准确性和鲁棒性方面一直优于单一传感器
但是,优于摄像头和激光雷达数据之间的差异,多传感器融合并非易事
融合感知相关研究
-
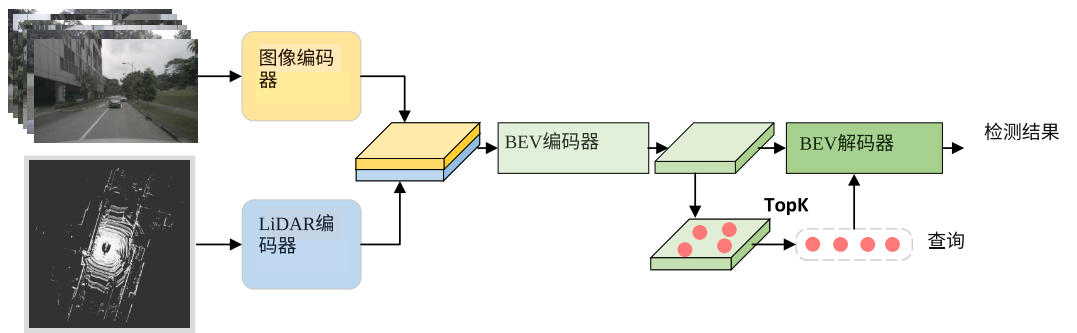
BEV 域中的融合(LSS),如BEVfusion、GraphBEV 将图像特征直接投影到统一的 BEV 平面,然后和 LiDAR 特征连接;该框架效率高,但是存在两个局限性:
- 信息压缩:沿高度维度压缩几何和纹理信息会导致特征模糊,进而导致漏检和回归精度降低 通过引入多视图融合中的多视图编码器-解码器解决这个问题,但是将 LiDAR 特征转换为正面视图的额外转换会严重破坏 3 D 空间关系,仍然会引起特征模糊
- 特征不对齐:传感器之间的不准确深度估计可能导致多模态 BEV 特征的空间偏差
-
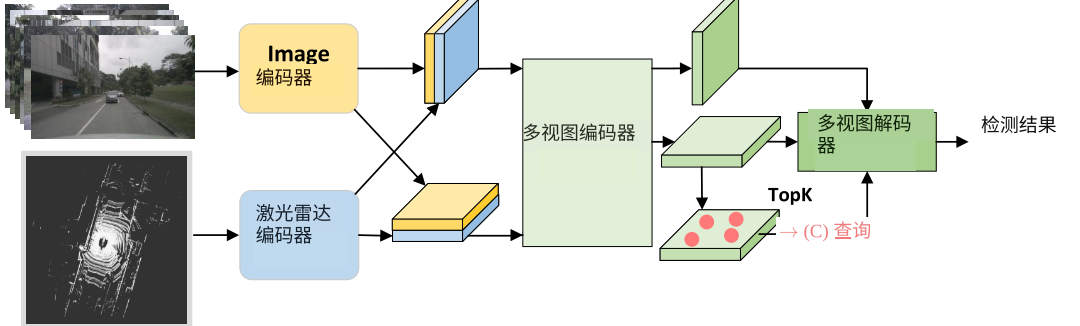
多视图融合,如Deep interaction、Deepinteraction++
-
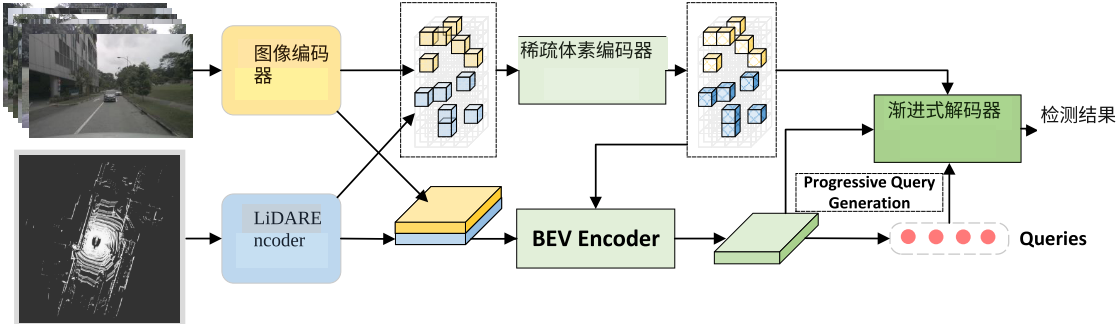
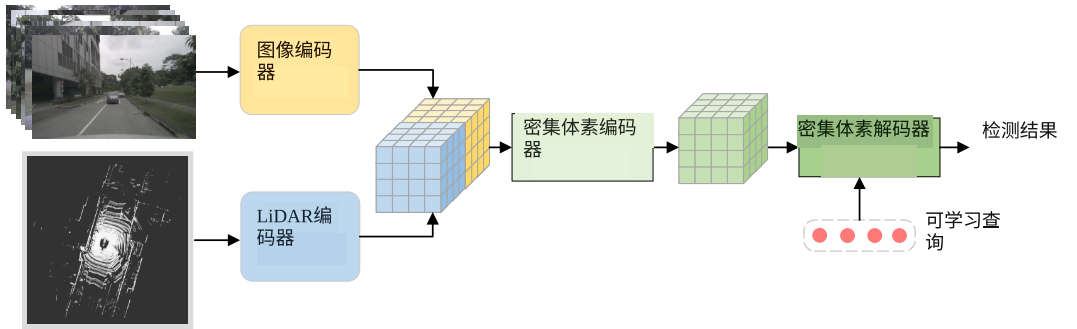
密集体素域中的融合,如 UVTR 探索了在统一的密集体素空间中进行融合,以利用更高维度的特征交互,同时避免信息压缩。理论上优于基于 BEV 的融合,但是面临多个挑战:
- 计算负担:密集体素的特征融合在内存和计算上都非常密集且昂贵,在大型驾驶场景中步数困难
- 查询生成困难:和 BEV 域相比,密集体素域中有更严重的背景前景不平衡和更高的维度使得标签分配和依赖于输入的查询生成变得复杂
- 特征不对齐:特征转换过程中,深度估计和 LSS 类似,会导致特征不对齐
-
稀疏体素和 BEV 域中的融合(本文方法)