简要介绍
Mamba端到端 3 D 检测器,这是完全基于点的方法,延续DETR 的方法,增加输入点的数量可以提升较多的 mAP
将 SSM 应用到 3 D 检测的挑战
-
将 Mamba 直接集成到现成的检测中无法取得好的结果。因为 SSM 是为处理一维序列数据而设计的因果模型,这使得它难以对无序且非因果的 3 D 点云进行建模
-
原始的 Mamba 块侧重于建模长久全局信息,但缺乏提取局部特征的能力,而局部特征对于点云学习非常重要。
-
之前的研究主要将 Mamba 用作单目标分析的编码器,对于复杂的场景级点云和检测任务,其潜力有待探索
本文贡献
- 设计了一种从局部到全局的扫描机制,并开发了 Inner Mamba 和 Dual Mamba,分别考虑了局部细节特征和全局空间表示
- 提出了一种查询感知 Mamba,通过可学习的查询解码场景进行上下文特征,并生成感兴趣对象的边界框
场景特征聚合器
点云的最新进展表明,同时捕获局部集合特征和全局场景信息至关重要。然而以往的方法主要使用 SSM 进行全局建模,导致缺乏细粒度细节。
为应对该挑战,提出例新的局部到全局扫描技术
内部 Mamba 块
给定一个无序点云序列,先使用 FPS 采样 K 个关键点,在使用 K 近邻采样 个近邻点,形成 K 个块
接下来需要聚合局部特征,过去的工作都使用 MLP 从每个块中学习,但他们在有效聚合局部特征方面存在困难
为了解决该问题,这里将局部特征掘视为一个序列到序列的生成过程,并使用 Mamba 模型提取块内的局部特征。
具体操作是,每个块内的点先被归一化,然后根据到关键点的距离排序。这些序列点被输入到一个轻量级的 mamba 块中,该块的维度和原始 Mamba 块相比有所减少,以生成新的特征序列。
最后使用最大池化获得每个块的嵌入,表示为 ,C 是嵌入维度
这里是 PointNet++中的做法,聚合局部特征;每个邻域图都被看作一个小序列,用 mamba 进行处理
这里,我的看法,用 mamba 在这些小的序列提取特征效果可能不好,因为不够长,Mamba 更适合提取长程依赖;我的建议让 mamba 块在所有的小序列之间提取出长程依赖关系
IEDA:因为每个块中的序列都是按照距离排好序的,不如直接把这个块内的点全部平摊开|或者聚合(感觉聚合会损失信息,不如直接平摊),作为一个 token,让 mamba 把每个块当作一个 token 处理,这样可以增加更多的块来增强 mamba 的提取能力 同时这也有点像,可以累计历史记录的卷积操作,可能有立于局部几何图形联系起来
双 Mamba 块
存在问题 为了编码点云数据,之前的工作 Point Cloud Mamba 建议翻转 token 顺序,同时使用前向和后向状态空间模型更好的捕捉全局上下文
然而由于点云的无序性和不规则性,简单的反转 token 顺序无法保证点云序列的因果依赖性,可能导致不可靠的结果
为了缓解该问题,提出双 Mamba 块,以全局视角模拟长程依赖
具体,将 视为 token,并根据其坐标将其排序为两种类别:最远和最近邻序
最远邻序:通过最大化序列中相邻点之间的距离来增强模型对空间分布的感知 最近邻序:确保相邻点保持空间邻近性,从而维持局部一致性
双 Mamba 块使用这两个分支来处理 FPS(最远邻) 和NPS(最近邻)token 序列,他们首先经过归一化和独立的线性投影
对每个序列,初始的 1 D 卷积将其转换为 ,然后将其投影到 (即 SSM 模块中),随后使用 对 进行离散化。最后将两个分支中对应的 token 相加,并通过一个线性层生成场景表示
解码器
存在问题 DETR-based 模型利用一组对象查询来提取用于对象分类和定位的特征。然而在 Mamba 模型中,直接把场景上下文作为前缀,并将其与查询连接会导致性能不佳,因为它难以捕捉独立查询的判别性特征。
为了解决该问题,引入了查询感知 Mamba 块,可有效建立可学习查询与场景特征之间的关系,以生成边界框
首先使用 FPS 从 K 个关键点中选择定义数量的 M 点来生成对象查询,确保这些查询点覆盖整个场景。对于这些点中的每一个,遵循 3 DETR 的建议,使用傅里叶变换将其空间坐标转换为位置嵌入 (傅里叶位置嵌入)
这些嵌入通过 MLP 处理,生成初始化的查询嵌入
具体,解码器有 D 个相同的块组成,每个块包含一个查询感知 Mamba 块和多个 MLP 层。查询感知 Mamba 块以框查询和场景上下文作为输入,在可学习查询的指导下从场景上下文中提取任务相关特征
每个查询序列 被输入到一个标准的 Mamba 块中,以模拟查询之间的依赖关系。过程表述如下:
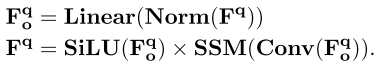
同时,场景特征和查询序列相同的处理过程。然后,通过将场景特征与查询嵌入相乘,将场景上下文集成到查询嵌入中,并将更新厚的查询经过多个 MLP 层。在 D 个解码过程之后,可以使用基于 MLP 的头部生成边界框和语义类别
训练目标-Loss
和 DETR 设置一致
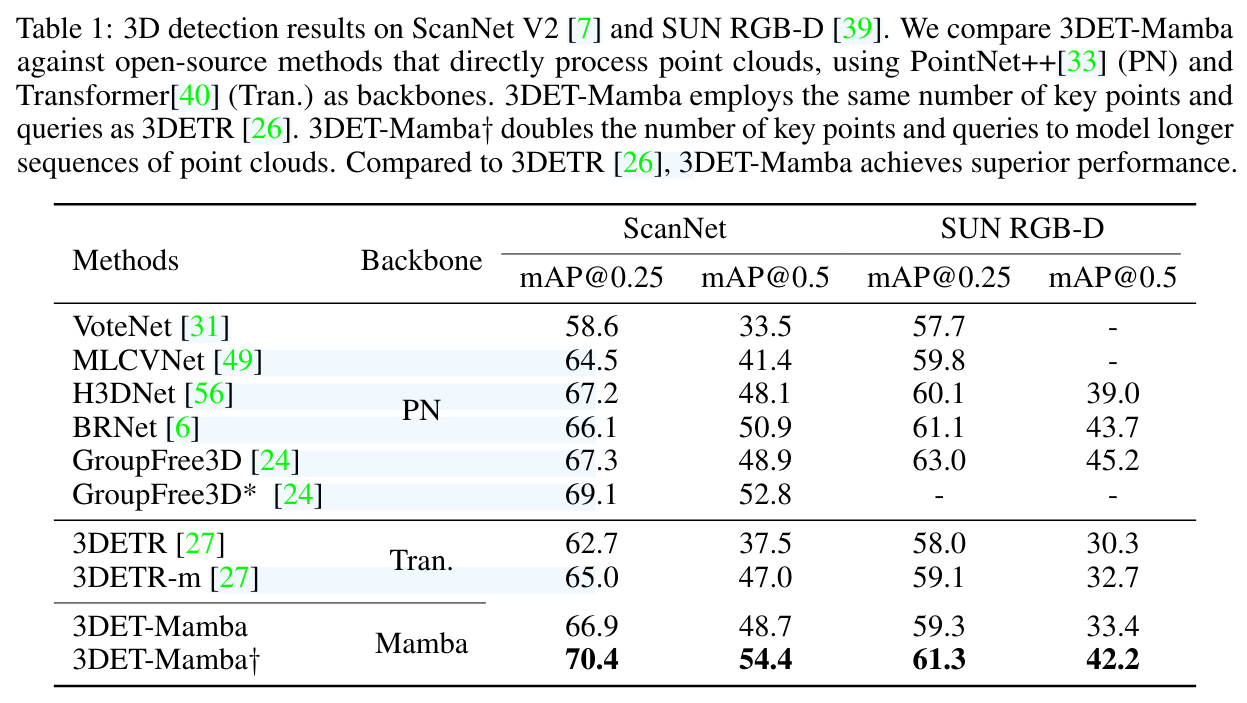
ScanNet 和 SUN RGB-D