简要介绍
- 多模态 LiDAR+Camera 融合,用 Transformer 融合 BEV 特征,anchor-free head,效果在 KITTI/nuScenes 都很强。
点云的稀疏性 由于点云的稀疏性,仅依赖激光雷达的方法在鲁棒的 3 D 检测中显然不足
例如,小型或远处的目标在激光雷达模态下难以检测;相比之下,这些目标在高分辨率图像中仍然清晰可见且易于区分
点云和图像的互补作用促使研究人员设计出利用两者优势的检测器,即多模态检测器
激光雷达-相机融合方法 大致有三类:
-
结果级 包括 FPointNet 和 RoarNet,使用现成的 2 D 检测器生成 3 D 提议,随后通过 PointNet 实现目标定位
-
提议级 包括 MV 3 D 和 AVOD,在区域提议级别进行融合,通过在每中模态中应用 RoIPool 来处理共享提议。
上述两种粗粒度的融合方法由于感兴趣区域(RoI)通常包含大量背景噪声,结果并不理想。
-
点云级 最近的工作大部分基于点云级融合,并取得了令人鼓舞的结果
首先基于校准矩阵在激光雷达点和图像像素之间建立影关联,然后同构逐点拼接的方式,利用相关像素的分割分数或 CNN 特征增强激光雷达特征
点级融合存在的问题
- 只通过逐元素相加或拼接的方式简单的融合激光雷达特征和图像特征,因此当图像特征质量较低时,其性能会严重下降
- 在稀疏的激光雷达点和密集的图像像素之间寻找强关联不仅浪费了许多具有丰富语义信息的图像特征,还严重依赖于两种传感器之间的高质量标定,而由于故有的时空未对准问题,这种标定通常难以获取
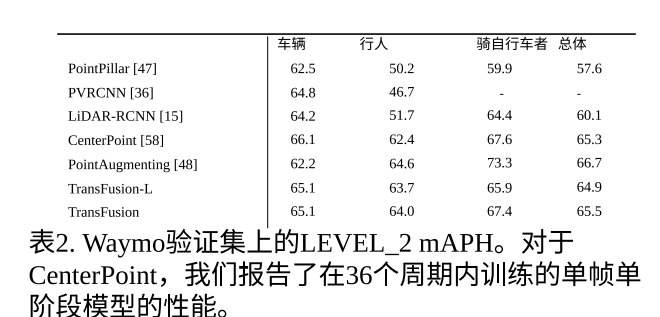
NuScenes
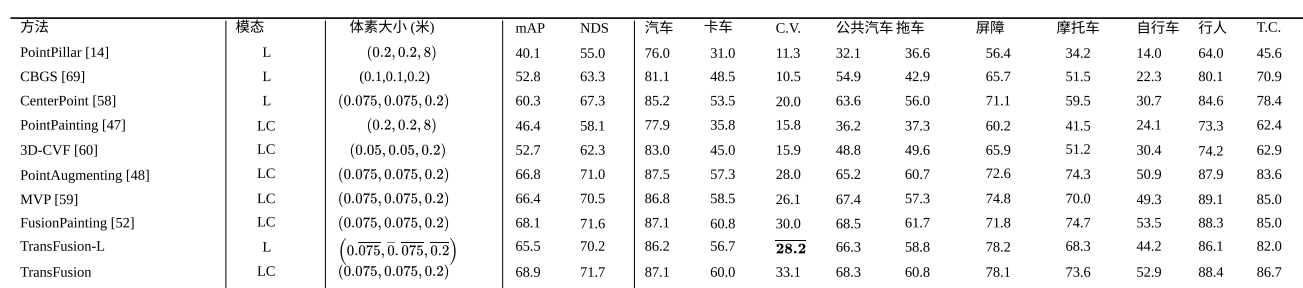
Waymo