分支界定法基本原理
分支界限法和回溯法的不同
-
求解目标:回溯法的求解目标是找出解空间树中满足约束条件的所有解(或一个最优解),而分支限界法的求解目标则是找出满足约束条就爱能的一个解(或最优解)
-
搜索方式不同:回溯法以深度优先的方式搜索解空间树,而分支限界法则以广度优先或以最小耗费优先的方式搜索解空间树
分支界限法基本思想
以广度优先或最小耗费(最大效益) 优先的方式搜索问题的解空间树
每个活结点只有一次机会成为拓展节点并一次性产生其所有儿子节点
儿子节点中导致不可行或非最优解的儿子节点被舍弃,其余儿子节点被加入活结点表中。如是最小耗费优先,或即欸但表需要重新排序
此后从活结点中取下一节点称为当前拓展节点,并重复上述节点拓展过程。这个过程一直持续到找到所需的解或活结点表为空时为止
广度优先和最小耗费优先的区别
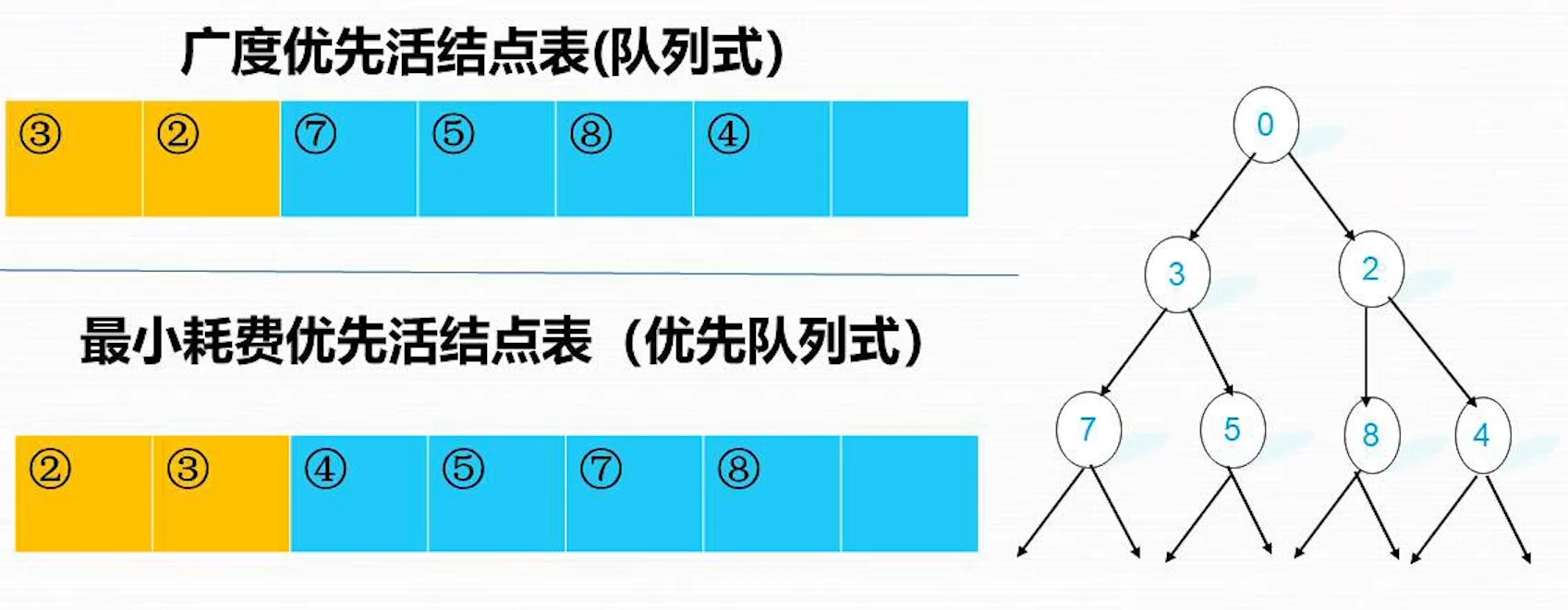
广度优先存储时按照层级内的左右位置顺序进行存储 最小耗费存储时层积内会按照优先顺序进行存储
常见的两种分支限界法
-
队列式(FIFO)分支限界法 按照队列先进先出(FIFO)原则选择下一个节点作为拓展节点
-
优先队列式分支限界法 按照优先队列中规定的优先级选取优先级最高的节点称为当前扩展节点
装载问题

队列式分支界定法
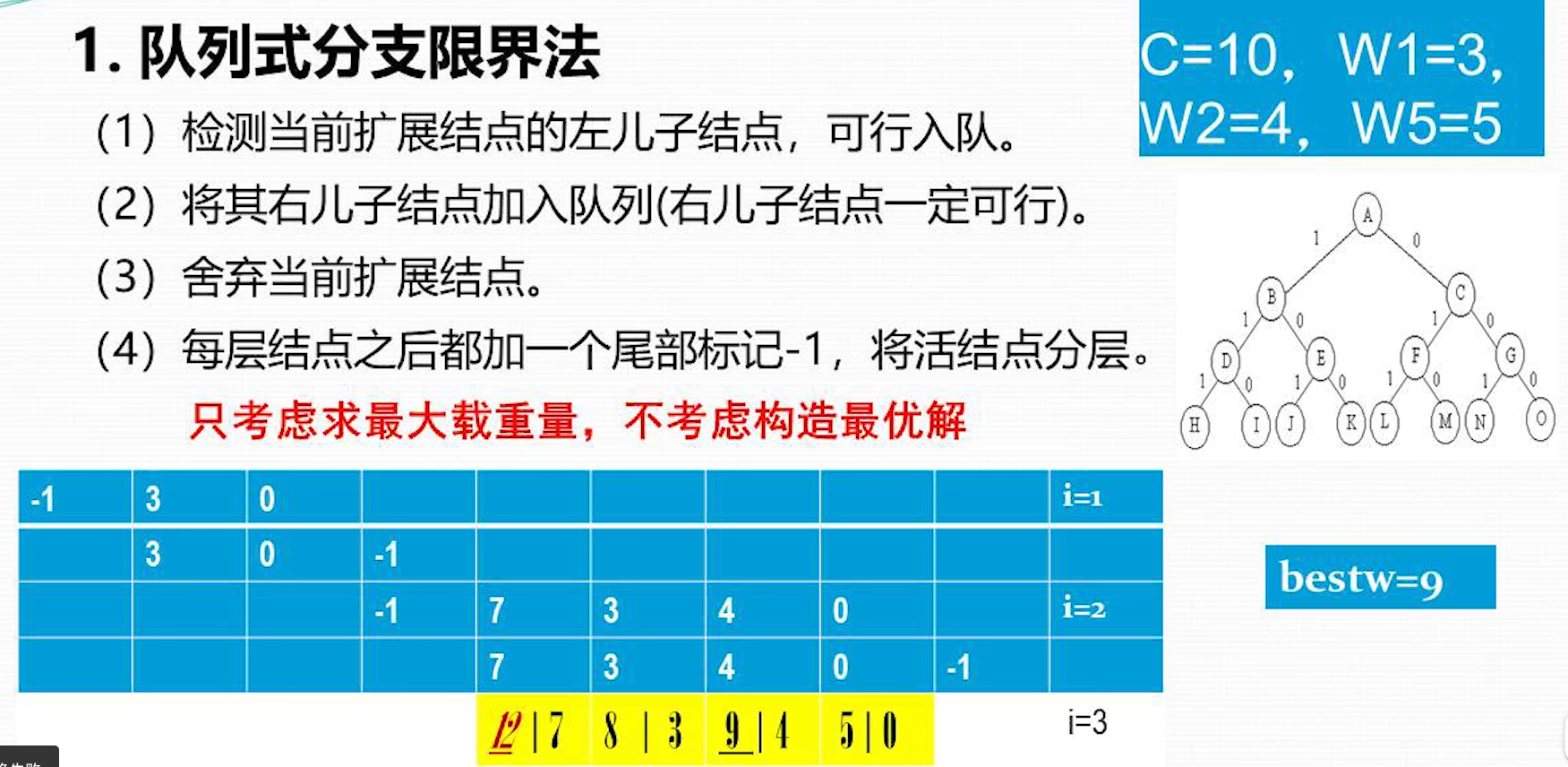
这个-1 标记是可变位置的,初始,第一个位置是-1,当检测到-1 时,把-1 挪到尾部
代码

先看 EnQueue 函数,它负责队列入队,同时会对叶子节点进行判定,保存最优解 bestw,且叶节点不加入队列
左边 Ew 是当前节点重量; While 循环判定左儿子节点,需要满足加上当前节点重量后,总重量少于上限c 右儿子节点不装当前节点,不会超过上限 c,直接入队 然后取下一个节点,判定是否是尾部标志-1,同时队列中是否还有剩余节点,有节点说明是分层标志,没有节点说明是结束标志 如果是分层标志,就再取下一个节点,得到下一层的第一个节点 如果是结束标志,直接返回最优值
算法改进 (右子树加入剪枝条件)
上述算法,右子树没有剪枝,效率太差
右分支无脑拓展,分支太多,需要加上剪枝
策略:设 bestw 是当前最优解;ew 是当前拓展节点所对应的重量;r 是剩余集装箱的重量。则当 时,可将其右子树剪去
为确保右子树成功剪枝,算法每一次进入左子树的时候更新 best w 的值。不要等待 i=n 时才去更新
代码

左分支:加上了判定最优 bestw 的代码,add 只添加非叶子节点 右分支:需要判定当前重量和剩余重量的和是否大于 bestw,且是非叶子节点
构造最优解

这个数据结构,构造了一个指向父节点的树,其中还加入判定当前节点是否是父节点的左子树的 LChild 标志,以及当前节点的重量,这样可以从叶子节点向上搜索最优解
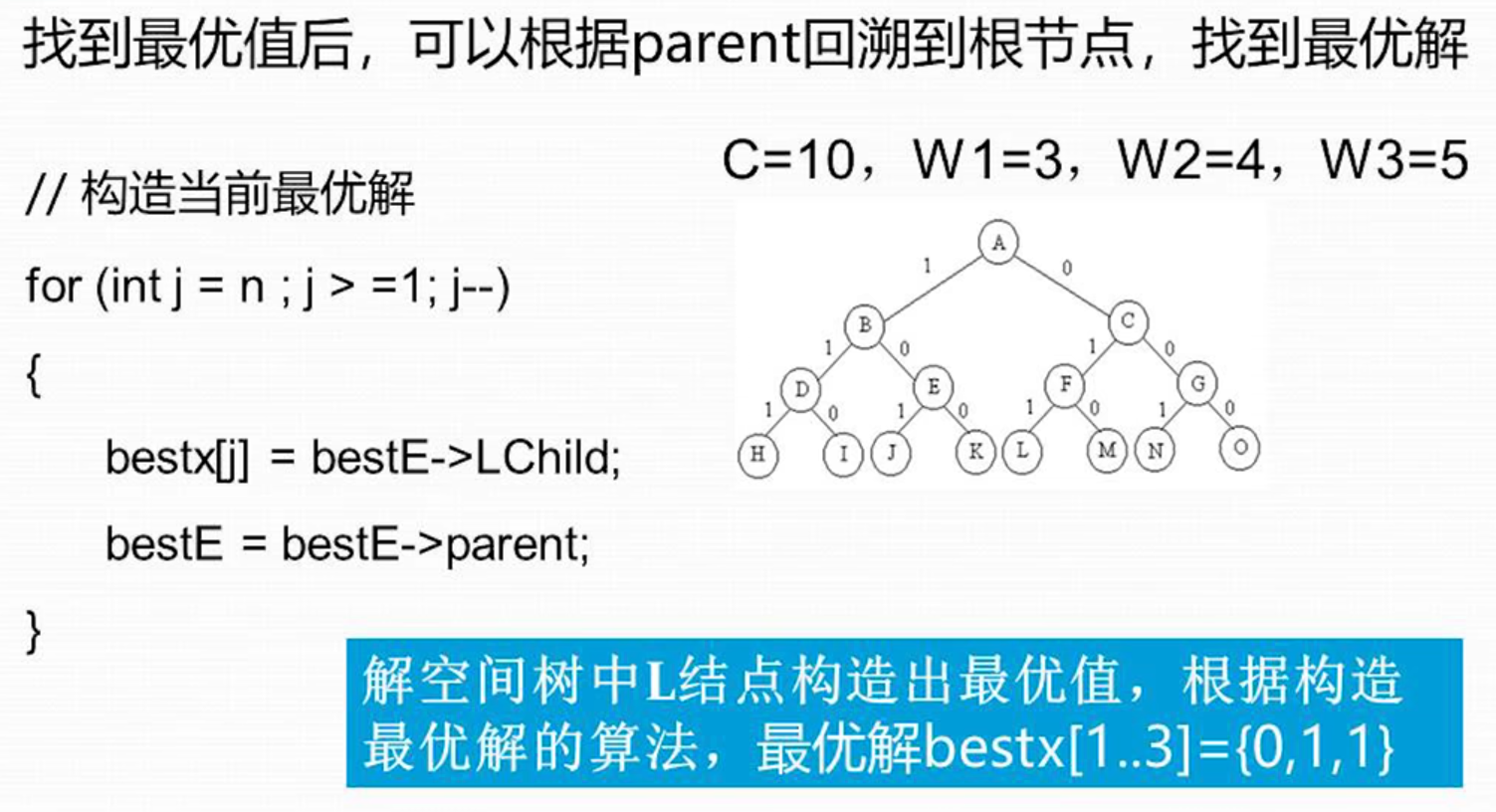
循环回溯到最优解
优先队列式分支界限法
用最大优先队列存储活节点表(大顶堆实现)
活结点 x 的优先解:根到节点 x 的路径相应的载重量+剩余集装箱重量之和
优先队列中优先级最大的活结点称为下一个拓展节点
以节点 x 为根的子树中所有节点相应的路径的载重量不会超过 x 的优先级 叶节点所对应的载重量与其优先级相同
因此:一但优先队列中有一个叶节点成为当前拓展节点,则可以断言该叶节点所对应的解即为最优解。此时可终止算法
注意:算法中叶子节点要进队列
模拟优先队列
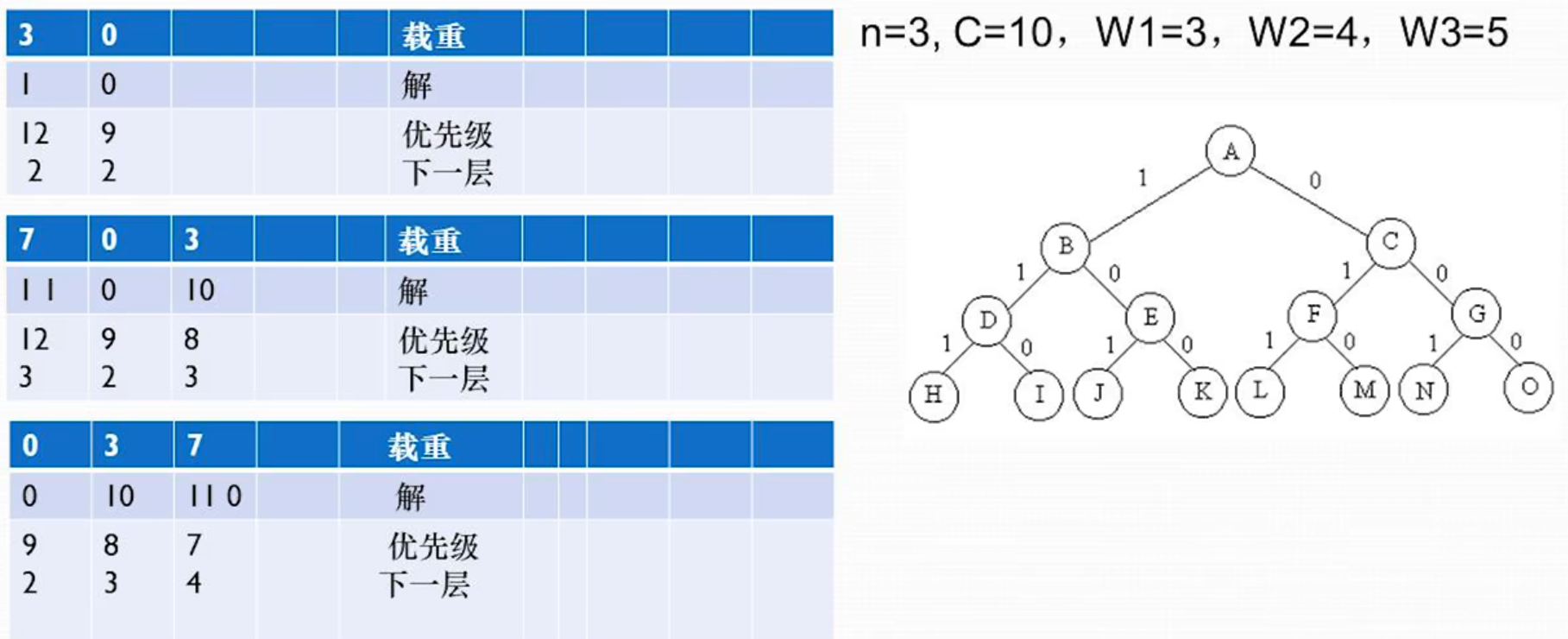
第一个分支重量是 3 或 0(w 1);优先级左分支 3+4+5=12,右分支 4+5=9;下一层都是第二层
BC 两个节点先展开 B 节点,展开是 7,3,优先级分别是 7+5=12,3+5=8;对应第二个表
C 节点展开 4,0,优先级是 9,5;优先级 5 已经小于当前层最优解 7,这个节点被优化掉了;只剩下 7,0,3,对应 DFE 节点;对应第 3 个表
依次向下拓展,每次从优先最高的节点拓展一次;判断优先级是否小于当前最优值,小于就不拓展这个子节点; 直到优先级最高的节点是最下层(上图第四层)的节点,这个节点就是最优值
布线问题
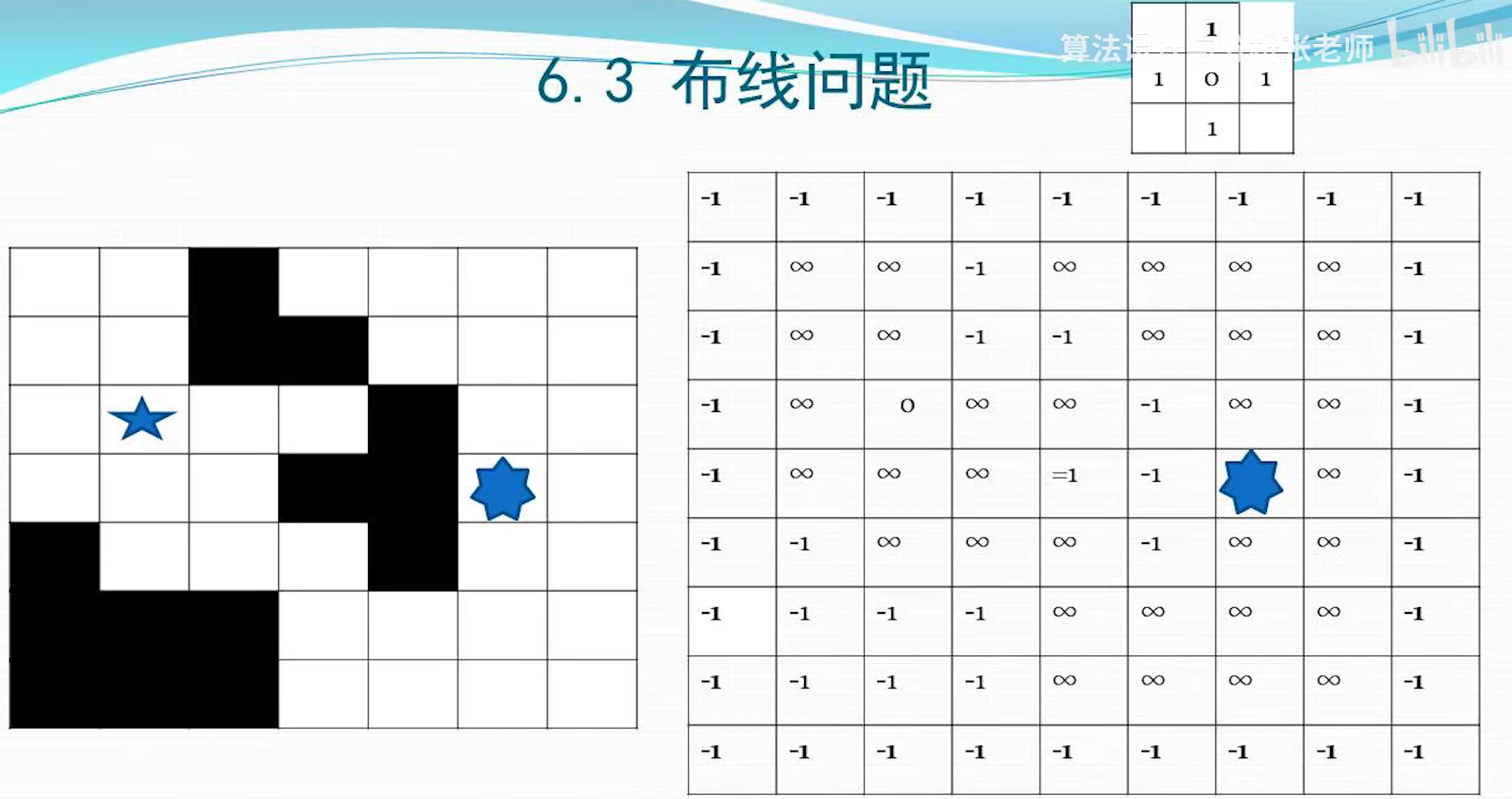
就是广度搜索求两点之间最短长度 -1 代表墙 初始所有可走的位置数值是无穷大
算法思想: 队列式分支限界法
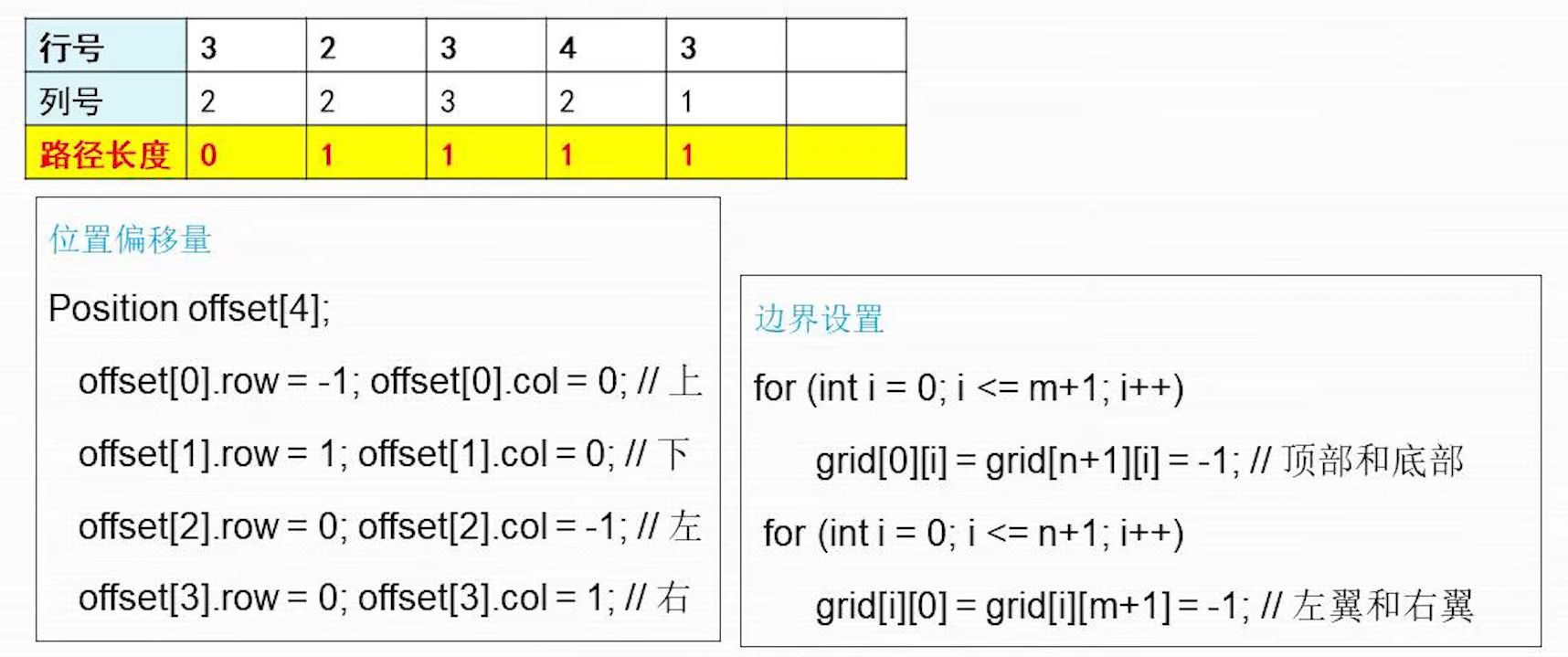
从出发节点开始,向上下左右四个方向拓展 拓展时的剪枝策略,拓展过去的最短路径长度必须小于之前得到的路径长度,才能进行拓展(所有可走的初始位置都是无穷大,保证第一次能走过去)
剪枝策略:新拓展的该位置路径长度小于该位置已经记录的值
代码

For 循环遍历所有邻居(上下左右); nbr. row, nbr. Row 是邻居的位置 接下来 if 判断从当前位置走过去的距离和原本邻居位置的数值,哪一个更小,决定是否添加新的节点到队列中
0-1 背包问题
算法思想 先进行预处理:将各物品依其重量价值从大到小排列
优先队列的优先解:已装物品价值+后面物品装满剩余容量的价值
算法:现价查当前扩展节点的左儿子即欸但。如果该左儿子节点是可行节点,则将他加入活结点优先队列中,如优于当前最优值,则更新当前最优值。当前拓展节点的右儿子节点一定是可行节点,仅当右儿子满足上界约束时(优先级大于当前最优值)才将它加入活结点优先队列。从优先队列中取下一个活结点称为拓展节点,继续拓展
当叶子节点为拓展节点 (当前优先级最高) 时,即为问题最优解, 算法结束
上界函数bound(int i)的计算

把剩余空间和剩余物品,按照最高重量价值的顺序依次放入背包中,最后剩下的空间,把下一个物品切割塞进去,得到剩余背包空间的价值上限,作为剪枝的估计
优先队列中节点包含的信息
- 当前背包价值、重量
- 节点的优先级(价值上界)
- 左孩子标志
- 父节点地址
- 本节点对应的下一个要装入背包的物品编号
代码
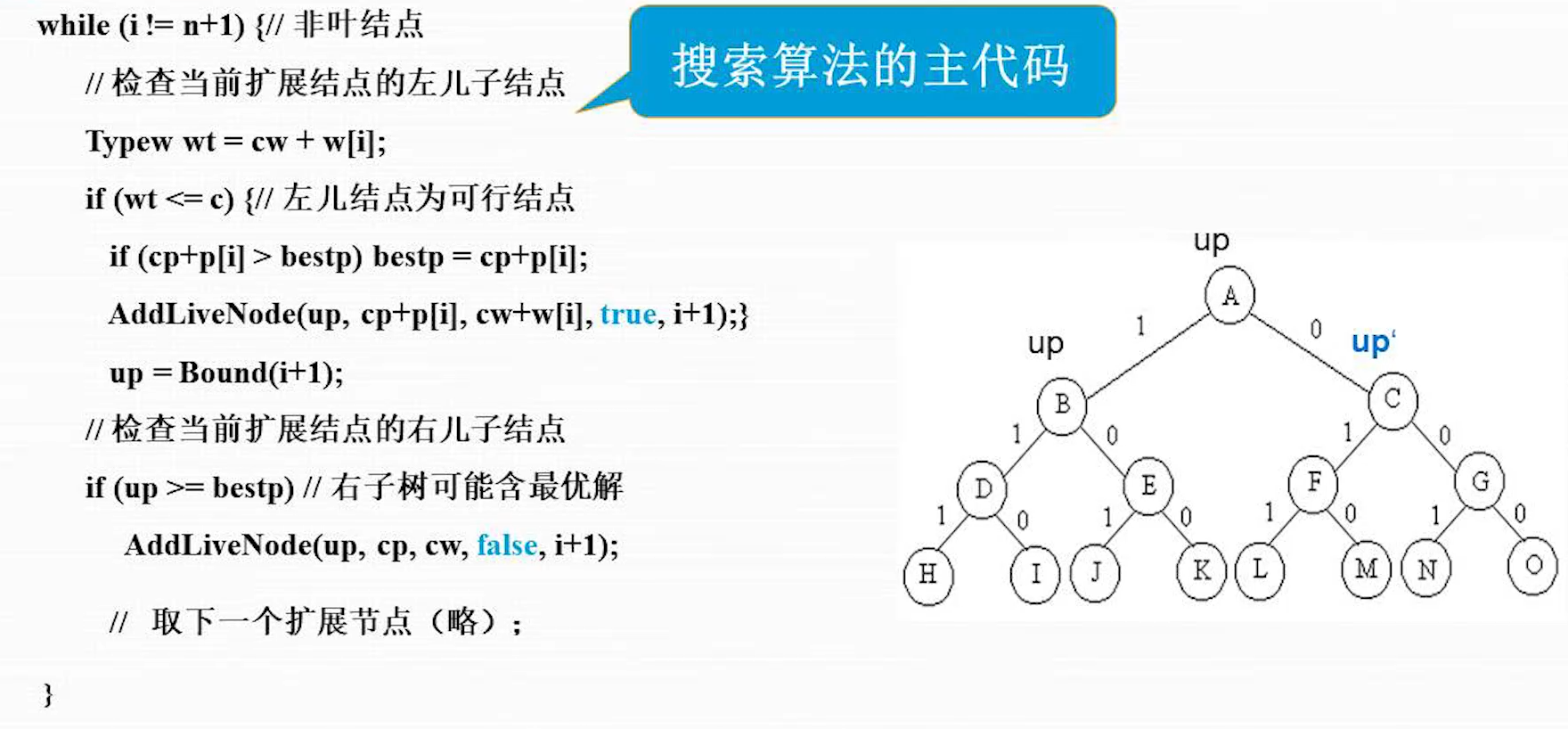
这个要拓展到叶子节点:第n 层;循环在 n+1 时停止 wt 是加上当前节点的总重量,重量小于背包容量 c,可以进入左儿子节点;先比较加上当前物品的总价值是否更优,再添加子节点到队列,其中 up 是优先级, 是总价值, 是总重量,true 是左儿子节点标记,i+1 是下一个物品是第 i+1 个物品 然后计算 i+1优先级就是右子树的优先级(价值上界),因为右子树不选择当前物品,优先级会变化;左子树优先级和父节点一致,因为选择了当前物品,价值上界没有变化 右子树的优先级(价值上界)必须高于最优解,才可能有更优解
思考 如果优先级设定为当前位置的背包内物品机制,算法是否可以在一个叶子节点成为拓展节点时算法结束? 不可以,当前背包价值,不能反应后续背包的价值上限
最大团问题
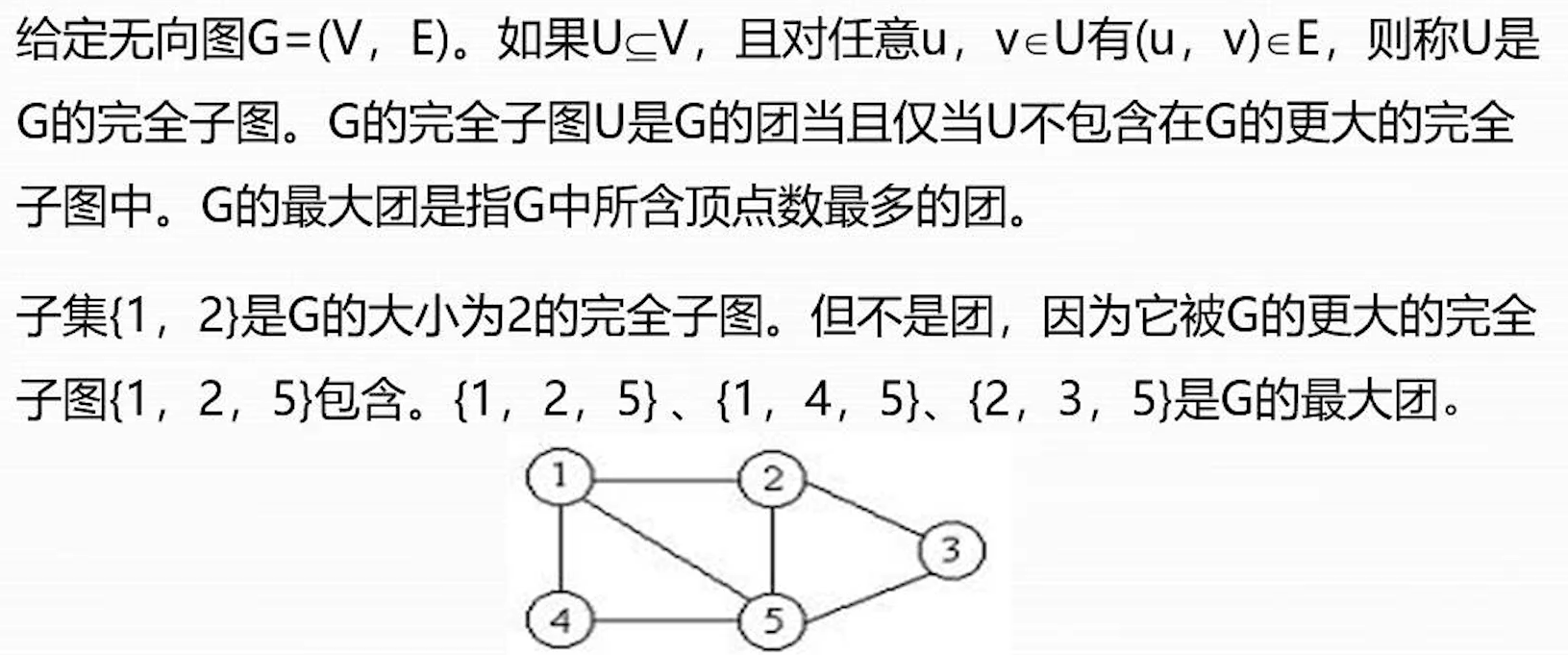
上界函数
用变量 cliqueSize 表示与该节点相应的团的定点数;level 表示节点在自己空间树中所处的层次;用cliqueSize+剩余定点数作为定点数上界 upperSize 的值,他是优先队列元素的优先解
解空间树是子集树
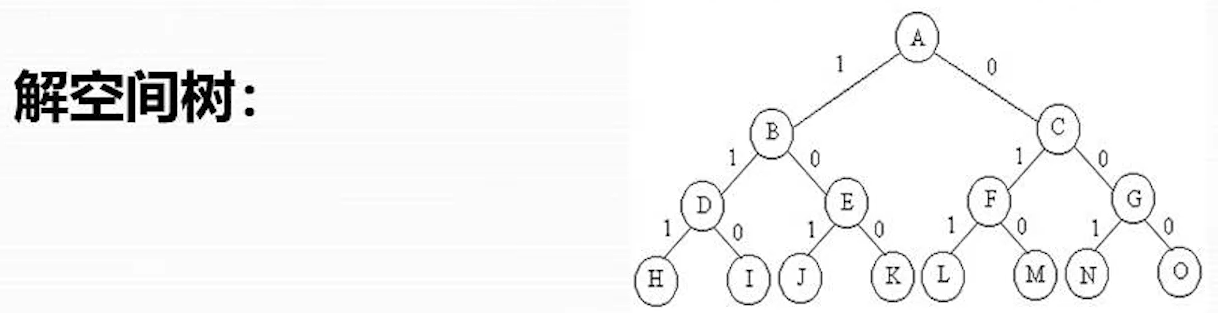
算法思想
- 子集树的根节点是初始扩展节点,其 cliqueSize 的值为 0
- 在路哦栈内部节点是,首先考查其左儿子节点。在左儿子节点处,将顶点 i 加入到当前团中,并检查该顶点与当前团中其他顶点之间都有边相连。有则将它插入活结点优先队列,否则就不是可行节点
- 接着继续考查当前扩展节点的右儿子节点。当 upperSize>bestn 时,有子树中含有最优解,此时将右儿子节点插入到或哦即欸但优先队列中
- 从优先队列中取下一个活结点,重复(2)(3),直到一个叶子节点成为拓展节点,找到最优解,算法结束
旅行销售问题

解空间树是排列树
- 指定一个城市作为起点
- 把 n-1 层看作叶子节点
因为路线是环路,初始城市是哪一个都可以
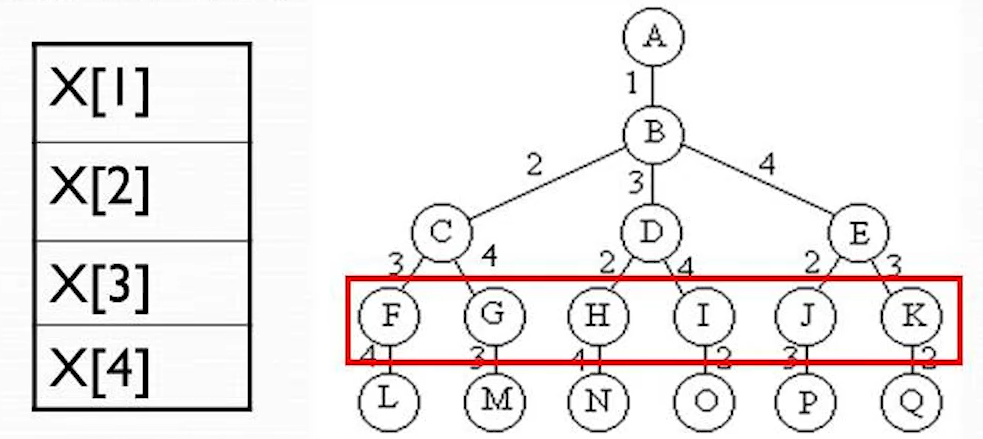
算法描述
算法开始时创建一个最小堆,用于表示活结点优先队列 堆中每个活结点的优先级为:cc+lcost。cc 是出发城市到当前城市的路程,lcost 是当前顶点(当前城市)最小出边+剩余顶点(城市)最小出边和(禁忌除外)
每次从优先队列中去除一个活结点成为拓展节点(s 层节点), 当 s=n-2 时,拓展出的节点是排列树中某个叶子节点的父节点 该叶节点相应一条可行贿赂且费用小于当前最优解 bestc,则将该节点插入到优先队列中,否则舍去该节点
当 s<n-2 时,产生当前拓展即欸但的所有儿子即欸但。可计算可行儿子节点的优先解 cc+lcost 及相关信息。当 cc+lcost<bestc 时,将这个可行儿子节点插入到活结点优先队列中
该拓展过程一直持续到优先队列中取出的活结点是一个叶子节点为止
最小出边(禁忌除外)的解释 对于刚拓展处得顶点,其前已经选的所有顶点是禁忌的(不能选)|就是不能走回头路
对于未拓展出的顶点,其前已经选择(顶点 1 除外)的顶点是禁忌的 | 就是说在选择下一个顶点的时候不能选已经走过的,1 顶点能选,是最后构成环路的时候选
其实就是在表格里面,已经到达的城市的列是不能选的,但是第一个城市是例外;可以如果到第一个城市是最短距离,是可以选的
算法演示
LB (下限)=当前路径长度+当前拓展出的顶点及其后顶点可选最小出边和
这个是计算出当前节点的优先级,根据当前节点计算出粗略的整个路径的长度下限,下限越低,优先级越高;这个下限是不准确的,一个粗略值
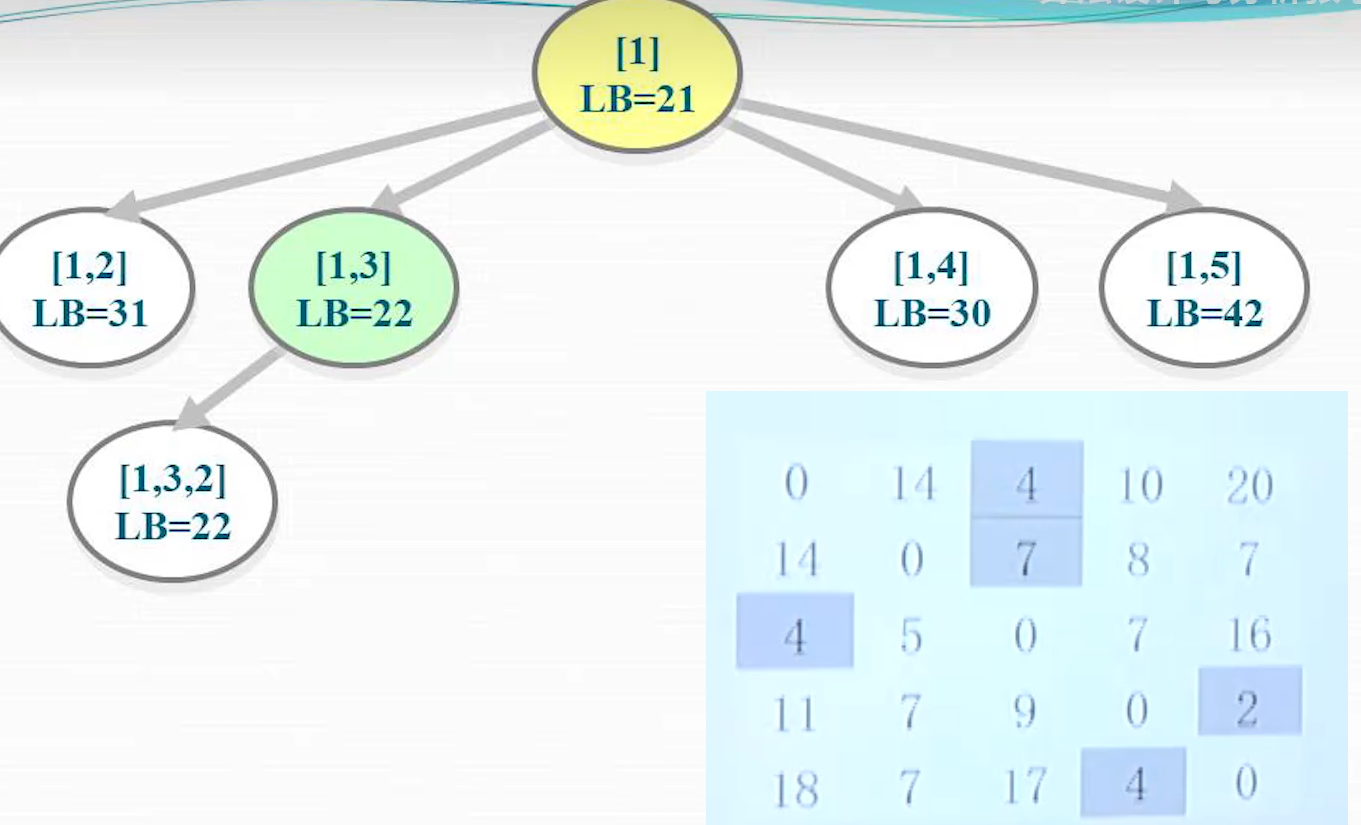
具体计算,
- 第一个城市是例外,直接计算每一行最小值就可以
- 两个城市的时候因为需要避免回头路问题,第一列要屏蔽掉,然后屏蔽掉选择的路线的行和列;如 1,3 ,屏蔽掉第一列,第一行,第三列,从剩余的数据选择每一行最小值,再加上已经走过的 1,3 代表的数值,组成 LB
- 其余情况,去掉所有路线所在的行和列(不需要去掉第一列),从剩余的数据中找每一行最小值,再和已走过的距离加到起来;如 1,3,2, 屏蔽掉第第 1,3 行,第 2,3 列,剩余每行最小值:第二行的 7,第四行的 2,第五行 4,和为 13,加上 1 到 3 和 3 到 2 的距离 4+5+13=22
小节
- 队列式:活结点是一个队列,新拓展处得满足条件的活结点追加在对位。这里需要加入层次标志 (如-1) ,或记录下层编号在活结点中
- 优先队列式:活结点表示优先队列,一般使用对(大顶堆或小顶堆)存储,优点是只需要 时间复杂性完成插入或者删除(取顶对节点,即优先级最高的节点)
- 构造解方法,活结点通过记录其父节点地址,即左孩子标志,在找到最优解时,回溯方法找到最优解。也可在拓展出的节点中记录构造的解,如问题规模比较大时,应考虑压缩存储
- 分支限界法的剪枝方法: (1)对于子集树,左右分支剪枝策略不同 (2)对于排列树,n 叉树,剪枝策略相同
- 算法的结束控制: (1)队列式分支限界,活结点表为空 (2)优先队列式,叶子节点成为扩展节点(在确认后面的活结点不存在更好的解)或队列为空。通常叶子节点加入优先队列中 (通常是叶子节点被放入后,又被取出,说明叶子节点是最优的)