算法总体思想 动态规划算法和分治法类似,其基本思想也是将待求解问题分解成若干个子问题 但是经过分解的得到的子问题往往不是互相独立的,不同子问题的数目常常只有多项式星级,在用分治法求解时,有些子问题被重复计算了许多次
这也是为什么,分治法要求子问题必须独立;否则大量重复计算会浪费大量时间
如果能够保存已解决的子问题的答案,而在需要时在找出以求得的答案,就可以避免大量重复计算,从而得到多项式时间算法
动态规划和分治的相同点、不同点
相同点:
- 当问题规模较小的时候, 答案直接可得或者很容易解决
- 问题可分
- 小问题答案可以合并成大问题答案
不同点:
动态规划解决的问题存在大量重复,分治的子问题相互独立
动态规划基本步骤
- 找出最优解的性质,并刻画其结构特征(最优子结构性质)
- 递归的定义最优值
- 以自底而上的方式计算出最优值
- 根据计算最优值时得到的信息,构造最优解
矩阵连乘问题

可以发现,矩阵乘法使用不同的计算顺序有不同的乘法计算次数,我们希望找到计算次数最少的方式
上述乘法式子有五种计算顺序,乘法计算次数如下

第二种乘法计算次数最少,也是我们需要找到的计算顺序
完全加括号的矩阵连乘积可递归的定义为:
- 单个矩阵是完全加括号的
- 矩阵连乘积 XS 级完全加括号的,则 X 可表示为 2 个完全加括号的矩阵连乘积,即 Y 和 Z 的乘积并加括号,即 X=(YZ), Y 和 Z 也是完全加括号的
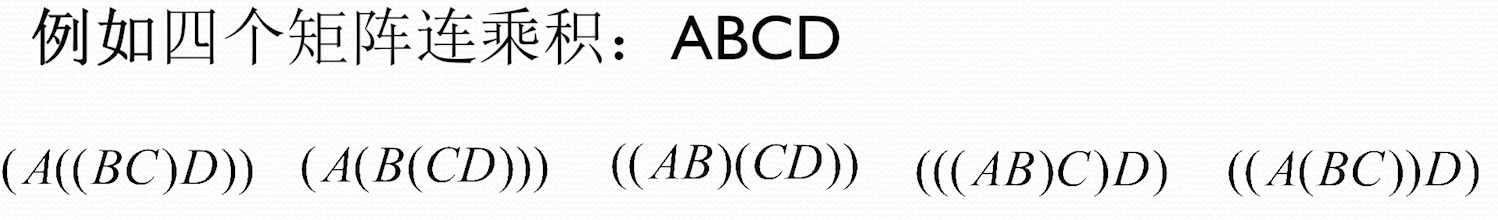
这里规定的矩阵乘法用括号来限制计算顺序,两个矩阵相乘可以表示乘(YZ),也包括((AB)(CD))这种更上一级的形式
矩阵连乘问题描述
- 给定 n 个矩阵 ,其中 与 是可乘的,. 考查这 n 个矩阵的连乘积
- 由于矩阵乘法满足结合律,所有计算矩阵的连乘可以有许多不同的计算次序。这宗计算次序用加括号的方式确定
- 若一个矩阵连乘积的计算次序完全确定,也就是说该乘积已完全加括号,则可以依次序反复调用两个矩阵相乘的标准算法计算出矩阵连乘积
如何确定计算次序,抱枕需要的连乘次数最少? 穷举法 列出所有可能的计算次序,并计算出每一种计算次序相应需要的数乘次序,从中找出一种数乘次数最少的计算次序 穷举法-算法复杂性分析 N 个矩阵的连乘积,设不同的计算次序为 . 因每种括号方式都可以分解成两个子矩阵的加括号问题:, 故 的递推式如下:
可以发现穷举法计算复杂度非常高,这种方案不可行
动态规划
- 首先分析最优解的结构 考查计算 A[i, j]的最优计算次序,设这个计算次序在矩阵 和 之间段考, 则其相应完全加括号方式为$$ (A_{i},A_{i+1}\dots ,Aj)=((A_{i},A_{i+1},\dots,A_{k})(A_{k+1},A_{k+2},\dots,A_{j}))
m[i,j]=\begin{cases} 0 &i=j \ min_{i\leq k<j}{m[i,k]+m[k+1,j]+P_{i-1}P_{k}P_{j}} &i<j \end{cases}
> 这里递归的时,需要找到 k 的值保证 $m[i,j]$ 最小 3. ==以自底向上的方式求最优解== - 对于 $1\leq i\leq j\leq n$ 不同的有序对 $(i,j)$ 对应不同的子问题。因此,不同子问题的个数共有:$$ \left(\begin{array}{ll} n \\ 2 \end{array}\right)+n=\Theta(n^2)- 动态规划算法解此问题,可以举其递归式以自底向上的方式进行计算
- 保存已保存的子问题答案,每个子问题值计算一次,需要是只要查一下子问题的结果,避免大量重复计算,最终得到多项式时间的算法
算法描述

先初始化 =0, 代表只有一个矩阵时,相乘次数为 0 同时为计算规模为 2 的矩阵乘法,创造条件;此时 这也为规模为 3 的矩阵乘法创造了条件,一次完成所有矩阵相乘的规模 代表当前划分节点是 i,即 i 到 j 之间所有矩阵相乘 For 循环从 i+1 到 j-1, 即把i 到 j 的连乘矩阵从中间拆开,拆开的都是更小规模的问题,可以利用 m 中乘的次数计算出在当前维持拆开需要的乘法的次数,遍历到其中更小的计算次数,把拆开的节点更新到 k 中
算法复杂度分析 算法主要计算量取决于算法中子问题的数量(应为需要把所有子问题的乘法次数算出来),已知为 ,求每个子问题的最优值的时间复杂性 (即 k 控制得循环次数最大值),因此算法的计算时间上界为 . 算法所占用的辅助空间显然为 (m 数组大小)
计算过程示例
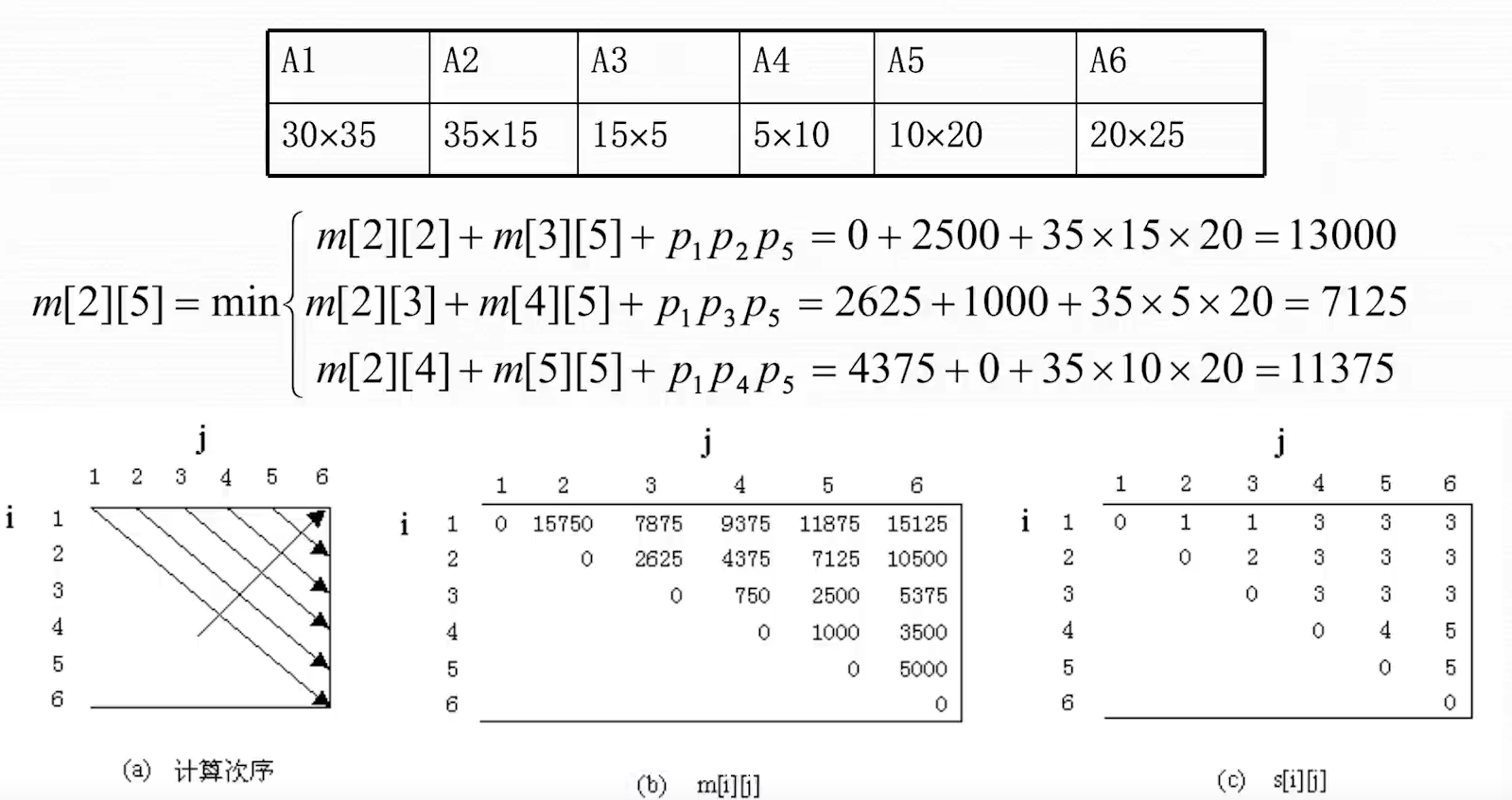
对照代码,先计算出 的值。然后找到从 i 到 j 之间断开的乘法次数最小值,即代码中 k 控制的 for 循环 中保存了从 i 到 j 的连乘矩阵从那里断开,乘法次数最小
- 递归算法构造最优解 用来把得到的 S 中的结果,展示出来
递归算法打印最优解
void Traceback(int i, int j, int **s)
{
if (i==j) return ; //只有一个矩阵
Traceback(i, s[i][j], s); //断开之后,左半部分
Tracebacj(s[i][j]+1, j, s); //断开之后,右半部分
cout<<i<<","<<s[i][j];
cout << "and" << s[i][j]+1<<","<<j<<endl;
}动态规划算法的基本要素
两个基本要素:最优子结构、重复子问题
最优子结构
- 矩阵连乘计算次序问题的最优解包含值其子问题的最优解。称为最优子结构性质。最优子结构是可用动态规划算法求解的前提
- 问题的最优子结构性质证明: 先假设由原问题的最优解导出的子问题的解不是最优的。 在设法证明这假设下口构造出比原问题最优解更好的解导致矛盾
- 利用问题最优子结构性质,以自底向上的发放时通过子问题的最优解逐步构造出整个问题的最优解
注意:同一个问题可以有多种方式刻画他的最优子结构,有些表示方法的求解速度更快(空间占用小,问题的维度低)
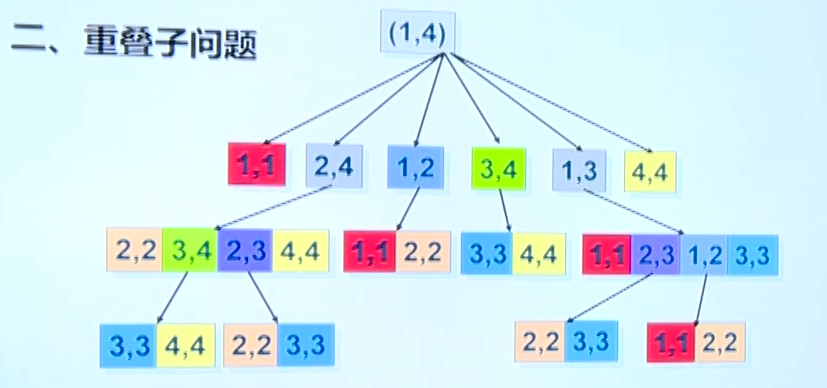
重叠子问题
问题需要能够分解成大量的子问题
备忘录方法
- 备忘录方法与直接递归方法的控制结构相同
- 区别:
- 备忘录方法为每个求结果的子问题建立了备忘录
- 求解一个子问题时先检查是否已有答案,避免重复求解
递归算法-最少连乘次数问题

使用 来保存计算过的连乘次数,如果 直接返回结果,不需要在计算
动态规划算法的特点
- 阶段性 计算最优值是分阶段进行的 例如矩阵连乘,先计算规模为 2,再计算规模为 3
- 无后向性 只已经计算处得子问题的答案不能在更改 如 Dijkstra 算法有后向性
数字塔问题
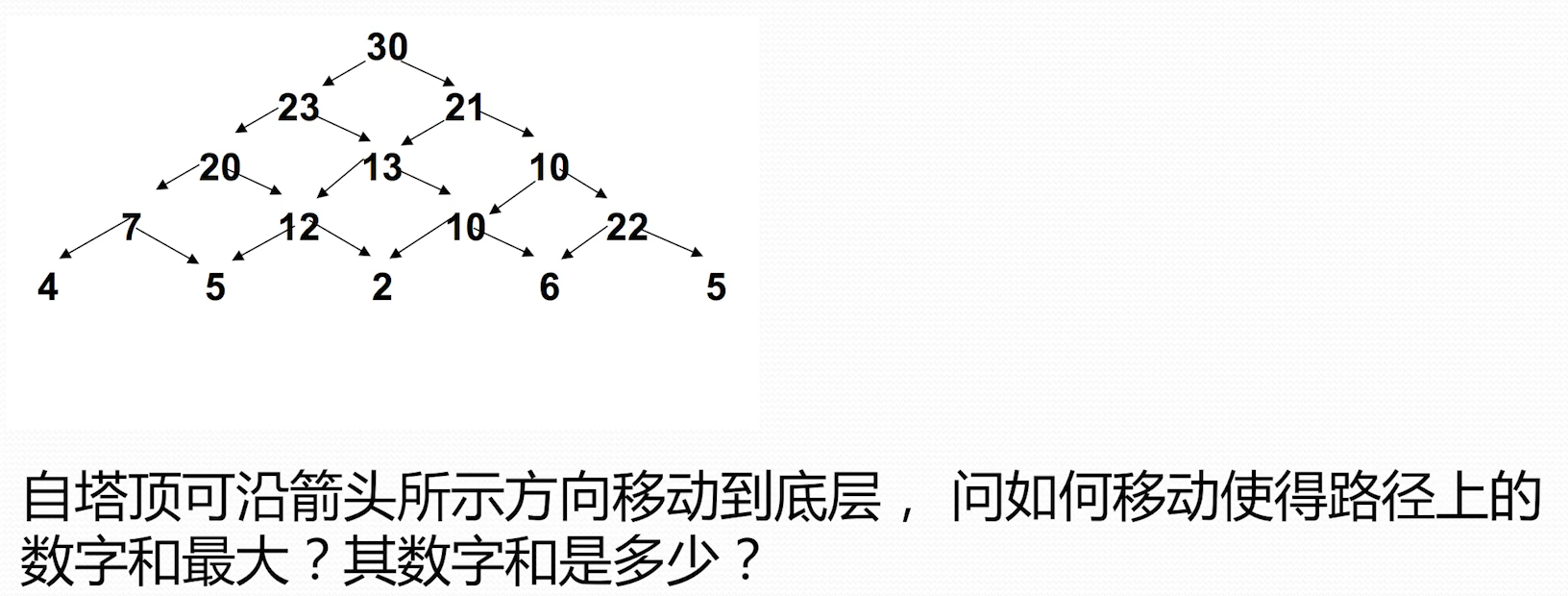

使用自下向上的方式,累加,保存最大的累加值
(2)最优值的递归定义
(3) 自底向上的昂是计算出最优值

(4) 构造最优解
Traceback(intt **a,int **s,int i, int j)
{
if(i==n) output i.j;
else{
out put i,j;
if (s[i][j]==a[i][j] + s[i+1][j])
Traceback(a, s, i+1, j);
else
Traceback(a, s, i+1, j+1);
}
}最长公共子序列

- 最长公共子序列的结构

这里从后向前,如果元素相同,一定是这个序列的最后一个元素 不相等分两种情况,其中一个序列的最后一个匀速不再公共子序列,需要去掉 当递归计算时,这两种情况也会包含两个序列最后一个元素都需要去掉的情况
可见,2 个序列的最长公共子序列包含了这 2 个序列的前缀的最长公共子序列。因此,最长公共子序列问题有最优子结构性质
- 最优值的递归定义 用 记录序列的最长公共子序列的长度。其中:
递归关系如下:
3. 自底向上的方式求最优值
在所考虑的子问题空间中,总够有 个不同的子问题

这里 是表示长度为 i 和长度为 j 的序列的最长子序列的长度,他是从 开始一步一步向前计算出来的;他是一个记录状态的动态规划表格
其中 b 是辅助构造最优解的信息表,记录 状态是从那个状态转变过来的
中间判断又分为三种情况
- 当前字符相同 , 此时最长公共子序列加了一个字符,他是从 这个状态过来的
- 当两个字符不相等,他们需要从 和 这两个状态中选择一个更长的长度保存
- 构造最优解

根据状态转移的标记,倒着找到最大子序列中的元素
例子

最大子段和
问题描述

枚举法解决问题

算法描述

枚举法的优化算法
优化使用前缀和做差的方式计算子段和,时间复杂度为
算法描述

分治法解决方法
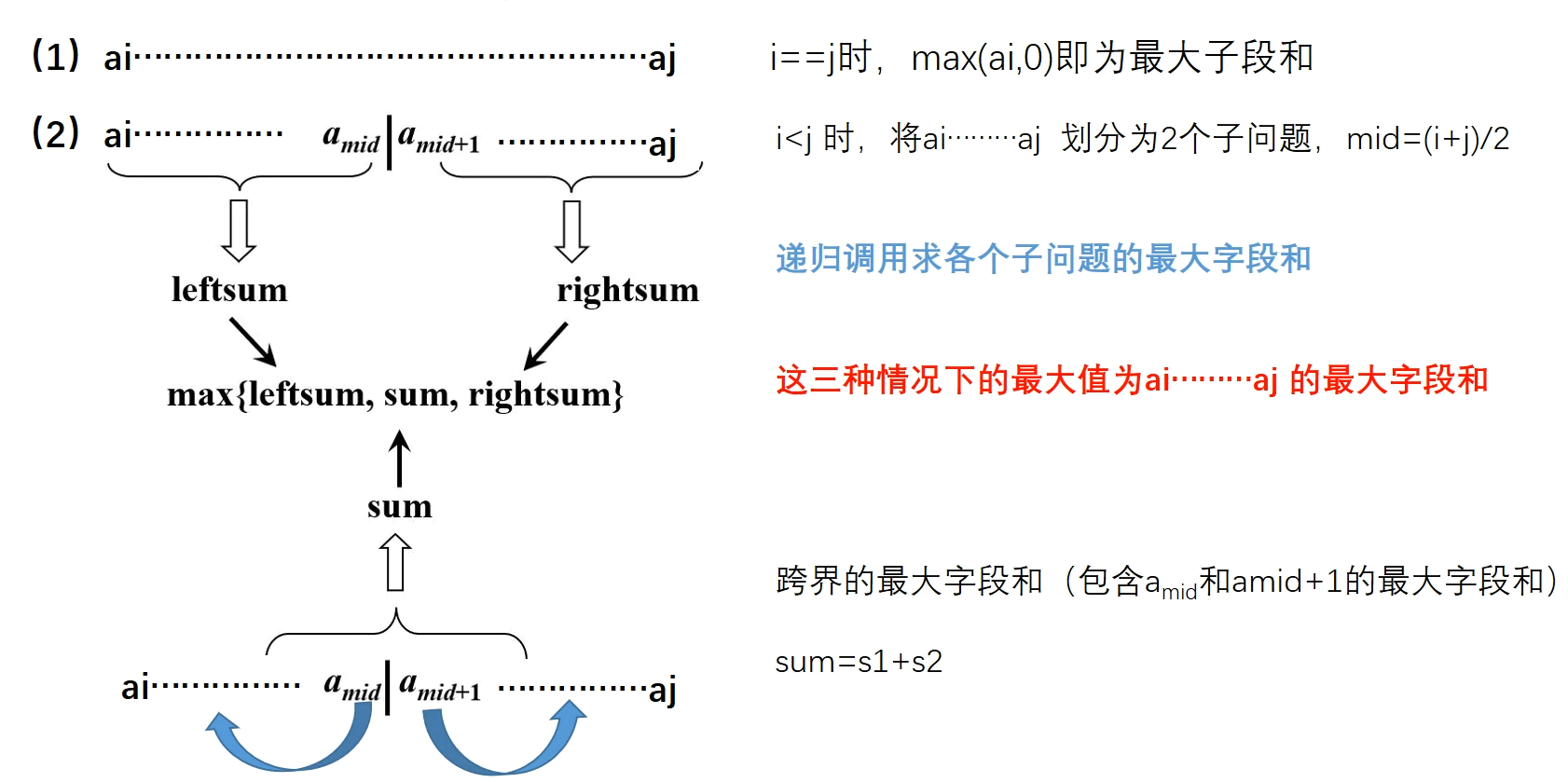
分成两个子问题,递归计算出两个字段的最大字段和,在计算出以中轴元素为起点向左右两个字段延伸的子段的最大和,比较三者谁更大
举例

算法描述

动态规划解决方案
- 首先定义一个一般化的子问题,而且改变参数可表示任何一个子问题。
提出:以 为字段结束元素的最大子段和问题,最大字段和用 表示,令 ,可表示任何一个子问题
如果这些子问题的最大子段和都求出来,则 就是原问题答案
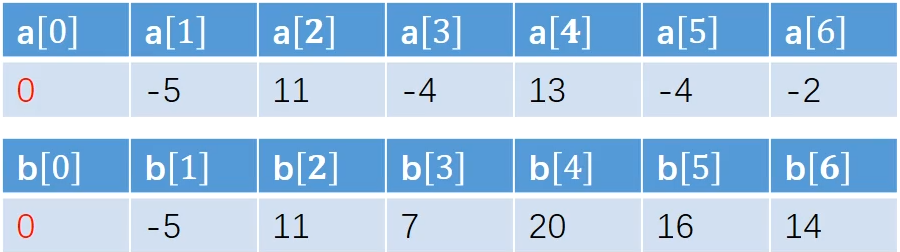
实际上 中保存了以 为结尾的最大子段和 计算时只有两种情况需要比较,一个是把当前字符作为结尾和前面的子段拼接起来,;另一个情况是当前元素直接作为一个新的子段,这时候他也是结尾元素,
-
找出最优解的性质,刻画其特征 以 为结尾的最大字段和 ,包含了以 为结尾的最大字段和 (当 ) 如果 ,就没有子问题了
-
递归定义最优值 设 是以 元素结尾的最大子段和
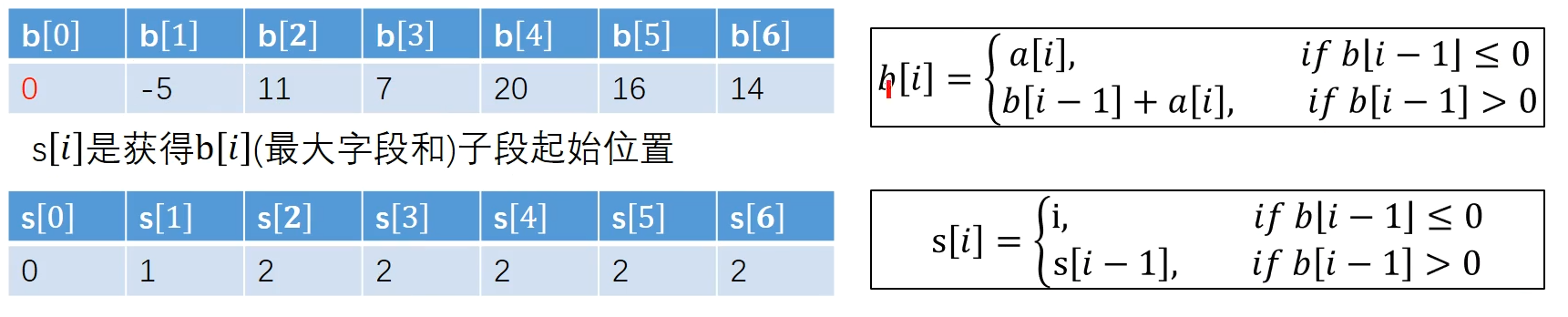
这样 就是 的子段区间

因为 之和前一个元素的 有关,为节省空间, 用变量 b, s 记住前一个元素即可
- 算法设计求最优值

-
求最优解 比较简单,见上面算法代码
-
算法复杂度分析 时间复杂度:循环次数共 n 次, 或
空间复杂度:
算法拓展(最大矩阵和、最大 m 子段和)
最大矩阵和
的数字矩阵,求最大子矩阵和 算法思想:
-
将矩阵第 i 行第 j 行各元素,按列求和得到一行(一维数组)
-
在该一维数组中找到最大字段和
-
所有可能的 i,情况下,得到的最大子段和为答案
-
时间复杂度:
行 i,j 的选择需要两层循环遍历 ,复杂度 ,对遍历出来的行,求完和,在进行最大字段和求解,时间复杂度
最大 m 子段和问题
N 个正数(可能为负数)组成的序列 ,确定 m 个不相交的子段,使 m 个子段和达到最大。M=1 是就是前面的最大子段和

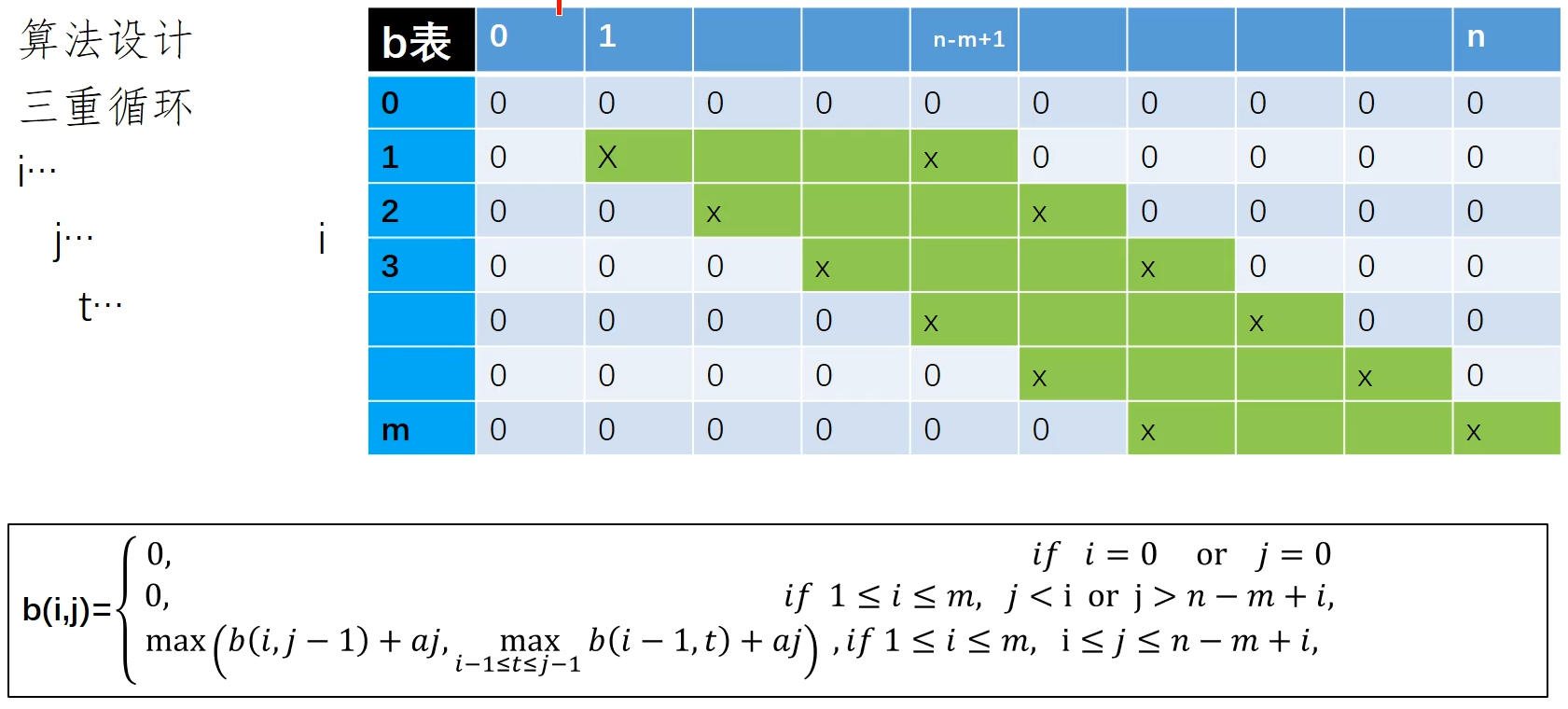
动态规划 该处问题的一般化定义:前 j 项最大 i 子段和问题,且第 i 子段包含 元素,, 表示前 j 项最大字段和,则问题的最优值
- 找出最优解性质,刻画其特征,b (i, j)

这个问题解决,需要把 m 的大小逐渐增大到问题规定的大小 状态转移方程,一个是把当前元素拼接到当前子段上, 一个是当前元素自己成为新的子段,替换掉原来的最后一个子段,;因此前 i-1 个字段和就可以在 之间找一个最大字段和值代替(i-1 保证至少有 i-1 个元素可以分成 i-1 段)
- 递归定义

第二个条件是保证最少有 m 个字符,且还要保证剩下 m-i个字符,剩下的字符一个是为后面 m-i 段保留字符,另一个是这些数值在表格中不会参与最终结果的计算,为了减少计算量而不计算
填写表如下
算法描述

总结
- 最大子段和
- 枚举法-时间复杂度 , 优化后 (使用前缀和)
- 分治法-时间复杂度
- 动态规划-时间复杂度
- 算法推广
- 最大子矩阵和:二维变一维,求最大字段和
- 最大 m 段和: 的定义非常重要,含义是前 j 个元素的最大 i 段和,而且第 j 元素是第 i 个子段的尾元素
终点理解递归定义: 可并入第 子段和单独作为第 i 个子段两种可能 算法可以进一步改进,如构造最优解,改善空间复杂度
- 完整代码见张老师B 站专栏
凸多边形最优三角剖分
- 用多边形顶点的逆时针序列表示凸多边形,即 表示具有 n+1 条边的凸多边形
- 若 与 是多边形上不相邻的 2 个顶点,则线段 称为多边形的一条弦
- 多边形的三角部分是将多边形分割成互不相交的三角形
- 有多边形的边和弦组成的三角形上的权w(即三边和)。要求确定该凸多边形的一个三角剖分,使得该三角部分中诸三角形上权之和最小
在多边形顶点中三角剖分之后,所有三角形边长和最小
三角剖分的结构及其相关问题
- 一个矩阵连乘表达式的完全加括号方式相应于一颗完全二叉树,称为表达式的语法树。例如,完全加括号的 6 矩阵连乘积 所对应的语法树,如图 a。凸多边形 的三角剖分也可以用语法树表示
如凸 b 7 顶点的凸多边形的三角剖分可用图 a 所示的语法树表示
这里利用三角形的一个边在凸多边形上,作为母节点,把其他两条边作为两个子节点,依次散开
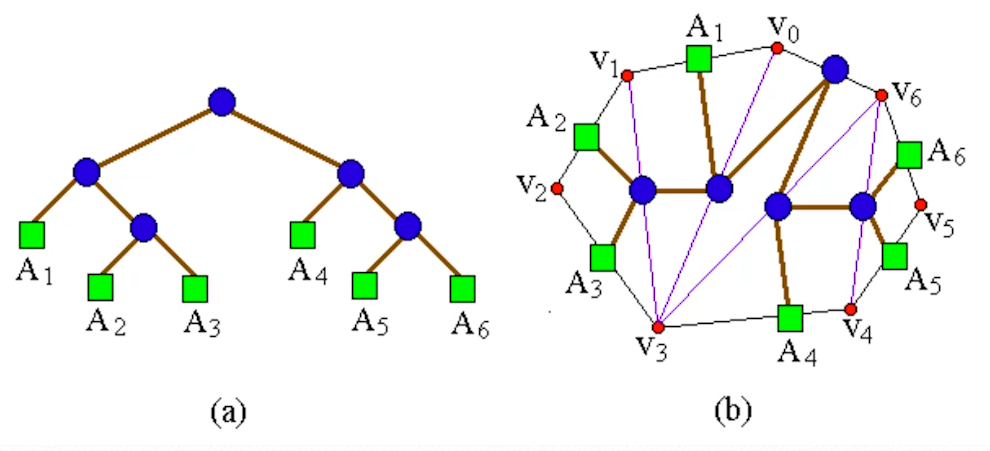
矩阵 对应多边形中的一条边 。一条弦 ,对应矩阵连乘积
最优子结构性质

对一个多边形,进行一次最优剖分,会把图形分解成两个子问题,子问题在进行最优剖分,存在最优子结构性质
重复子问题
有, 不同的分割方式,也会产生一样的形状的三角形
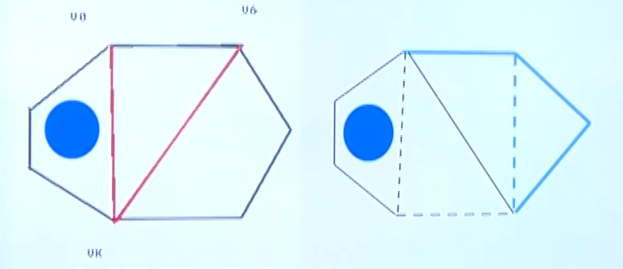
最优三角剖分的最优值递归定义
- 定义 为凸子多边形 的最优三角剖分所对应的权函数值,及其最优值
- 设退化的多边形即只有一条边 ,其权函数值为 0,即
- 目标:凸(n+1)边形的最优权值为
- 当 时凸子多边形至少有 3
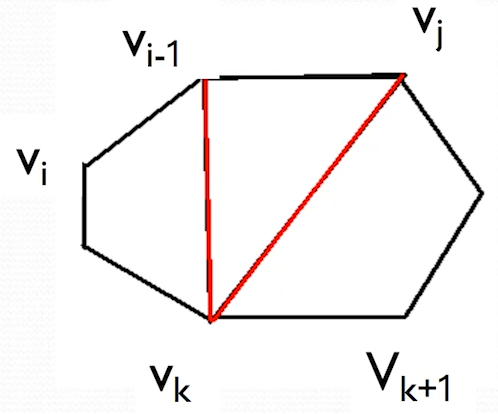
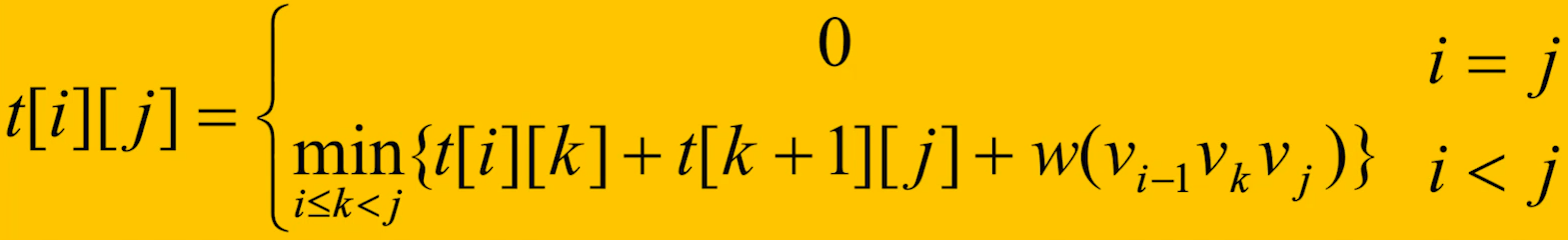
t 代表的是边,而 V 代表的是点,3 个点有两条边,因此 t 表示边索引比点少一个,即点 i 到 j 的边是
多边形游戏-动态规划

1. 分析最优解结构,刻画其特征
- 问题一般化定义:多边形中,从顶点 开始,长度为 (链中有 j 个顶点) 的顺时针链 可表示为:
- 如最后依次合并运算在 处发生 ,则将链 分割为 2 个子链 和 ;其中p(开始位置,链的长度)
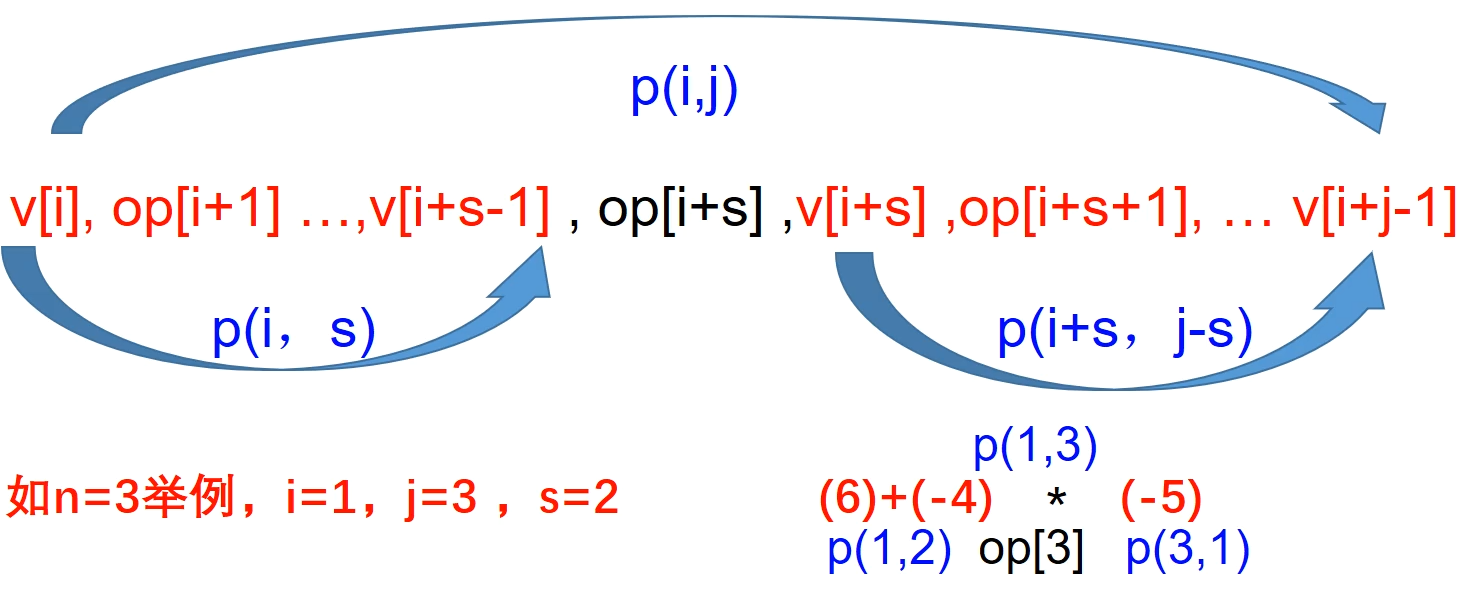
关键是把问题划分成子问题,这里直接假定最后一次运算在 i+s 处,这样左右两边就变成了子问题。
最优子结构 设子链 的合并得到的最小值 a 和最大值b 设子链 的合并得到的最小值 c 和最大值d 则 的取值 m 如下:
- 当 时,有
- 当 时,有
主链最大值和最小值可由子链最大值和最小值得到,满足最优子结构
重复子问题 关于重复子问题,显而易见,即是不同的划分子问题的方式,也有可能包含相同的子问题
2. 递归定义最优值
定义 链合并后的最小值 ,最大值为
定义在 处断开为两个子链(链的最后一次运算), 此时 和并后最小值记为 ,最大值记为
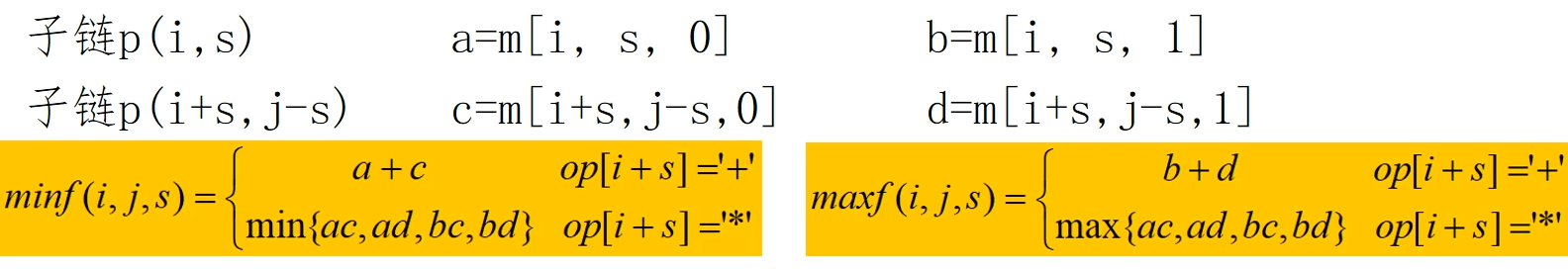
这样可以可以得到在 i 到 j 之间某个位置最为最后合并运算的最大最小值;s 遍历从 i 到 s+j-1 可以得到 i 到 j 之间最大最小的运算值,保存到 m 数组中
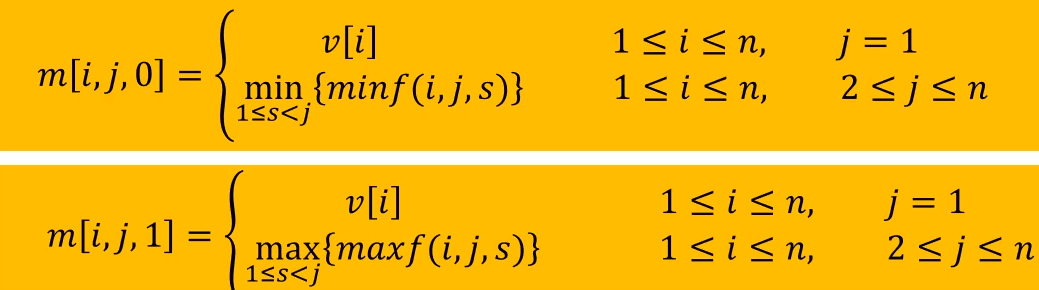
M 数组 i代表子链的起始位置,j 反映了子链的规模的,计算 j 规模的 m 矩阵的值,需要计算 s 规模和 j-s 规模的 m 矩阵的值,而这都是比当前规模更小规模的问题,已经在之前计算出来了
3 .自底向上计算最优值
根据最优值递归定义,先设计函数 MinMax (int n, int i, int s, int j, int &minf, int &maxf)
求出 链最后一次计算在 发生(断开位置), 和并后(删除所有边)的最小值 minf(i, j, s), 最大值 maxf (i, j, s)
注意子链 中, 可能大于顶点编号 n,需要转换为 范围顶点编号,使用公式 的对应位置
算法描述

a, b, c, d 都是从 m 矩阵取出来的。S 和 j-S 都是分割之后的子问题的规模, 都小于当前问题的规模,其值已经在之前计算出来了
根据如下递归定义,求出最优值
注意第一次断开有 n 中方式,在这 n 中可能中取得最大得分才是问题最优值
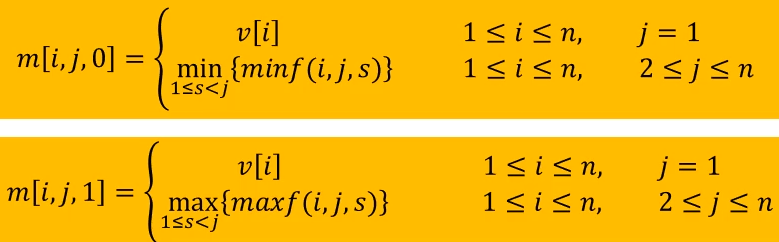
算法描述

规模为 1 的 m 矩阵输出初始化为对应的链中的数值 j 控制的循环控制问题规模,问题规模逐渐增加到问题的规模 i 控制得循环是遍历整个链中的每一个节点,以每一个节点作为规模为 j 的子链的起点 S 控制的循环是断开位置,根据规模 j 从 1 到 j-1,保证子链长度至少是 1
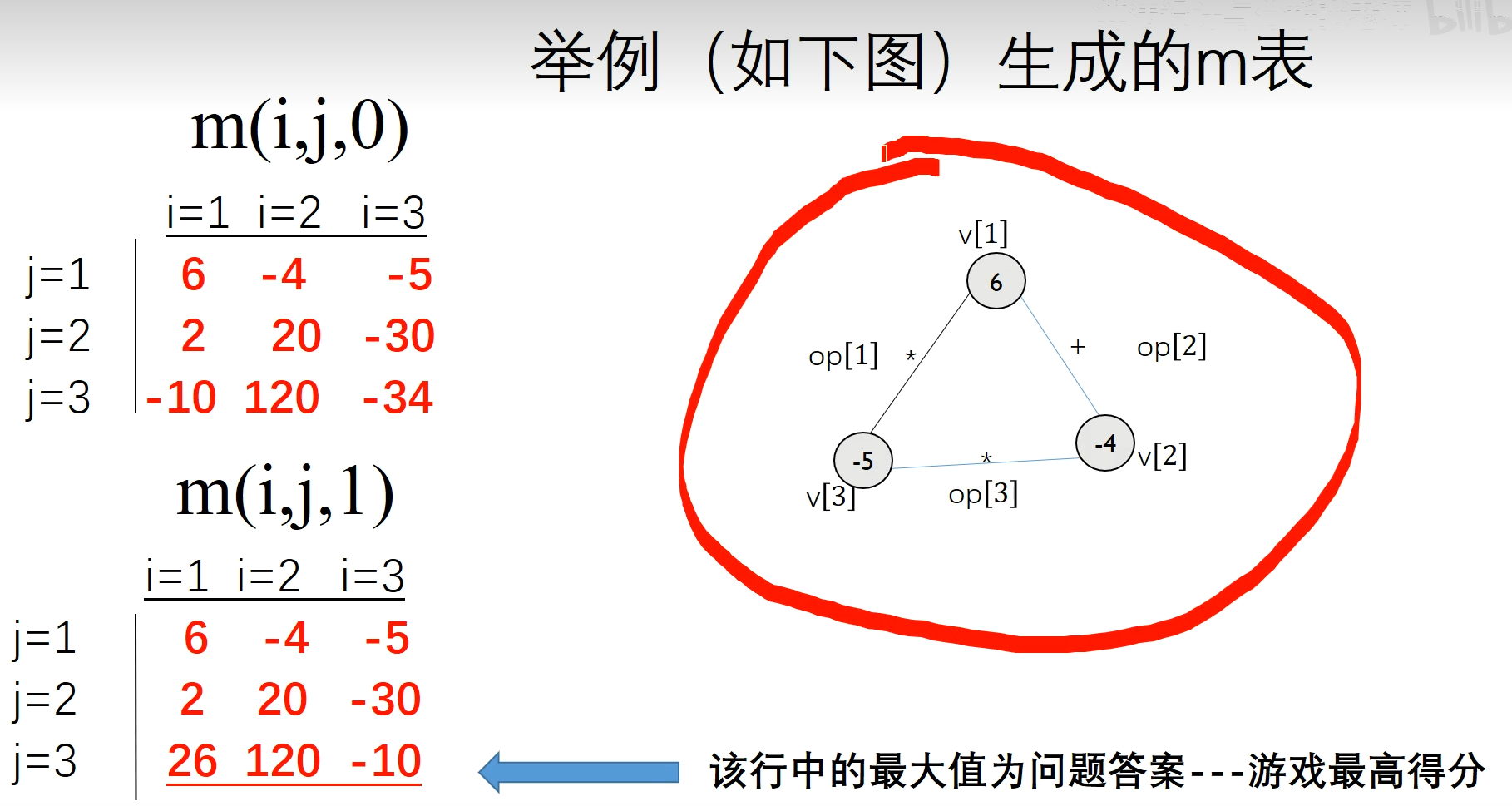
举例
4. 构造最优解
- 可参照矩阵连乘问题的算法
- 可求最优值算法中记录取得最优值的断开位置
- 设计递归算法可构造出最优解
- 有难度,尝试完成本算法
5. 算法分析
- 时间复杂度
- 空间复杂度
6. 程序运行截图

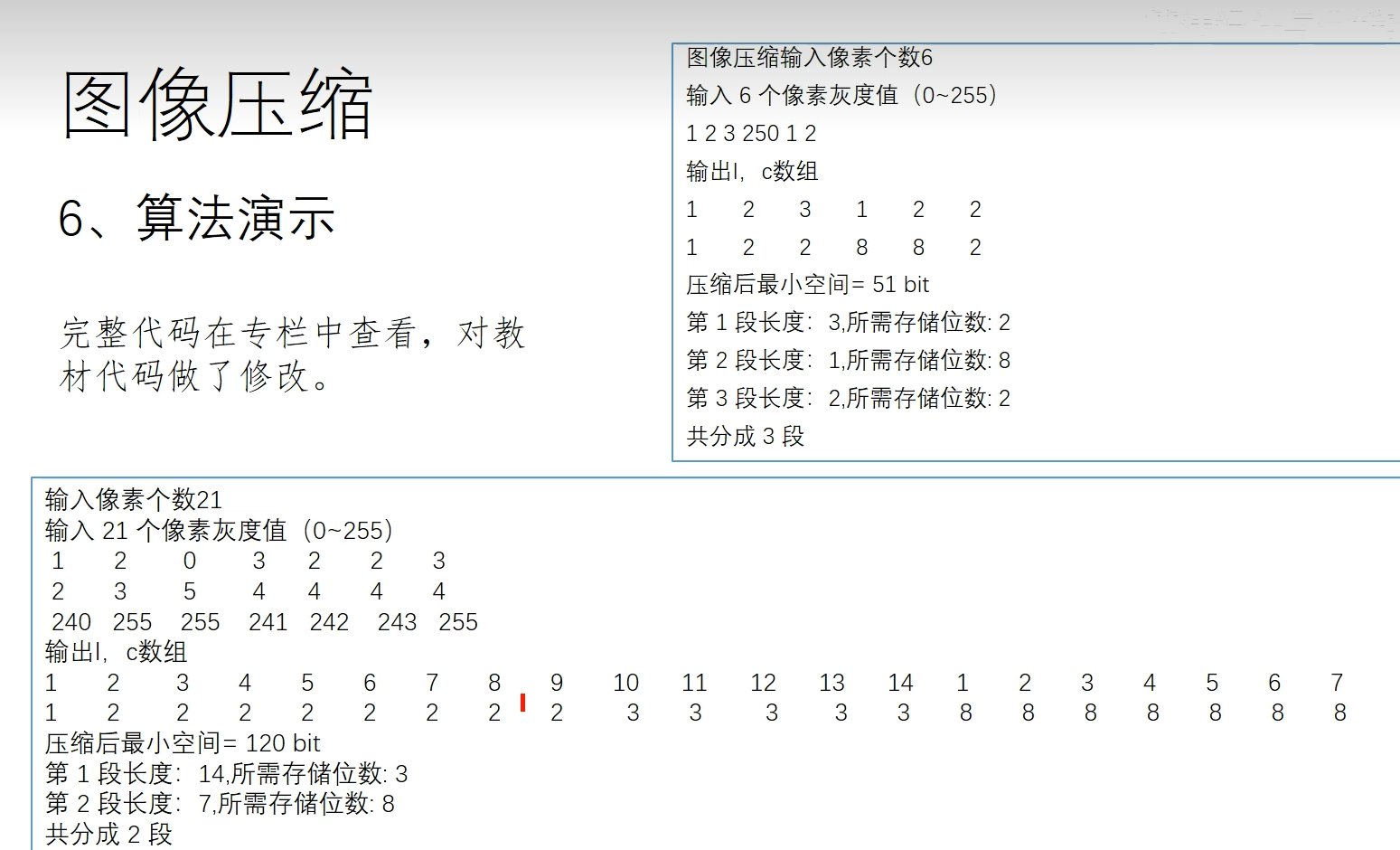
图像压缩-动态规划
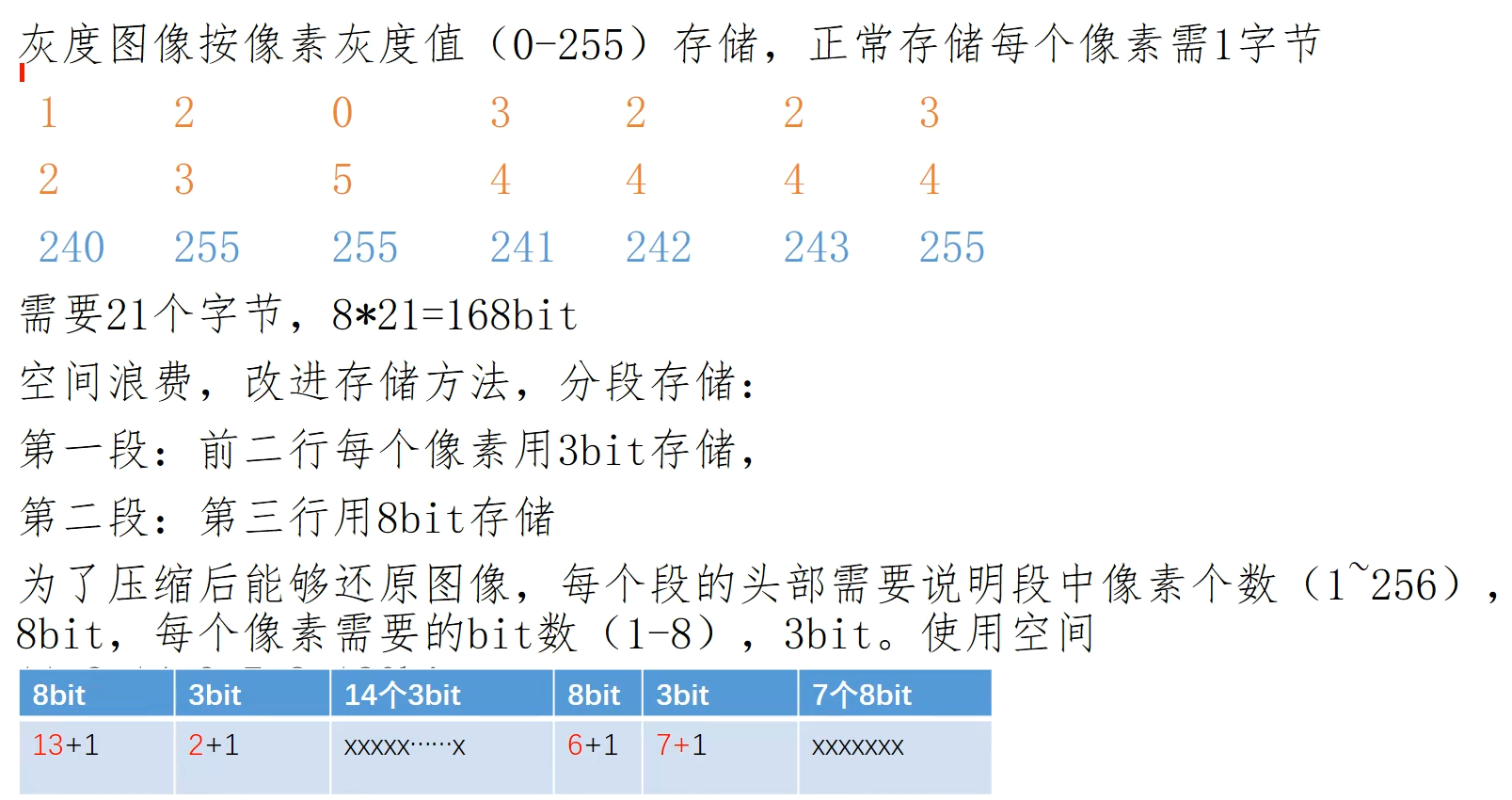
表格包含两条数据,前两行 14 个像素使用 3 bit 来保存信息(前两行数据小于 8 可以用三位二进制表示);第三行 7 个像素使用 8 bit 来保存信息(第三行数据使用 8 位二进制存储) 为了不浪费空间,由于像素个数和存储的数据的长度是从 1 开始的,这里改成从 0 开始计算,所以实际前两行数据的头部数据是 13 和 2,代表 13+1 个像素和每个像素使用 2+1 个比特保存,同理 6+1,7+1, 代表 7 个像素使用 8 bit 方式存储

11 是头部的占位
1. 最优子结构分析
问题的一般化定义:用 表示前 i 个像素 的最优分段
假定其最后一个分段含有 k 个像素,则有如下形式成立
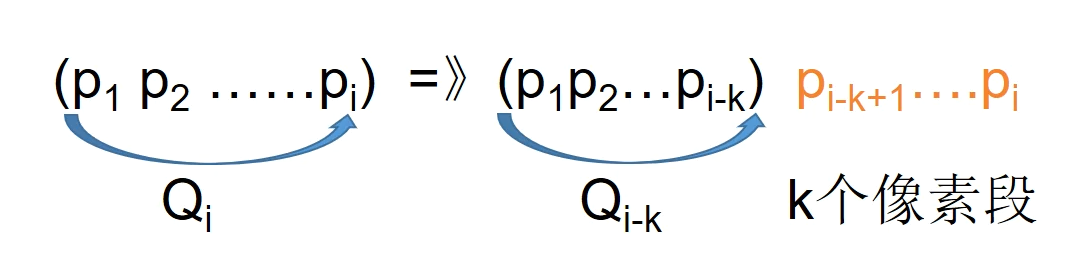 由此可见满足最优子结构性质: 包含
由此可见满足最优子结构性质: 包含
2. 递归定义最优值
设 , 是像素序列 的最优分段所需的存储维数
有最优子结构性质易知:
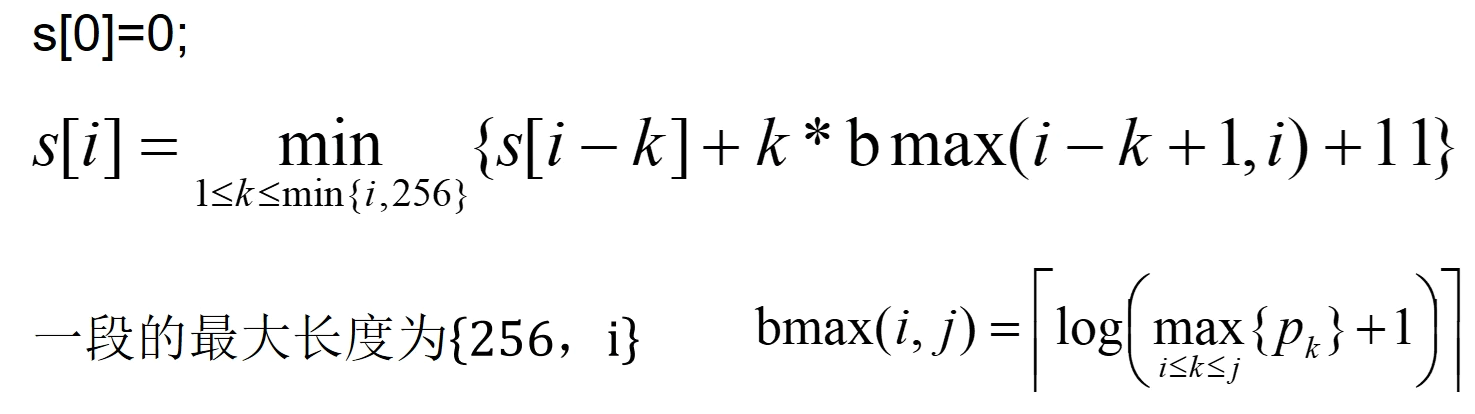
的状态转移来自去除掉 k 元素的状态的 加上这个 k 个元素所需要的最少的存储位数 其中 k 小于当前序列长度 i 和最大存储长度256; 可从 1 开始遍历,一直到最前面,进行尝试把倒数 k 个元素化为一个子段
3. 自底向上计算最优值

代码解释 :前 i 个像素最优分段后存储所需最小 bit 数 :第 i 个像素所需最少的 bit 数 前 i 个像素取得最优分段时,pi 像素所在的最后一个分段中所含的像素数 :前 i 个像素取得最优分段时,pi 像素所在的最后一个分段中像素压缩使用的 bit 数
I 控制的循环是像素序列数量遍历 J 控制的循环是从最后一个元素开始逐个把后 j 个元素作为最后一段的子段,比较这样分子段是否占用更少的位;其中其第一个 if 是判断新加进来的像素数据是否会让最后一个子段的数据位数增加
时间复杂性 两层 for 循环初步判断: 辅助空间是几个保存数据的数组, 长度都是n:空间复杂度
4. 构造最优解
使用求最优值是产生的 , 数组,构造最优解,递归算法

数组中保存了前 i-1 段子序列分好段的情况下,最后一段子序列中的的下标为i 的子元素所在的子段的元素个数 中保存了第 i 个元素最终保存成数据所占的位数 这两个数组中只有每一段最后一个元素的数据是真实的,所以使用
n-l[n]来找到前一段的最后一个元素
示例

5. 时间复杂度

6. 算法演示-专栏里面找
0-1 背包-动态规划

代表是否取这个物品, 代表选择这个物品
1. 最优子结构性质分析
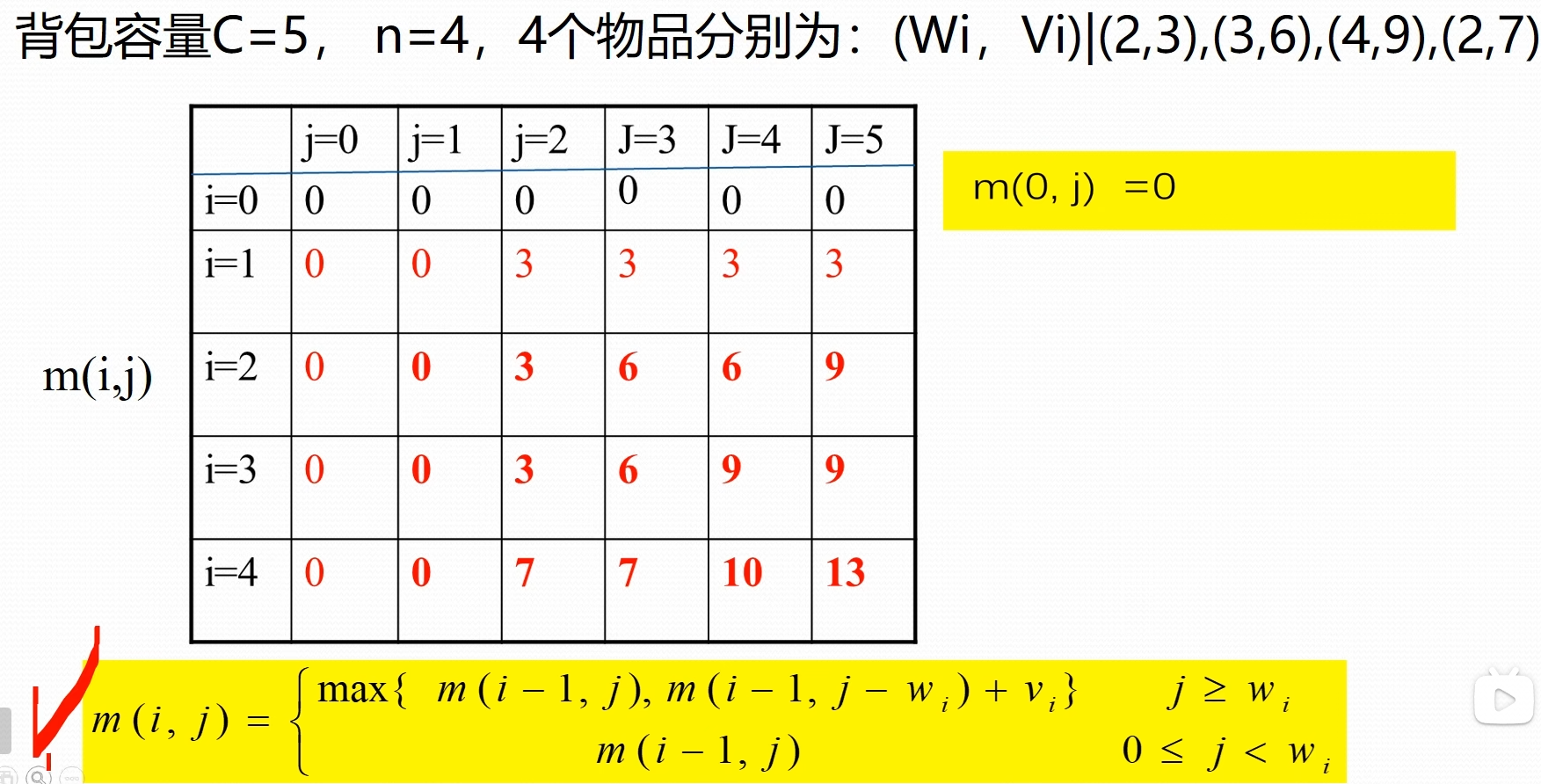
考虑前 i 个物品装入容量为 j 个背包所能获得的最大价值用 表示
- 当第 i 个物品重量 超过背包容量 j 时,第 i 个物品不能装入,实际上:
- 当第 i 个物品重量 不超过背包容量是,第 i 个物品可装可不装。因此
可见:该问题具有最优自己子机构性质,即大问题最优子结构包含了子问题的最优解
2. 最优值递归定义
- 当把第一个物品装入背包为 j。即边界条件
- 当把前 i 个物品装入背包为 j。即一般强况,i>1
3. 求最优值
举例
4. 构造最优解
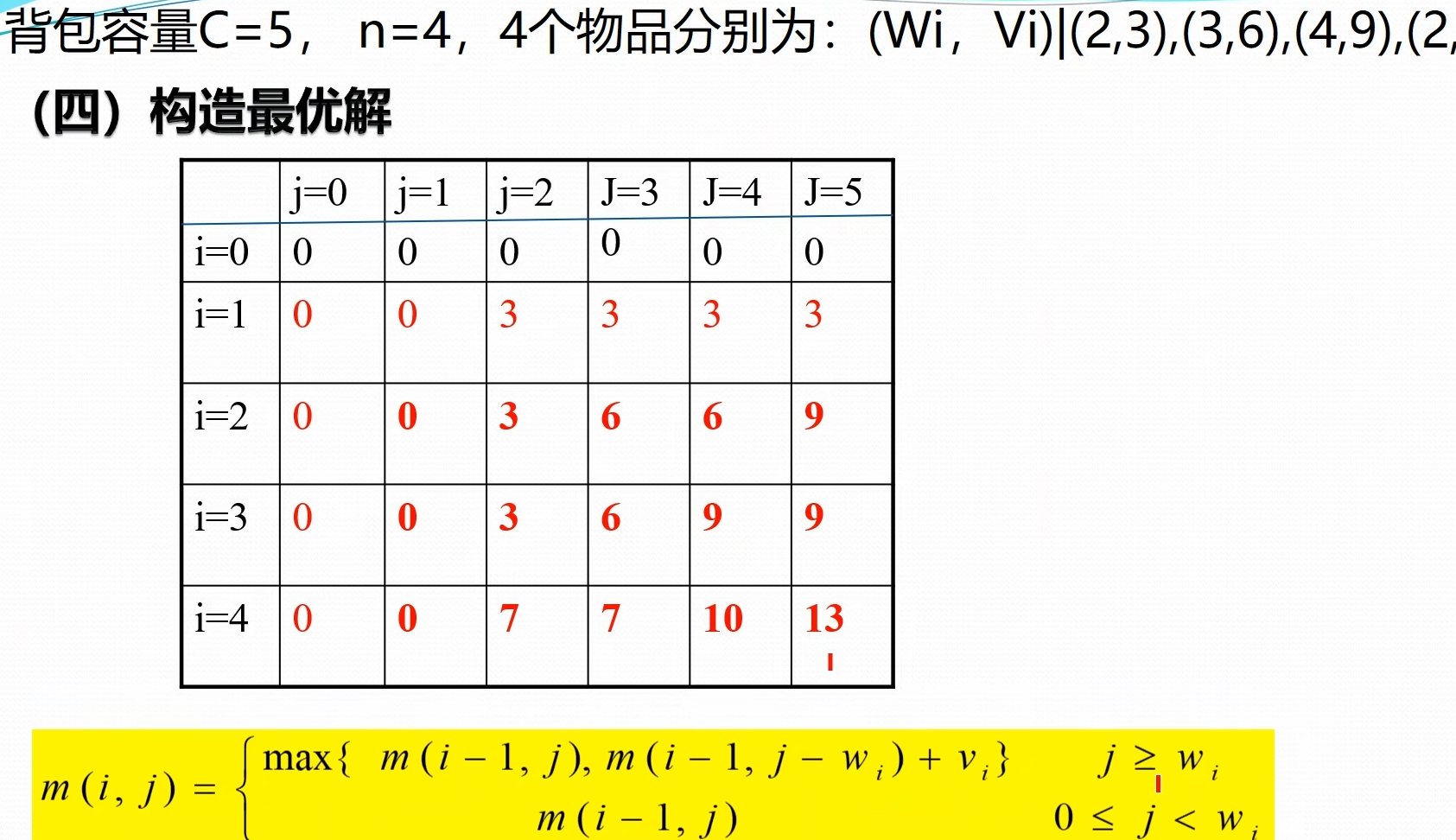
表格构造出来之后,构造最优解,最终的结果保存在右下角数值,根据递归式子,可以知道 来自于 或者 ,从最右下角数据开始判断他是从那里过来,向上检索。如果是 代表没有选择当前第 i 个物品;否则选择了当前物品
5. 算法设计


前面两层 for 循环计算出 m 表;剩下的代码找选择的物品\
6. 算法分析
由 递推式即表格可以看出,时间复发度 ,背包容量 c,物品数量 n 例如当 时,算法需要 计算时间
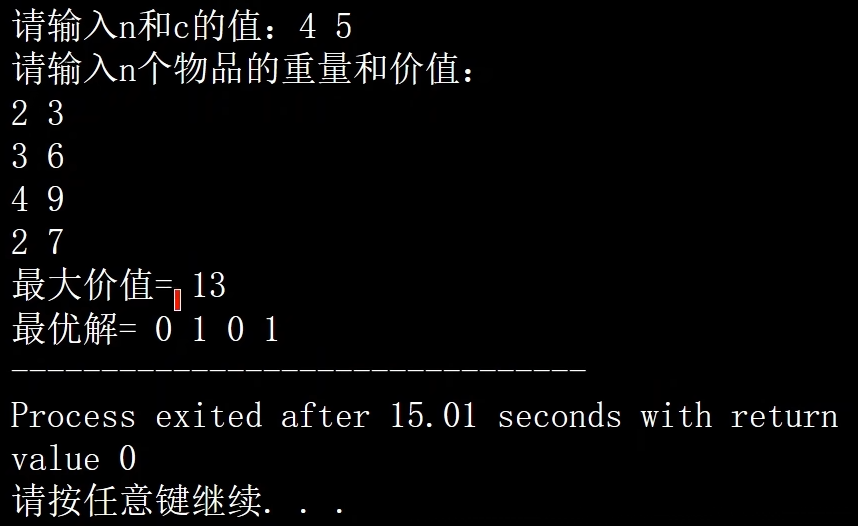
7. 算法演示
代码在 b 站专栏
0-1 背包问题改进算法 (跳跃点集记录最优值)-动态规划
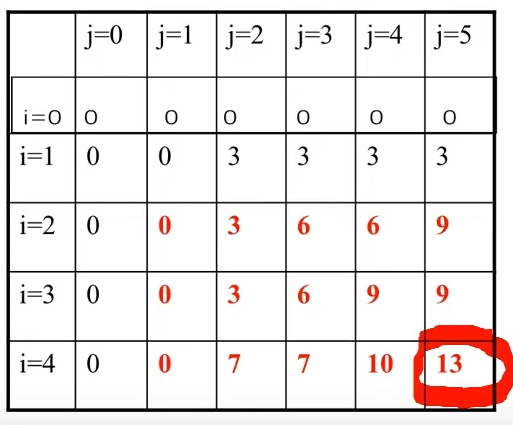
按行来看,每一行都有连续的重复的数值,浪费存储空间和计算量 使用跳跃点集记录表格,使用(0,0)代表第 0 个位置数值跳跃到 0,其后直到下一个跳跃点都是 0; 例如 i=2 是跳跃点有 0,3,6,9 四个跳跃点
算法改进
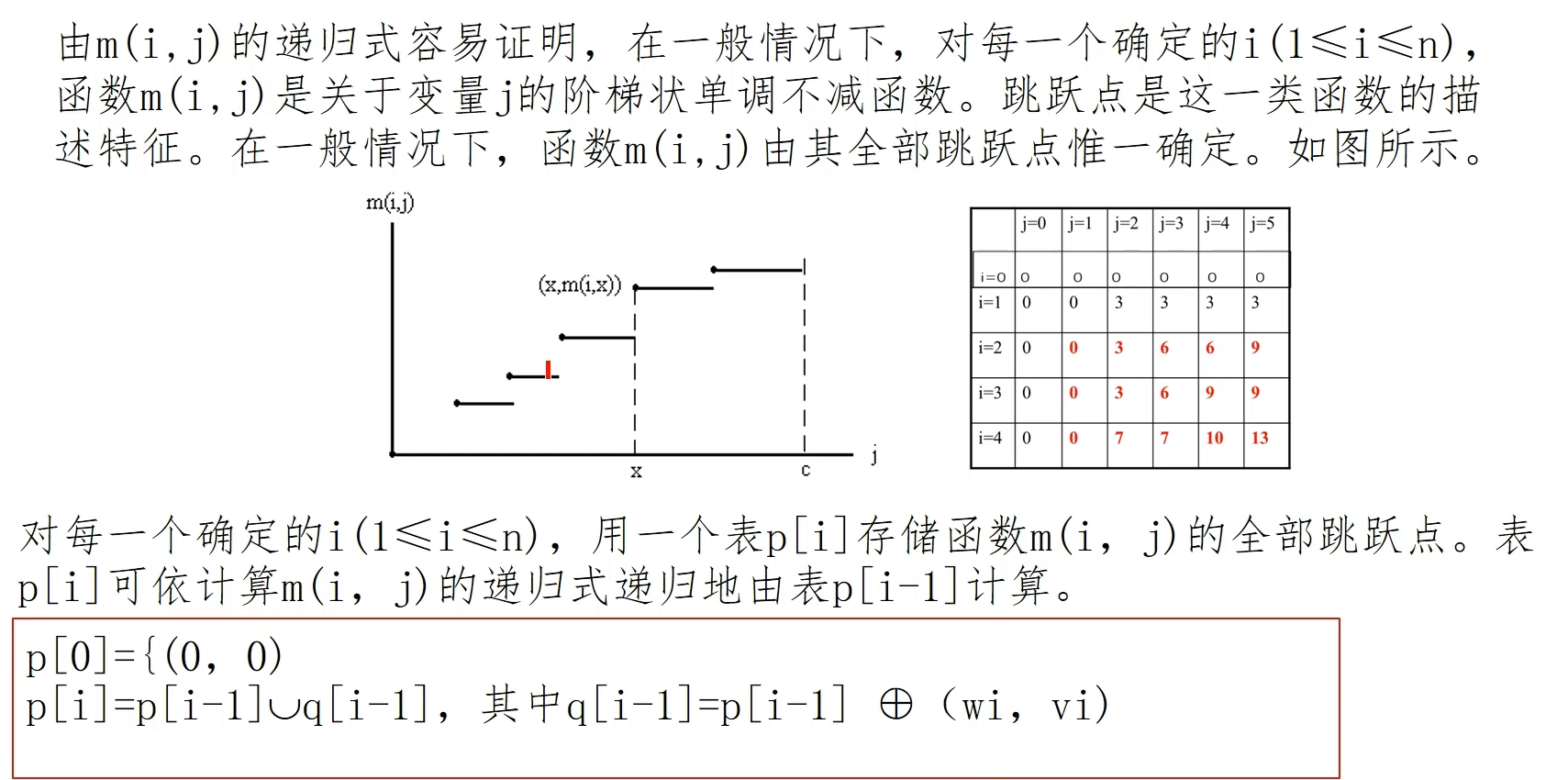
这里证明了 m 表的结果可以使用分段函数来表示
递归定义的解释

这里解释一下 p 和 q 数组的含义
在 0-1 背包动态规划中,常用到 m 表中的第 i -1 行来计算第 i 行的数据 第 i 行的数据有两种计算方式,当 j<第 i 个物品的空间时,,数据直接抄写上一行就可以,对应 中的数据抄写
更新 数组中的数据,主要集中在 第 i 个物品所占空间时,此时 ,对应的就是 q 数组,所以 q 数组中的数据把 中的跳跃点变成 ,再和 合并就可以得到
合并之后的点 中,需要去掉受控点,即不能保证分段函数递增的点,这些点可能是 带来的,当加入当前物品之后,同 j 下价值更低,所以需要去掉
举例
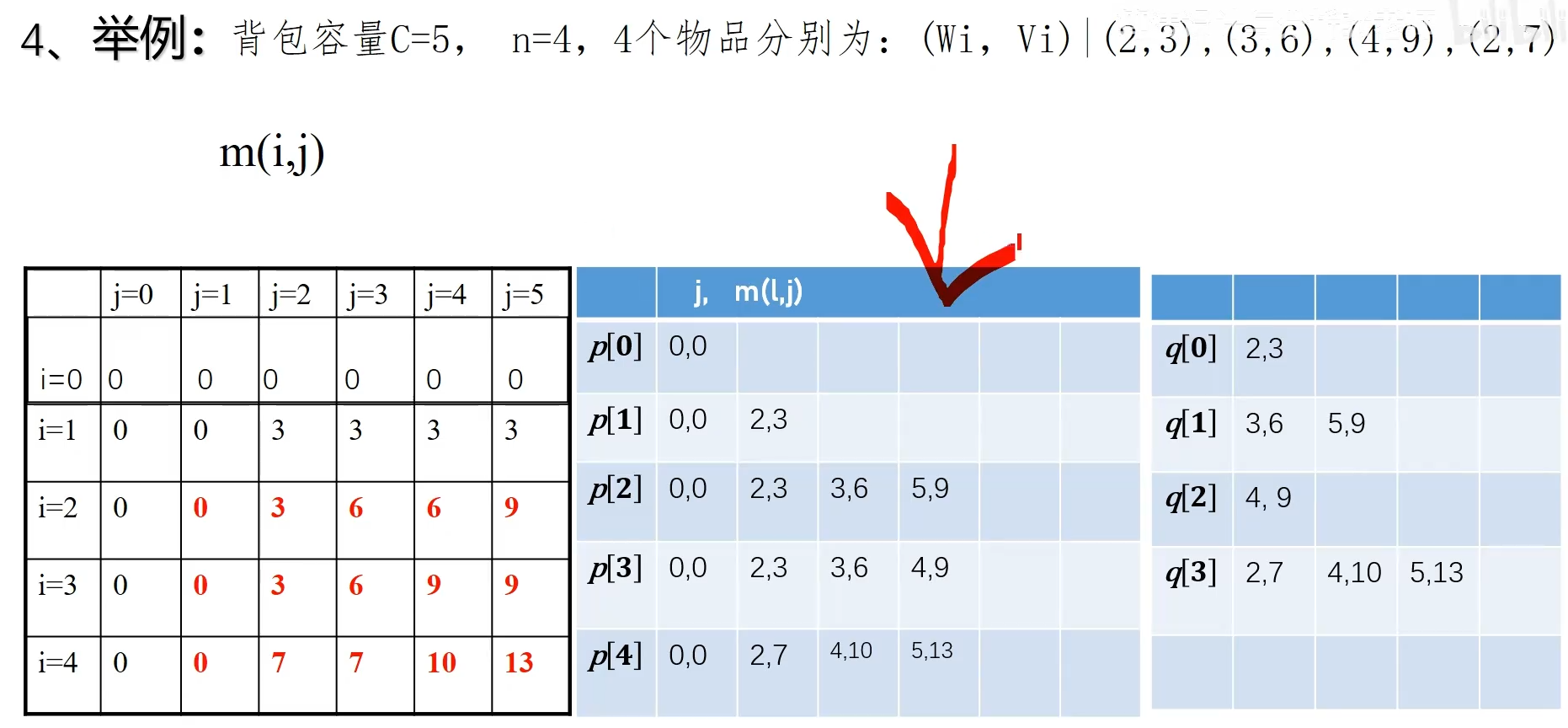
以计算 为例:首先计算 , 是 (第一个物品的价值,空间),把结果中空间背包上限的值去掉(这一行没有),再把 合并,去掉受控点,得到 ,依次计算后续行

为了方便,实际上 p 表保存在一个数组中,使用 head 数组保存每一个 的起始位置,且额外设置一个 head,如上如 在最后一个跳跃点的后面,表示结尾位置
算法设计

i 控制的循环是控制物品数量
j 控制的循环,对当前物品 进行更新,其中 left 和 right 是 行的数据在 p 中的左右范围索引 j 控制的循环中,首先对每一个 i-1 行的数据加上当前物品的的价值和空间,空间超过背包上限的,直接结束
随后把第 i-1 行数据中空间小于当前得到的物品空间 的数据全部加到第 i 行数据中;其中 k 表示在第 i-1 行数据中的遍历索引,已经加入第i 行数据的 i-1 行数据会在下一循环中被跳过 ;next 是第 i 行数据中的遍历索引,用来存新的数据的索引 这样到达 if 的时候,如果当前第 i-1 行的数据的空间和当前得到的物品空间相同,通过判断他们的价值,把更高的价值作为新的跳跃点的数据
下一个 if ,只要现在当前物品价值比第 i 行中前一个物品价值高,就把这个数据放入到第 i 行中;这里包含两种情况,第一,当前得到的物品空间和 i -1 行中某个数据的物品空间相同,需要比较那个物品价值更大,然后保存;第二,当物品空间不一致时,实际上当前物品空间是大于 i-1 行中第 k 个数据的物品空间的,只需要价值比 i 行前一个位置的数据更大就可以
接下来 while 循环,跳过 i-1 行中的受控点,通过移动 k 实现。比较 i 行数据中最后一个数据的价值,把 i-1 行数据中小于该价值的数据都跳过
最后 while 循环,如果每个 i-1 数据加完当前物品的空间和价值,处理完之后,但是 k 还没有到达 right,这些剩下的 i-1 行元素直接顺着放到 i 行数据中就可以;这些数据的价值和空间都是比前面的数据大的
构造最优解

从最后一个数据(最优值 )开始,遍历 ,即当前数据的前一行的数据,用这些数据加上当前物品的空间价值,和最优值对比,找到是否选择跳跃点; 如果没有选择当前物品,则会直接跳过遍历的这一行,从更前面的行遍历搜索
算法复杂度分析

以上是以背包空间比较大的时候时间复杂度 ,背包空间比较小的时候
运行结果

最优二叉搜索树

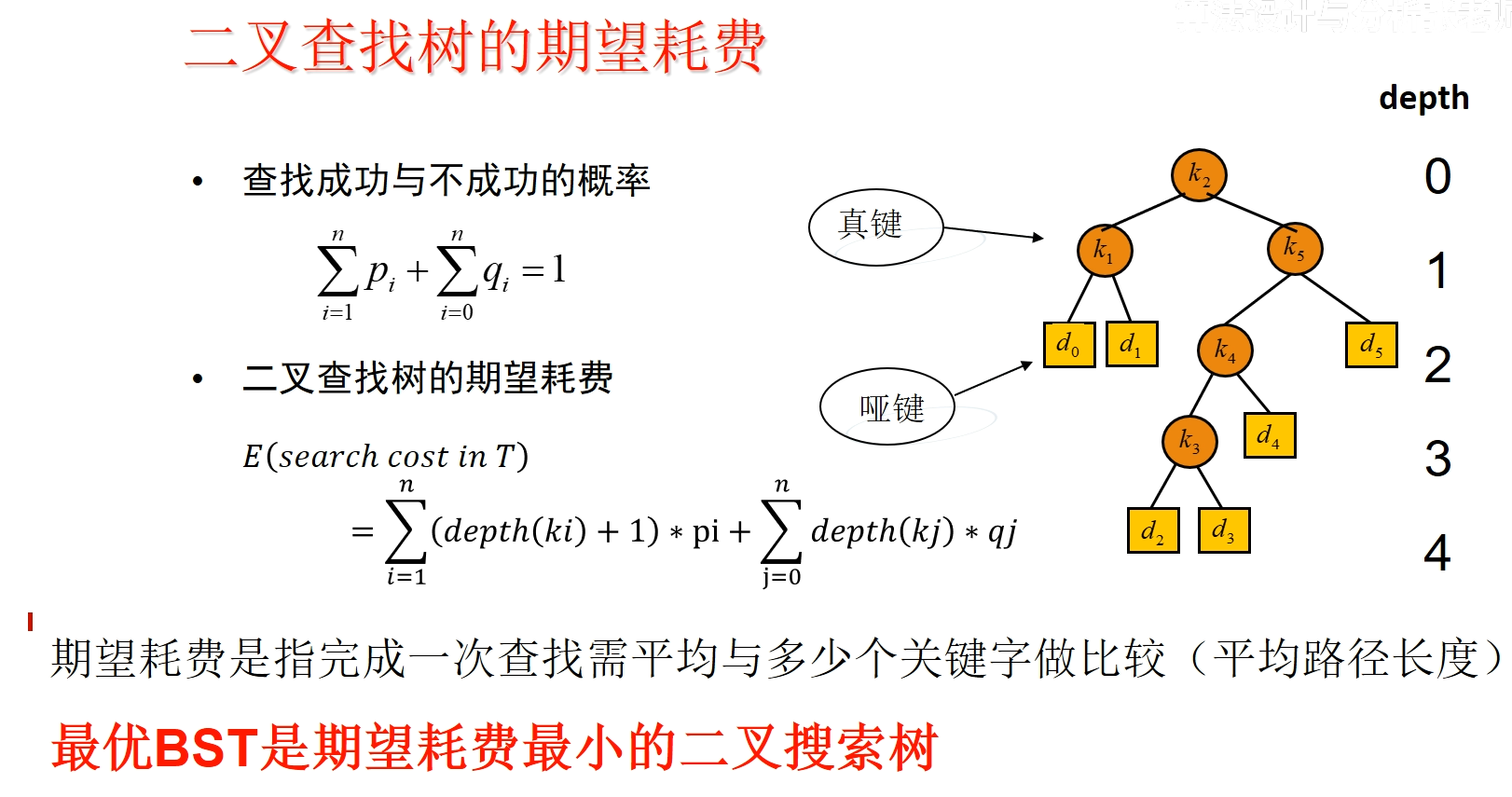
期望耗费最小的二叉搜索树,期望使用真键和假键的深度乘上其查找概率得到平均查找次数 其中真键比较次数是深度加 1,哑键是深度(这里深度从 0 开始,哑键本身的数值不需要比较)
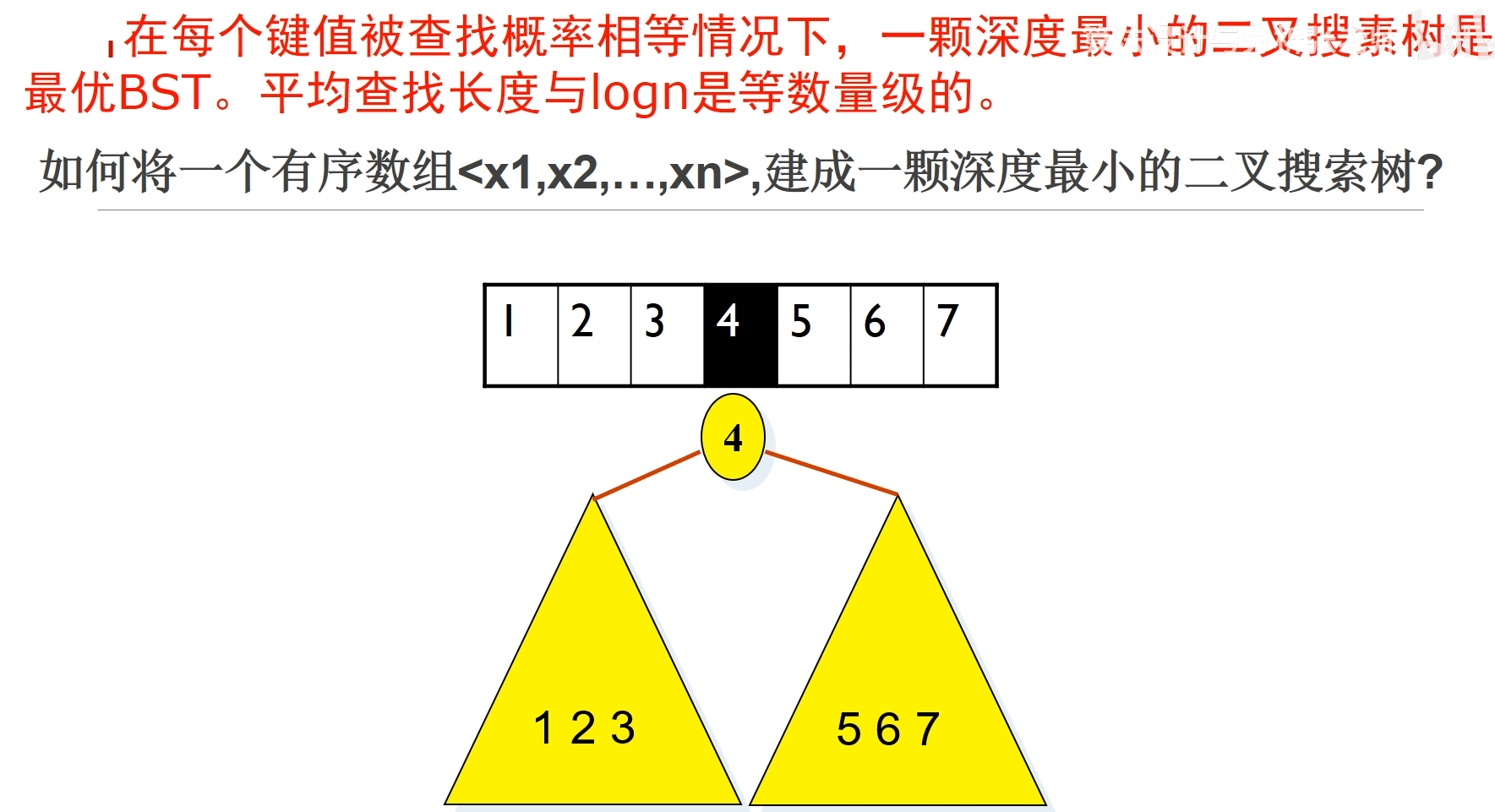
等概率情况下,只需要考虑让树的深度最小就可以保证是最优BST 构建深度最小的二叉树,对排好序的序列,每次选取中间的数据作为母节点,两边的数据作为子树的数据
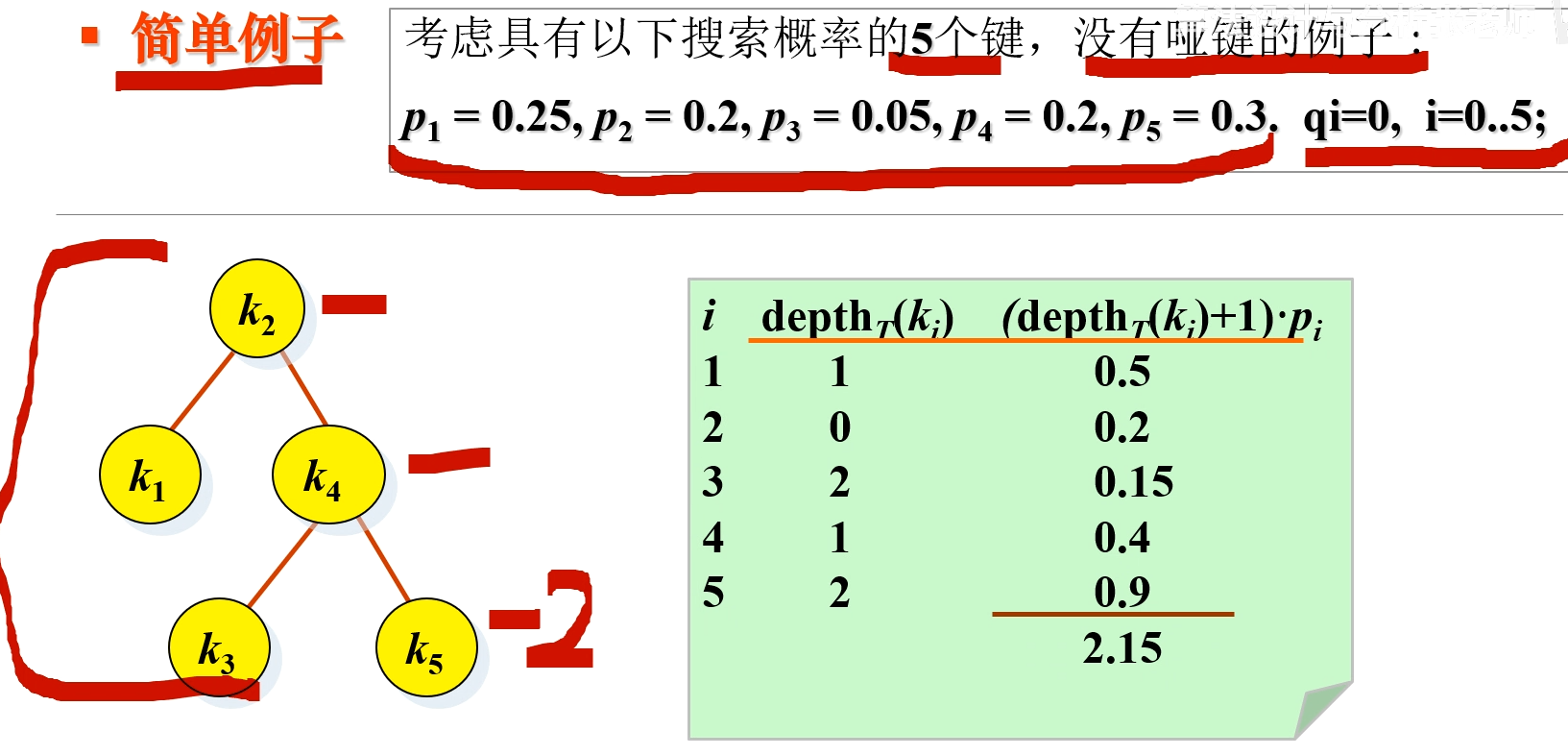
非等概率情况下,深度最小的二叉树并不是最优二叉树
最优 BST 的形状不是深度最小的二叉树;最优二叉树的最高概率的节点不一定位于根节点
若使用穷举法穷举所有二叉树时间复杂度

以上例子,先根据真键 得到亚键 ,亚键是取了真键的其他区间中的取值;真键和哑键的概率和是 1
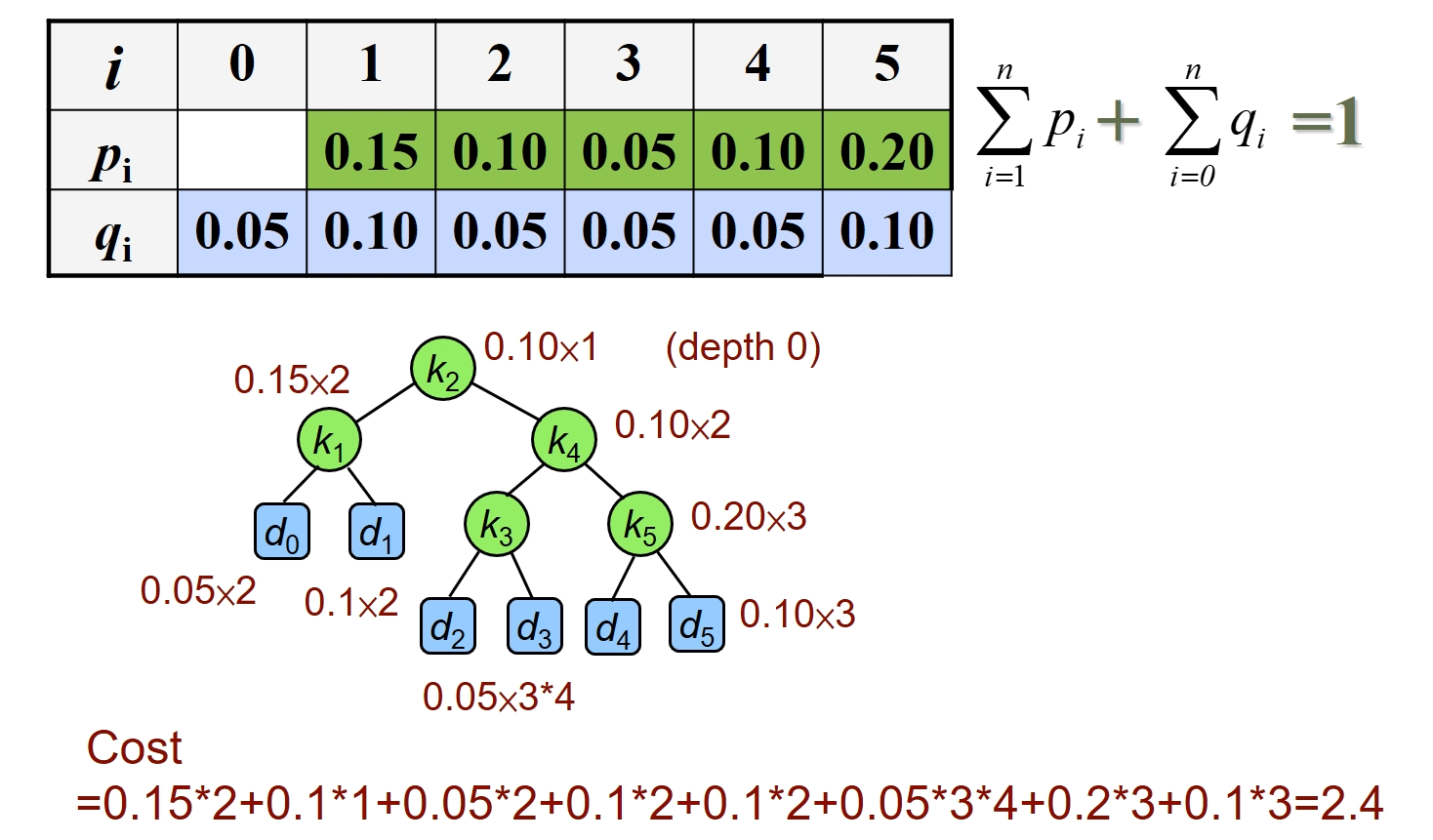
使用真键和亚键的深度加权概率得到期望耗费
分析最优子结构及证明
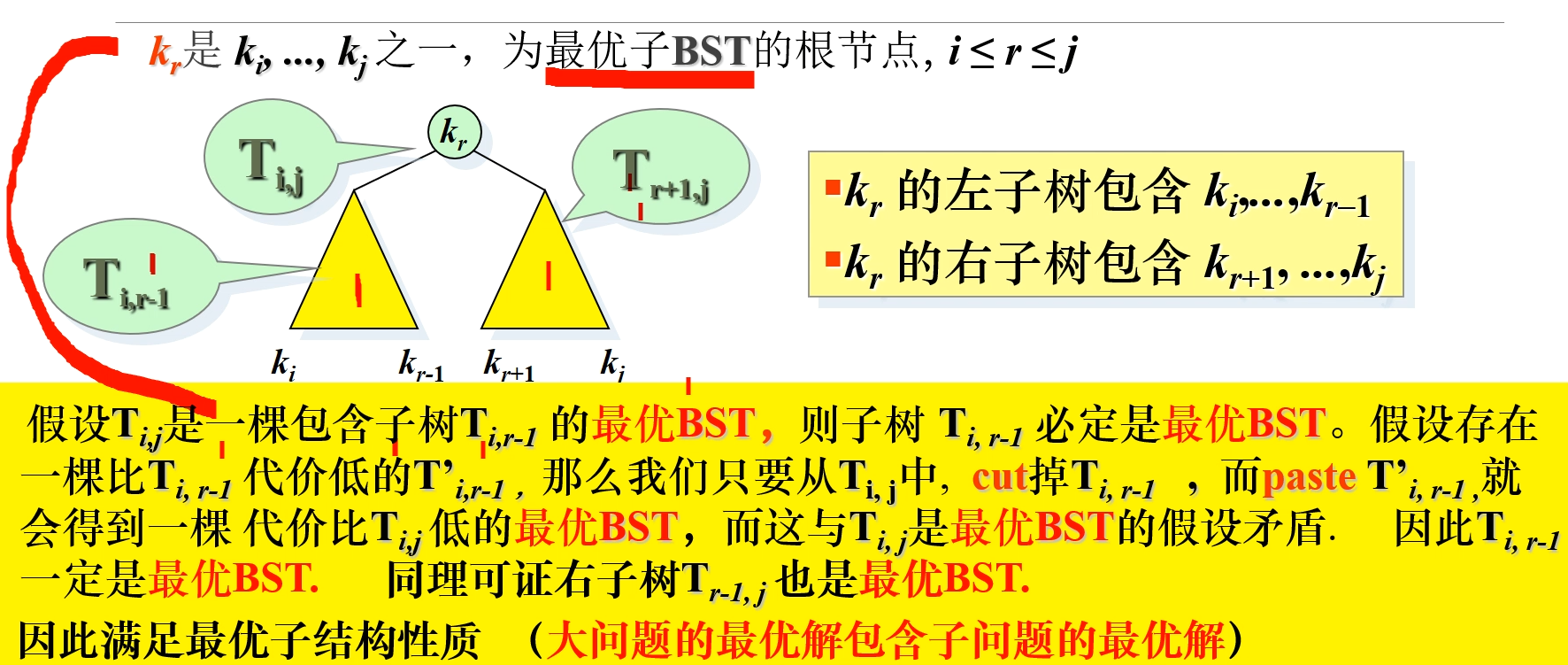
如果这棵树是最优 BST,那么他的子树也是最优 BST,这样具有最优子结构
这个证明简单来说,如果有一个最优 BST,假设左子树不是最优 BST,那么把这个左子树替换成最优 BST,这样整个数的耗费期望是会下降的,和一开始假设这个树是最优 BST 冲突,得证最优 BST 的子树也是最优 BST,因此有最优子结构
最优值递归递归定义

这里最重要的是对递归是进行了转换,将 重新记成 代表从 i 到 j 这一部分元素的损耗期望; 这样可以把原问题的计算过程转换成动态规划中计算表格的过程,简化了计算过程
子树的最优值计算如上,因为子树的键的概率之和加起来不是 1,这里使用 来放大,让当前树的概率和加起来是 1,这里的 是放大之后的最优值 将 乘到左边变成真实的最优值;得到上上图中式子
这个式子,把 min 中的 和前面的 和到一起变成 ; 需要在求 之前先求出来
递归式分为两部分, 这一部分代表 i,j 之间包含真键的情况; 表示只包含亚键的情况(应为 代表只包含一个真键(还有真键左右的两个亚键), 代表只包含哑键)
真键需要判断是否相等,亚键不用判断,直接结束,所以 路长的 0
计算 w[i, j]
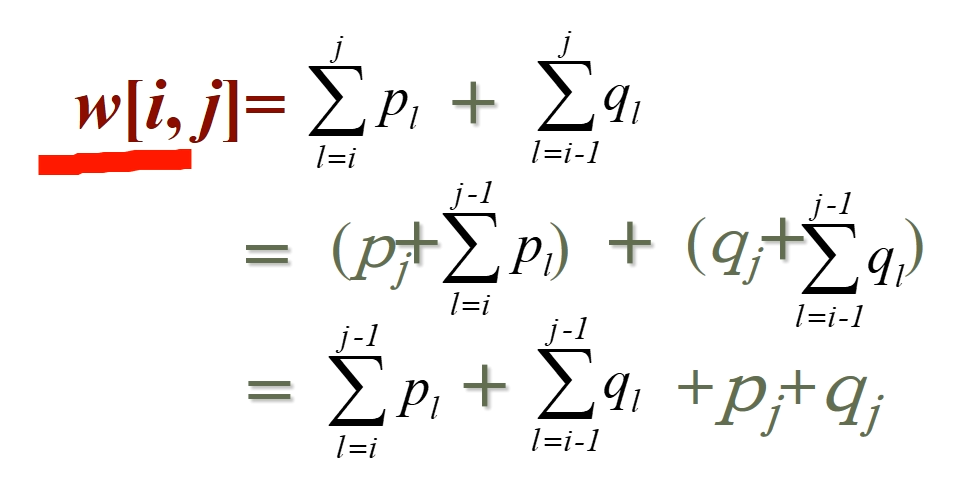 是 i 到 j 的所有真键哑键的概率和,由上式可知 可以从 中计算得到,这样减少了计算量
是 i 到 j 的所有真键哑键的概率和,由上式可知 可以从 中计算得到,这样减少了计算量
和 的递归定义

是只有一个哑键的情况, 是哑键的概率; 是因为,只有一个哑键的时候,平均路长是 0
算法设计

算法生成两张表:e (最优值) 表,root(根)表 e 数组保存最优路长的值; 保存 i,j 之间的最优的分割点(树的根节点)
第一个 for 循环,先把只有一个哑键的情况填上数值;一个真键的规模是包括一个真键和两个哑键的,因此一个哑键的情况需要提前填好
第二个 for 循环,控制问题规模,从只有一个节点到 n 个节点
i 控制的循环遍历所有长度为 len 的子问题,i, j 分别是这个子问题的左右边界,计算出当前问题的 w ,计算 w 的数据都是规模小于当前规模的数据
r 控制的循环,遍历当前子问题中的每一个节点,把该节点当成分割点,找最小的长度,保存最小的长度和分割点
时间复杂度 子问题总数 , 解决一个问题需要
构造最优解
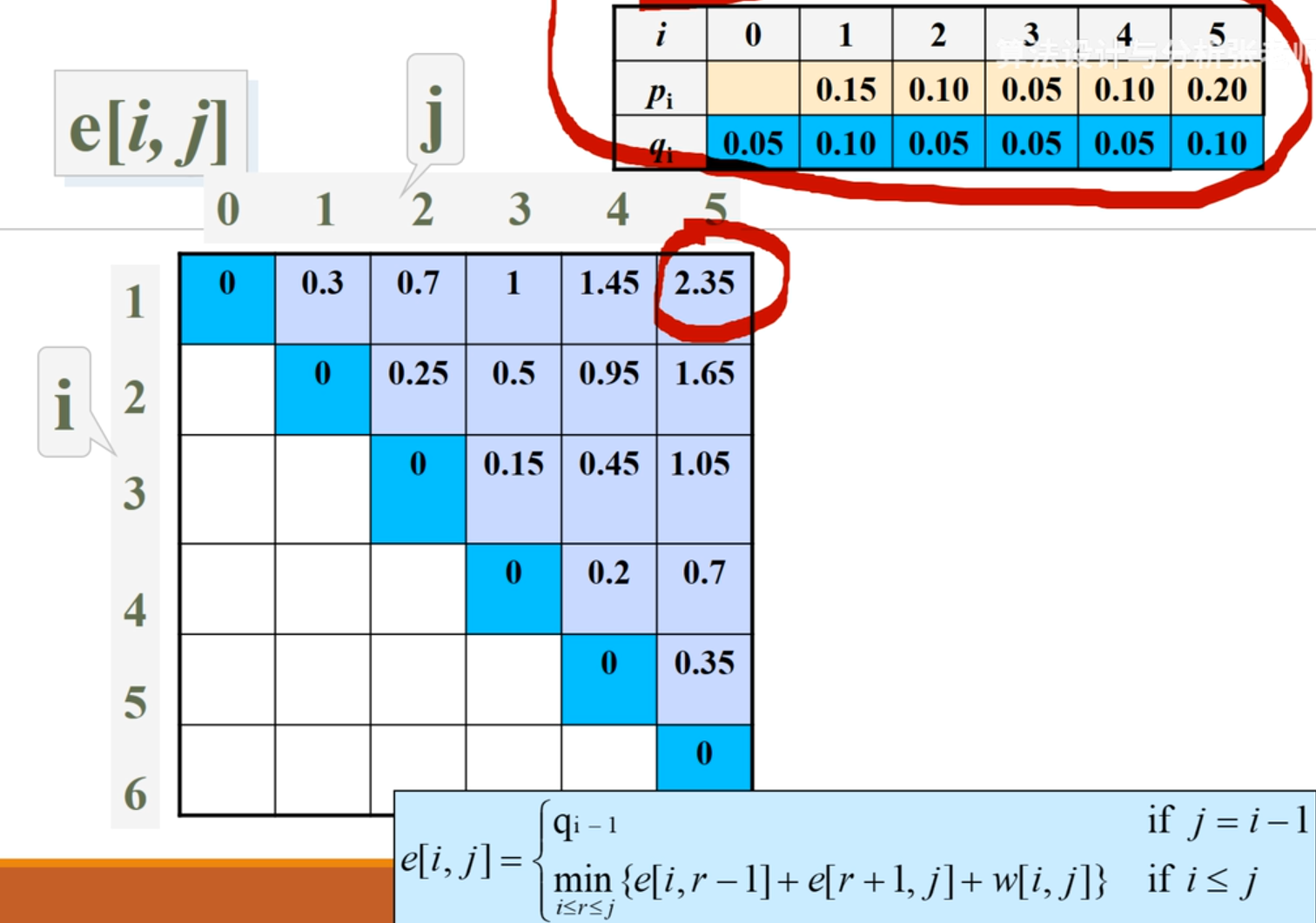
e 最优表,首先填上上图蓝色的数据,代表只有一个哑键的情况( 的情况) 另一种情况中 都是比 规模更小的问题,之前已经计算出来了;按照上图就是沿着蓝色这一斜线计算数值,逐渐向右上角画斜线填上数值,最终结果在右上角
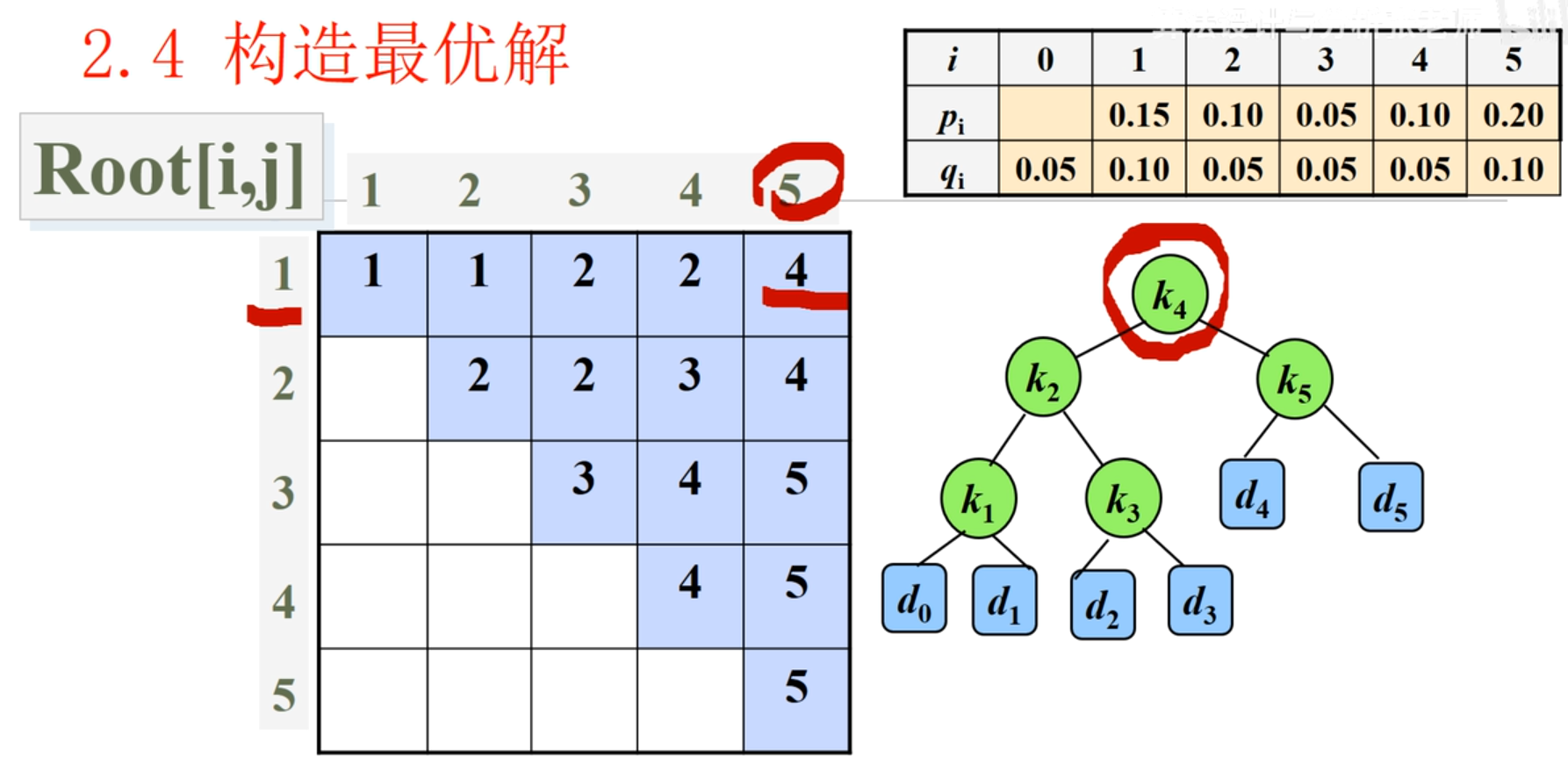
这个问题规模是 5,先找最大规模问题的分割点 ,可找到 4,说明 1-3 是左子树的元素,他的分割点应从 中找;5 是右子树元素,他的分割点从 中找。依次构建出这个棵树
总结
本体目的设计思想雷同矩阵连乘,难度高于矩阵连乘,细节较多
- 分析最优子结构,证明满足最优子结构性质
- 递归定义最优值:
- 自底向上求最优值:按规模从大到校填写最优值 e 表,根 root 表
- 构造最优解:使用分治法
思考:能否进一步提高算法性能? 算法中 ,可否缩小 r 的取值范围?
四柱汉诺塔
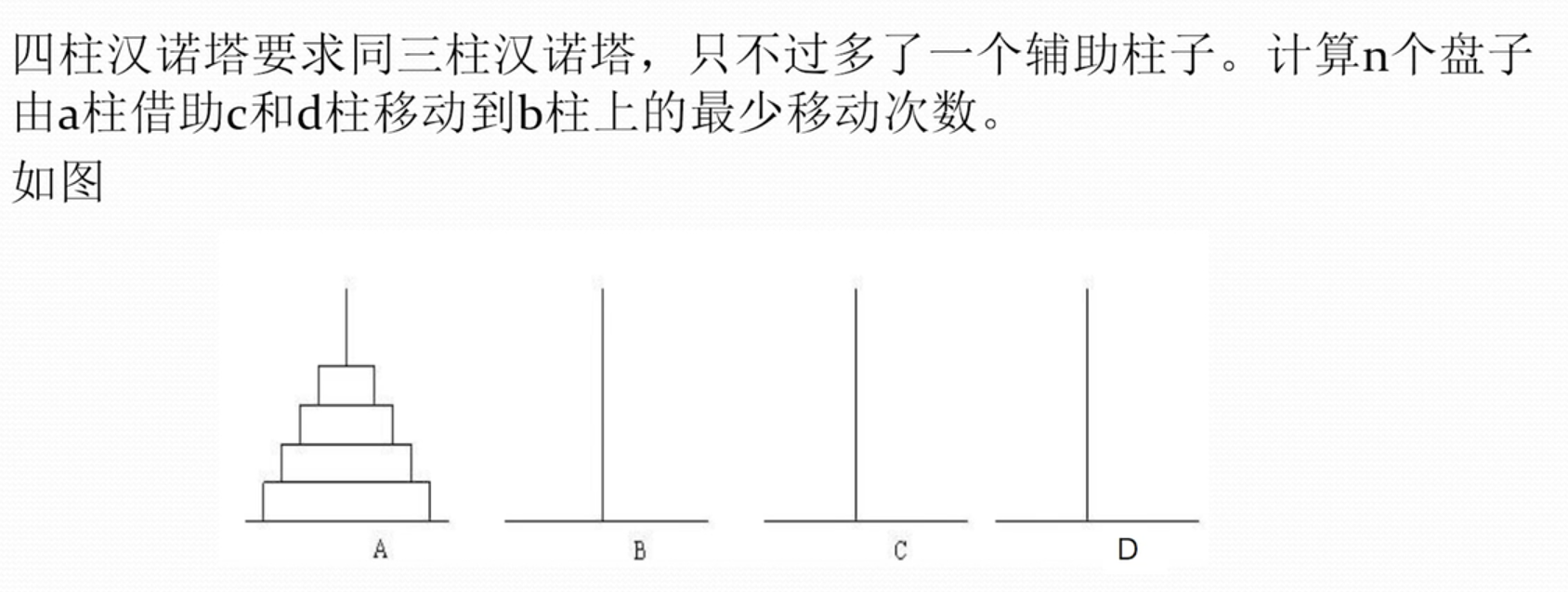
分析最优子结构

问题备份被分解成,两个 n-k 的四柱汉诺塔问题和一个 k 个盘子的三柱汉诺塔问题,其中三柱汉诺塔问题需要移动的步数是 (n 是盘子数), 两个四柱汉诺塔需要递归表示 其中k 需要遍历找到最优情况
最少移动次数的递归定义
子结构中,我们把 a 柱上的盘子分成两部分 k 和 n-k 来移动,需要保证,盘子最少有两个。盘子为 0 和 1 的情况是边界情况
设 n 个盘子的四柱汉诺塔最少移动次数 ,递归定义
求最优值

游艇问题


小结
- 动态规划可解决的问题同分治策略解决的问题类似,区别是存在重复子问题
- 按照动态规划解题的基本步骤解决问题
- 找出最优解的性质,并刻画其结构特征(最优子结构性质)
- 递归的定义最优值
- 以自底向上的方式计算出最优值
- 根据计算最优值时得到的信息,构造最优解
- 同一个问题可能有多种方式刻画他的最优子结构,有些表示方法求解速度更快(空间占用小,问题维度小)