简介
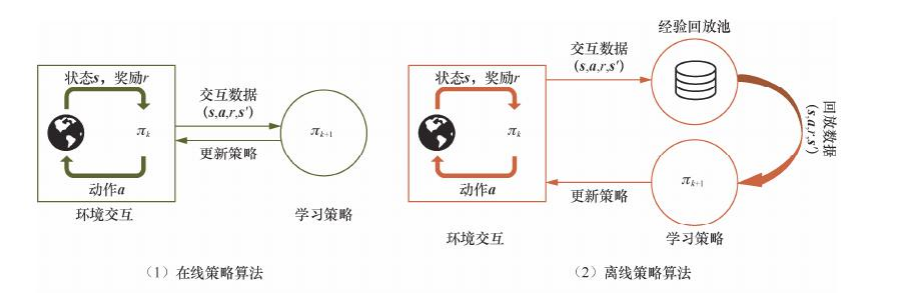
离线强化学习和离线策略强化学习的区别 离线策略强化学习,是值当前策略和收集数据的策略不一致,训练数据来自于过去和环境交互的 buffer 中,数据分布和当前策略不一致,需要解决分布偏移问题
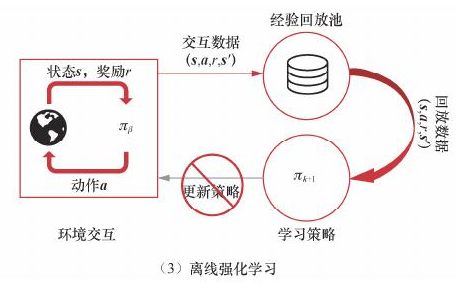
离线强化学习,是指数据完全来自于离线数据,没有和真实环境进行交互的数据,但是可以使用集成环境模型。需要解决分布偏移和策略外推
策略外推是指,训练策略时,策略生成的状态动作对,可能在离线数据集中没有,环境模型和策略模型没有这方面的数据,导致出现过高估计或者估计不准确 通常解决方法
批量限制 Q-learning 算法
研究者首先尝试将离线策略算法直接搬到离线环境下,设计了三个实验:
- 先用 DDPG 训练一个智能体,将所有和环境交互的数据记录下来,再有这个数据训练离线的 DDPG 智能体
- 在线训练的 DDPG 智能体,训练师每次从经验回放池中采样,并且将相同的数据同步训练离线的 DDPG 智能体,这两个智能体训练的数据顺序完全一样
- 在线 DDPG 算法训练完成之后作为专家,在环境中采集大量数据,供 DDPG 智能体学习
三个实验结果
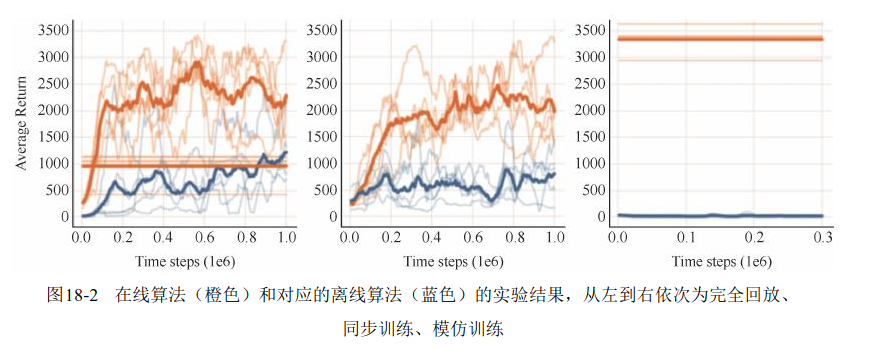
三个实验均失败了,外推误差是导致离线策略算法不能迁移到离线环境的原因
外推误差,是指当前策略访问到的状态动作对与从数据集中采样得到的状态动作对的分布不匹配而产生的误差
策略得到的动作,和原始数据中的动作分布(动作状态对)不一样,智能体看到的这些数据少,对这些动作状态对的评估会产生偏差,导致学习效果不好
为了减少误差,单前概念策略需要做到值访问和数据集相似的 数据,即输出的数据和离线按数据集中的尽量接近。 满足这一要求的策略称为批量限制策略,具体来说需要满足三个目标
- 最小化选择的动作与数据集中的数据的距离
- 采取动作后能到哦大与离线数据集中的状态相似的状态
- 最大化函数Q
此时只需要把策略 能选择的动作限制在数据集 内,就能满足上述 3 个目标的平衡,得到表格设定下的批量限制 Q-learning(batch-contrained Q-learing BCQ)算法:
这样训练练出来的智能体是被限制在离线数据集中的,还需要进一步获取数据训练
如果数据中包含所有可能的 ,按照上市可以收敛到最优的价值函数Q
对于连续的状态和动作,BCQ 采用了很巧妙的方法:训练一个生成模型 对于数据集 和其中的状态 ,生成模型 可以生成与 中数据接近的一系列动作 用于 Q 网络的训练。 更近一步,为了增加生成动作的多样性,减少生成次数,BCQ 还引入了扰动模型 。输入 时,模型会给出一个绝对值最大为 的微扰并附加在动作上。这两个模型综合起来相当于给出了批量限制策略 :
策略的动作需要从生成模型生成,在加上扰动
其中,生成模型使用变分自动编码器(variational auto-encoder, VAE)实现;扰动模型直接通过确定性策略梯度算法训练,目标使函数 Q 最大化:
总结,BCQ 算法的流程如下:


无代码实现。介绍 BCQ 算法是因为
- 他对离线强化学习的误差分析和实验很有启发
- 他是无模型离线强化学习中限制策略集合算法中的经典方法
下面介绍直接限制函数 Q 的算法的代表:保守 Q-learning
保守 Q-learning 算法 (conservative Q-learning CQL)
离线强化学习面对的巨大挑战是如何减少外推误差。实验表明。外推误差会导致在原理数据集的点上函数 Q 的过高估计,甚至出现 Q 值向上发散的情况 因此如果有办法将偏离数据集的点上的函数 Q 保持很低的值,或许能消除部分外推误差的影响,这就是保守Q-learning (conservative Q-learning CQL) 的基本思想
CQL 在普通的贝尔曼方程上引入了一些额外的限制项,达到了这一目的.
在普通的 Q-learning 中,Q 的更新方程写为
其中, 是贝尔曼算子, 等于
为了防止 Q 值在各个状态上(特别是不再数据集中的状态上)的过高估计,我们需要对某些状态上的高 Q 值进行惩罚。
这里惩罚的就是在数据集之外的数据,具体来说,智能体在不断学习过程中,会对数据集中的一句进行拟合,其中的状态动作对就会有更高的概率出现,而不再数据集之中的数据,智能体学习不到位,可能会产生过高估计的问题。 我们需要减少这些小概率选取的动作的收益,直接过高的动作值估计作为他的损失函数,让智能体学会不去选这些过高估计的小概率动作(小概率状态动作对在数据集中没有|很少,智能体的估计是错误的)
考虑一般情况,希望 在某个特定分布 上的期望最小。再上式中, 计算需要 ,但是只有 是生成的,可能不在数据集中。所以我们要对数据集中的状态 按策略 得到的动作进行惩罚:
这里的 可以理解为一个形式作用,它可以根据 是不是数据集中的数据变化,对数据集中的数据,他会变小,减弱这一项的影响;数据集外的数据,他会变大,增强这一项,此时代表这个动作应该更少的被智能体使用,直接把他的收益作为 loss,收益越大,对智能体惩罚越大,这样智能体可以学习到这些不应该采用的动作
其中, 是平衡因子。上式迭代收敛给出的函数 Q 在任何饿 上的值都比真实值小。 如果放宽条件,只追求 在 上的期望值 比真实值小的话,可以略微放松对上式的约束。一个自然的想法,对于符合生成数据集的行为策略 的数据点,可以认为 对这些点的估值比较准确,在这些点不必限制让 值很小。作为对第一项的补偿,上式改为:
这里相当于减去了一项基准项,这一项是使用数据集中动作的数据使用 Q 函数计算出来动作价值,当智能体选取的动作和离线数据集接近时,这一项的影响会减少;当和离线数据集不一致时,如果出现过高估计,这一项影响会变大,给智能体惩罚
这样,CQL 算法有了理论保证,仍然有一个缺陷:计算开销太大,当 时,Q 每迭代一步,算法都要对策略 做完整的离线策略评估来计算上式中的 值,在进行一次策略迭代,而离线策略评估非常耗时。既然 并非与 独立,而是通过 值最大的动作衍生出来的,我们完全可以使 取最大值的 去近似 ,即:
这里说的计算量大,是指评估的时候,把所有可选动作都评估一下,这样更新一次计算量巨大,实际操作时,通过多种方式生成一定数量待评估动作,然后用参与训练,并没有这么复杂
防止过拟合,再加上正则项 ,综合下来得到的点方程:
正则项采用和先验策略 的 KL 距离,即 。一般取 为均匀分布 即可,这样迭代方程简化为:
这样,简化后式中不含 (离线数据集采集数据的策略), 未计算提供了很大的方便。
文献中给出了基于 DQN 和 SAC 两种框架的 CQL 算法,这里智能体使用 SAC。
算法框架
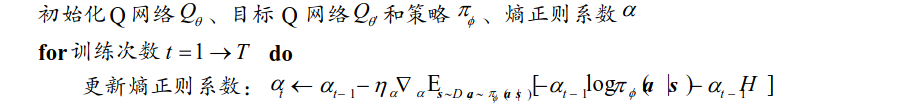
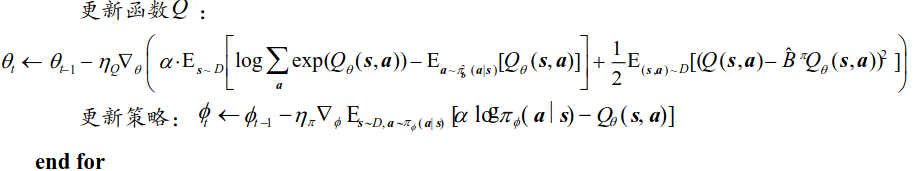
总结
迭代方程中的第一项中的 实际使用了三种方式采样动作来近似
- 均匀分布随机采样
- 当状态下的策略的动作采样
- 下一状态的策略的采样动作
对采样到的动作进行价值评估,评估之后减去log (动作概率),相当于 ,对智能体概率比较大的动作,价值基本不变; 对智能体认为概率比较小的动作,价值变得过高。 其中智能体认为概率大的动作,都是从离线数据库中学习到的;概率低的,认为是离线数据集中缺少的数据,这些动作需要让智能体尽量不选择,把这些过高的估计变成他的损失函数,给智能体惩罚,让他学习到不能选择这些动作,变得保守,只选择离线数据集中出现次数多的对状态动作对
actor_value = actor_value -log_actor