MBPO 类似前面的 Dyna_Q 算法,在策略优化算法的基础上,加上环境模型,学习真实环境数据之后,还使用环境模型生成的数据进行学习,可以减小数据量的需求,提高数据利用效率
MBPO 算法(model-based policy optimization)
2019 年提出的算法,是深度强化学习中最重要的基于模型的强化学习算法之一
MBPO 算法基于以下两个关键的观察:
- 随着环境模型的推演步数边长,模型累积的复合误差会加速增加,使得环境模型得出的结果变得很不可靠
- 必须权衡推演步数增加后模型增加的误差带来的负面作用与步数增加后使得训练的策略更优的正面作用,二者权衡决定了推演的步数
MBPO 在这两个观察的基础上,提出使用模型来从之前访问过的真实状态开始进行较短步数的推演,而不是从初始状态开始进行完整的推演。MBPO 中称为分支推演(branched rollout),即在真实环境中采样的轨迹上推演出新的短分支
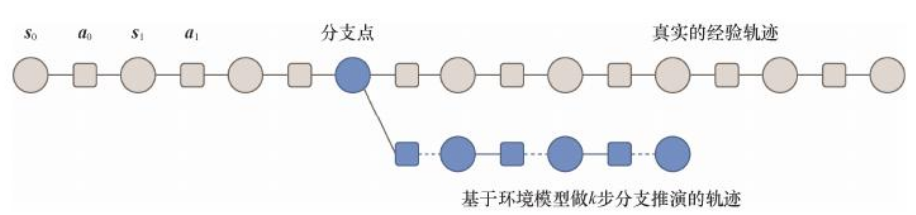
MBPO 和 DynaQ 算法很相似,MBPO 的无模型学习部分使用的是 SAC,环境模型的构建和 PETS 算法中一致,都使用模型集成的方式,其中每一个环境模型的输出都是一个高斯分布
MBPO 的具体算法框架

总结
- MBPO 算法在实际使用中,会设置一个 real_ratio,把真实环境交互数据和集成模型生成的数据,按照一定比例,一起用于智能体的训练
- 集成环境生成的数据,和真实环境交互的数据会被存放到两个 buffer 中,训练智能体时从里面分别取出数据
- 在训练环境模型时,每一次训练都使用所有的真实环境交互数据
- 进行 roll_out 是在训练完一次环境模型之后,roll_out 会从真实环境交互数据中随机采样
- 训练模型和 roll_out,是每个固定步数训练一次,训练的时候智能体也会一步一步向前走,没有一定步数(采样了一部分数据),就会再次训练一次环境模型和 roll_out 一些数据
这里的 roll_out 和蒙特卡罗树搜索对比,这里会产生误差,因为是在集成模型中生成的数据,不是直接和环境交互