无模型 V.S. 基于模型的强化学习
-
基于模型的强化学习
- 一但模型学习号,可以进行 on-policy 学习
- 一但模型学习好,可能不需要真实环境交互数据(批量强化学习)
- 样本效率总是比无模型方法高
- 面临模型误差累计问题
-
无模型强化学习
- 具有最好的渐进性能
- 非常适合使用大数据的深度学习架构
- 离线策略方法存在不稳定性
- 赝本效率第需要大量训练数据
MPC 是纯环境模型的方法,环境模型可以使用神经网络构建,MPC 方法不显示的构建出一个策略
因此需要有一个办法能从环境中的到动作|做出选择,这个就是打靶法
打靶法
MPC 在生成动作是的方法 首先需要生成很多动作序列,动作序列有设置固定长度,用来获取动作收益,生成动作序列的方法叫打靶法 生成的是序列会和环境模型进行交互得到收益和状态转换 MPC 的关键点是如何生成这些序列
随机打靶法
随机生成 条动作序列,即生成的每一条动作序列的每一个动作时,从动作空间中随机采样一个动作。最终形成 条动作序列。 随机打靶法在一些简单的环境中,表现很不错。在随机采样的基础上,可以做的更好一些
交叉熵方法-CEM
是一种进化策略方法,核心是维护一个带参数的分布(标准差和均值,用来表示采样动作分布),根据每一次采样的结果,更新分布中的参数,使能够获得较高累计奖励的动作序列的概率比较高。
相比于随机打靶法,交叉熵法可以利用之前采样得到的比较好的结果,一定程度上减少采样到较差动作的概率,更高效
动作可以优化 次,交互是做法如下:

PETS 算法
带轨迹采样的概率集成(probabilistic ensembles with trajectory sampling PETS), 轨迹采样指的是 CEM 选择动作需要采样采样
PETS 是使用 MPC 的基于模型的强化学习算法。PETS 中,环境模型中采用集成学习的方法,即构建多个环境模型,然后使用多个模型来预测(使用时随机选择一个模型),最后使用 CEM 进行模型预测控制(选取一个最优动作)
这是因为与这能提交互的环境是动态系统,你的环境是一个动态模型。这个系统中有两种不确定性,分别是偶然不确定性和认知不确定性,偶然不确定性是系统中本身的随机性导致的;认知不确定性是由于见过的数据过少导致
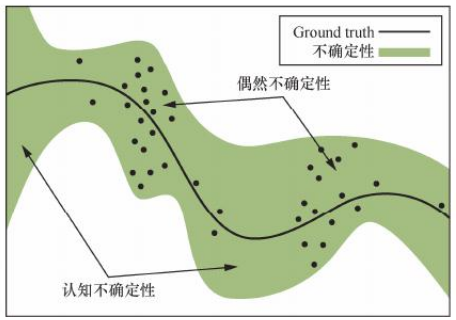
PETS 中,环境模型的构建会考虑到这两种不确定性。 首先,定义环境模型输出是一个高斯分布,用来捕捉偶然不确定性 令环境模型为 ,其参数为 ,基于当前状态动作对 ,下一个状态 的分布可以写成
这里采用神经网络构建 和 ,损失函数是多变量高斯分布的似然比+协方差矩阵(实际是一个对 log 方差的限制,范数):
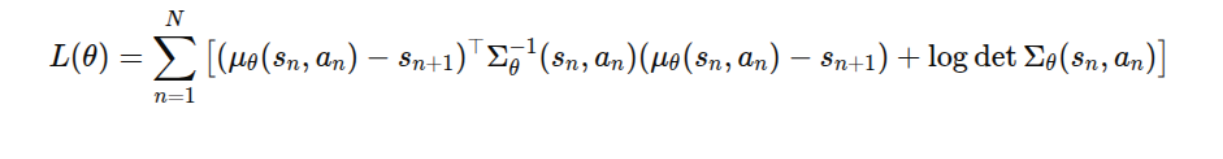
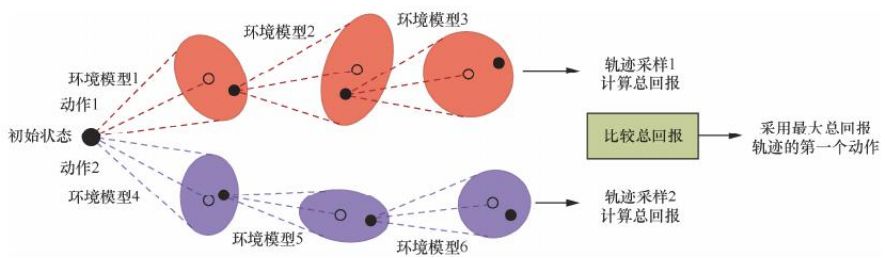
在次基础上使用集成(ensemble)方法捕捉认知不确定性。具体,构建 个网络框架一样的神经网络,输入状态动作对,输出下一状态的高斯分布的均值向量和协方差矩阵。但是每个网络采用不同的随机初始化方式,每次序列慧聪真实数据随机采用不同的数据来训练
有了环境模型的集成后,MPC 算法会用来预测奖励和下一状态。具体,每次会随机挑选一个进行预测,一条轨迹会用到多发模型
备注
环境模型
环境模型使用集成模型,是基于 torch 自定义的类,一个网络|一层网络里面集成了多个环境模型,