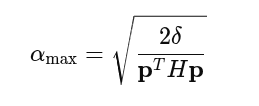我们从 TRPO 中关于 KL 散度约束的近似求解部分 开始。
一、背景回顾(轻量)
TRPO(Trust Region Policy Optimization)目标是:
最大化期望优势函数的同时,限制新旧策略之间的KL散度不能太大。
形式化目标是:
受限于:
二、为什么需要近似?
这个优化问题因为有 KL 散度的非线性约束,直接求解很难,于是 TRPO 采用了二阶泰勒展开来近似KL散度约束,从而把问题简化为一个带二次约束的优化问题(Quadratic Constrained Quadratic Programming,QCQP)。
三、KL 散度的二阶近似:Hessian 的出现
KL 散度对参数 做二阶泰勒展开,展开中心在旧策略参数 θold\theta_{\text{old}},记为 :
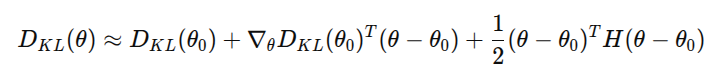
-
由于在 处,KL散度最小,所以一阶导数为0,即
-
所以最终近似为:
其中 H 是 KL 散度对策略参数 的黑赛矩阵(Hessian):
这个 散度是看旧的分布和当前的分布的散度,以旧的分布作为基准,当前的分布是变量,所以在 处,对应的分布就是旧的分布,两个分布一样,所以散度是 0,并且这个函数在 处最小为 0,一阶导数也是 0,这样 可以近似成剩下的余项
四、为什么这样做?
这一步关键是:
👉 把 难解的 KL 散度约束 变成了一个 关于参数差值 的 二次形式约束,就可以用 共轭梯度法 来近似解。
黑塞矩阵表明了周围的弯曲程度,我们希望通过它能让智能体指导,当学习的方向|当前更新方向的曲率很大的时候需要谨慎|减少更新步长,当周围很平的时候,可以增大学习的更新步长
但是起始只需要当前梯度更新的方向上的曲率就可以,我们可以从这个角度简化计算
首先原本的黑赛矩阵需要进行二阶求导,这个复杂度是 当网络的参数比较多的时候,计算量非常大,我们需要减少计算量 这里我们从两个角度来看待这个问题,一个看最优的方向,一个只看当前方向 最优方向
可以求解上式的 x 得到最大或者最小曲率的方向,其中 x 代表的是一个方向向量,当我们有一个确定的方向的时候, 就是这个方向上的曲率 (这里是反应当前方向陡峭程度,可能不是真实的曲率数值)
当前方向 当我们有了方向,方向记作 ,在共轭梯度计算中初始的 是目标函数的梯度
- 是目标函数的梯度
- 初始是 0,所以初始 是 , 是当前更新方向的梯度
- 后续迭代是在上一次基础上迭代
我们要做的是设定初始方向作为当前方向,通过迭代来调整方向,找到周围更平稳的方向,让模型的参数向着更平稳的方向优化。迭代次数通常少于数据的维度
为了保证学习的高效性,避免不同的学习相互影响,使用共轭梯度法保证学习不会倒退。共轭梯度法是说梯度更新的方向需要和其他向量空间维度垂直,即内积为 0。这样更新这个方向上的梯度不会影响到其他维度的梯度,如何保证呢?
共轭梯度算法通过迭代更新搜索方向 来保证:
其中:
-
是第 k 次迭代的残差(相当于梯度)
-
的选取保证了新方向和之前方向共轭
具体 通常选为:
五、 为什么这个更新保证共轭?
-
残差 是梯度的负方向(误差)
-
新方向 是当前残差加上之前方向的线性组合
-
这种线性组合调整了方向,使得 对之前的方向 满足 H-共轭条件
具体步骤:
- 初始化
-
(或其他初值)
-
残差
-
搜索方向
- 迭代更新
对于第 k 次迭代:
- 计算步长:
- 更新估计:
- 更新残差:
- 计算 :
- 更新搜索方向:
- 停止条件
- 残差足够小,或者达到最大迭代次数。
五、策略目标
TRPO 优化目标
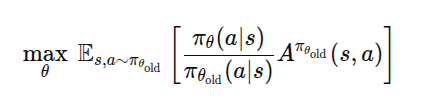
六、线性搜索
搜索的是步长,共轭梯度得到的优化方向的步长
搜索有一个步长上限