课程回顾
基于表格的强化学习

价值和策略的近似逼近方法

价值和策略近似
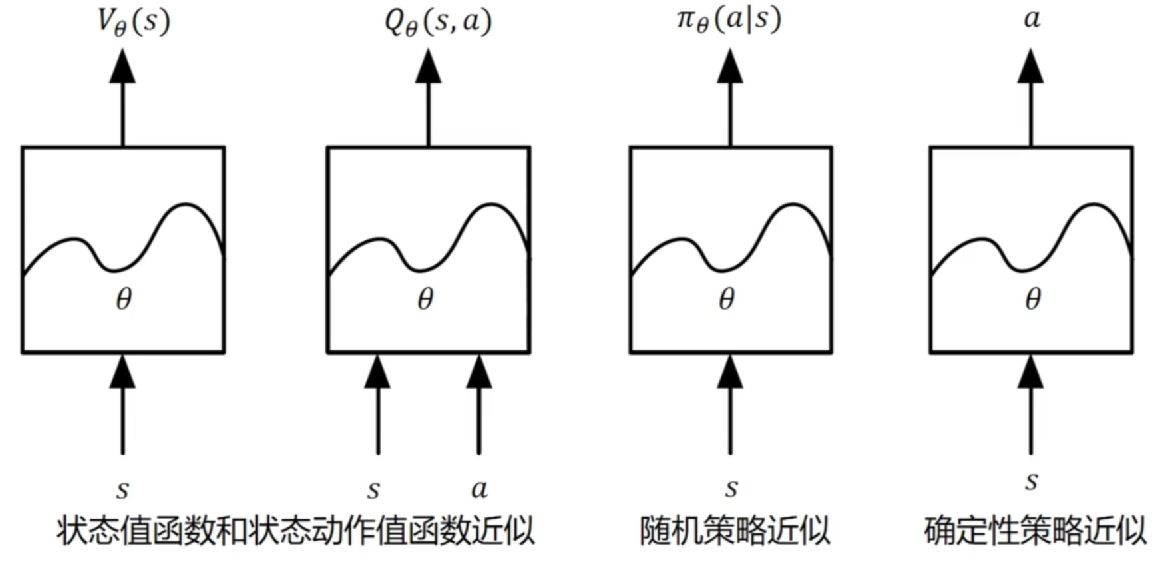
- 直接使用深度神经网络建立这些近似函数,这回带来哪些挑战,以及怎么解决?
端到端强化学习
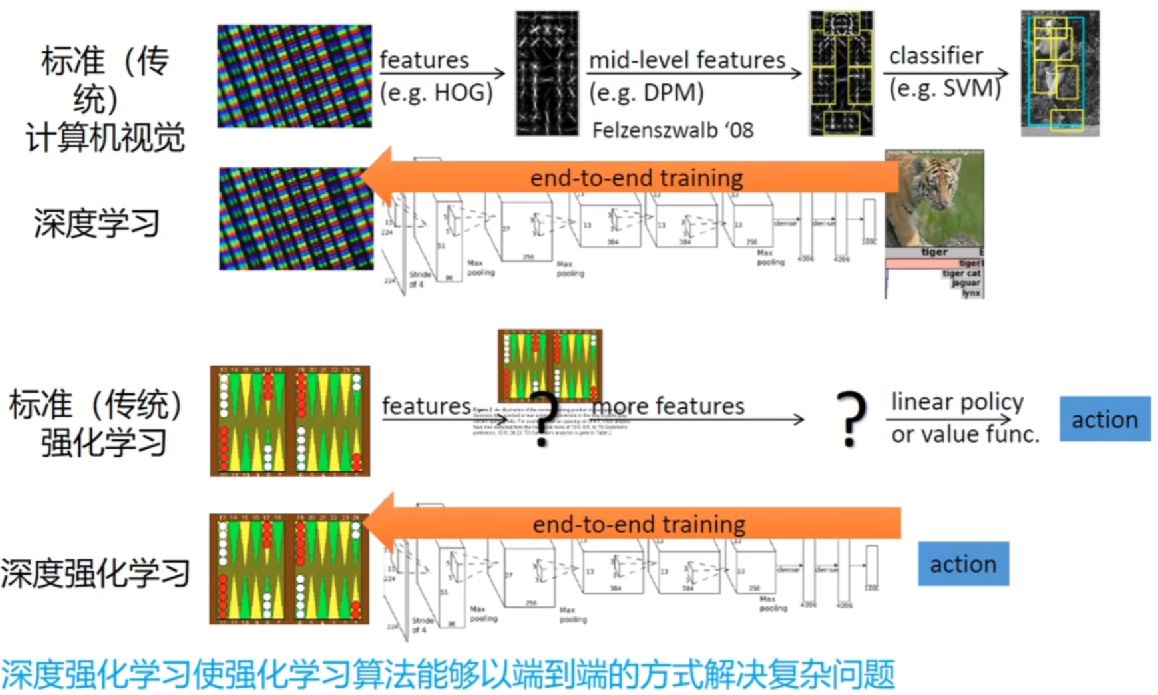
深度强化学习
- 深度强化学习
- 利用生度神经网络进行价值函数和策略近似
- 从何使强化学习以端到端的方式解决复杂问题
深度强化学习带来的关键变化

假如将深度学习(RL)和强化学习(RL)结合在一起会发生什么?
- 价值函数和策略现在变成了深度神经网络
- 相当高维的参数空间
- 难以稳定的训练
- 容易过拟合
- 需要大量的数据
- 需要高性能计算
- CPU (用于收集经验数据)和GPU(用于训练神经网络)之间的平衡
- …
深度神经网络本身的黑盒性,还有动态环境的黑盒性,多智能体学习,博弈中的纳什平衡的不确定性,这些不确定性增大了学习的难度
深度强化学习的分类
-
基于价值的方法
- **深度 Q 网络及其扩展
-
基于确定性策略的方法
- 确定性策略梯度(DPG),DDPG,TD 3
-
基于随机策略的方法
- 使用神经网络的策略梯度,自然策略梯度,信任区域策略优化(TRPO),近段策略优化(PPO),A3C
深度 Q 网络
深度 Q 网络(DQN)
Q 学习回顾
- 不直接更新策略
- 基于值的方法
- Q 学习算法学习一个由 作为参数的函数
- Target 值
- 更新方程
- 优化目标
处不参与计算梯度
Q 学习是离线学习。允许一定程度的脱离当前策略的分布。这样的特性和深度学习更加契合。 因为按照之前的 SARSA 算法,Q 函数是按照表格的方式进行更新的,进行一次的学习之后,Q 函数|表格中只有一部分数据发生了变化,而深度 Q 网络,学习一次之后,所有的模型参数都会发生改变,那么所有的数据就需要重新采样。 对于 Q 学习来说,只需要维持一个 data repaly buffer(数据缓冲池,可以维持一个较大的空间,来存最近采样到的数据,更远时间的数据可以逐渐切除),
直观想法 使用神将网络来比进上述
- 算法不稳定性
- 连续采样得到的 不满足独立分布
- 是状态-动作-下一状态-回报输入
- 的频繁更新
解决方法
- 经验回收
- 使用双网络结构:评估网络(evaluation network)和目标网络(target network)
关键在于局部采样出来的数据与全局的分布不一致,神经很容易去拟合到刚刚采样到的数据上,因为智能体和环境交互的过程中,采样不是均匀地, 不是全局的分布。而强化学习需要边采样边进行学习,这能提很容易拟合到最近的数据上,而其他数据的情况会发散掉 解决方法有两个,经验回放需要从数据缓冲池中按照一定策略|战术|方法抽取数据,抽取的方法用来克服数据分布的偏差 双网络结构,一个作为当前训练的网络,一个作为评估网络,评估网络不用每轮都更新,间隔一些轮次更新成单前训练的网络
经验回放
经验回放
- 存储训练过程中的每一步 于数据库 中,采样时服从均匀分布
优先经验回放 衡量标准
- 以 Q 函数的值和 Target 值的差异来衡量学习的价值,即
- 为了使各个样本都有机会被采样,存储
选中的概率
- 样本 选中的概率为
重要性采样
- 权重为
我们的目标是从数据缓冲池中采样出部分数据组成 mini batch 去更新 Q 函数。但是每次采样的时候肯定会碰到没有用的 data,那有没有办法每次都找到对我们学习很有用的数据,但是又等价于每次平均的从缓冲池中采样数据,答案是可以的,使用重要性采样的方法采样
就是按照优先性选择样本,但是在学习的时候使用重要性采样给他回归到平均采样的权重
这样的好处,对于一些采样概率很低,但是奖励很高的动作,我们能够采样到它,这样能够提升学习效率
算法:

目标网络
目标网络
- 使用较旧的参数,记为 ,每隔 步和训练网络同步一次
- 第 次迭代的损失函数为
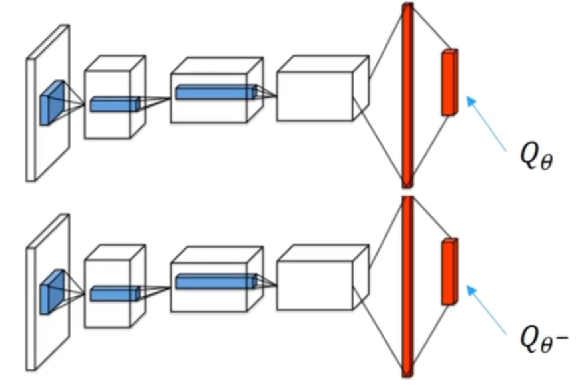
目标网络需要间隔几轮之后再同步,如果间隔较短,容易拟合到刚刚更新的数据上,导致 bias 很大
算法流程
-
收集数据:使用 策略进行探索,将得到的状态动作组 放入经验池(replay-buffer)
-
采样:从数据库中采样 个动作状态组
-
更新网络
- 用采样得到的数据计算
- 更新 Q 函数网络
- 每 次迭代(更新 Q 函数网络)更新一次目标网络
重复以上步骤
数据缓冲池可以使一个比较大的空间,来缓冲数据,更老的数据会逐渐切割,被新的数据覆盖
每 次对目标网络做一个参数值的拷贝,在 次之内更新评估网络的参数。这样评估网络学习的过程中每一个小阶段,目标网络都是稳定的|固定的,学习过程中目标应该是一个比较稳定的目标网络;如果马上更新了一部分参数,又把它作为目标来学习,这是很不靠谱的
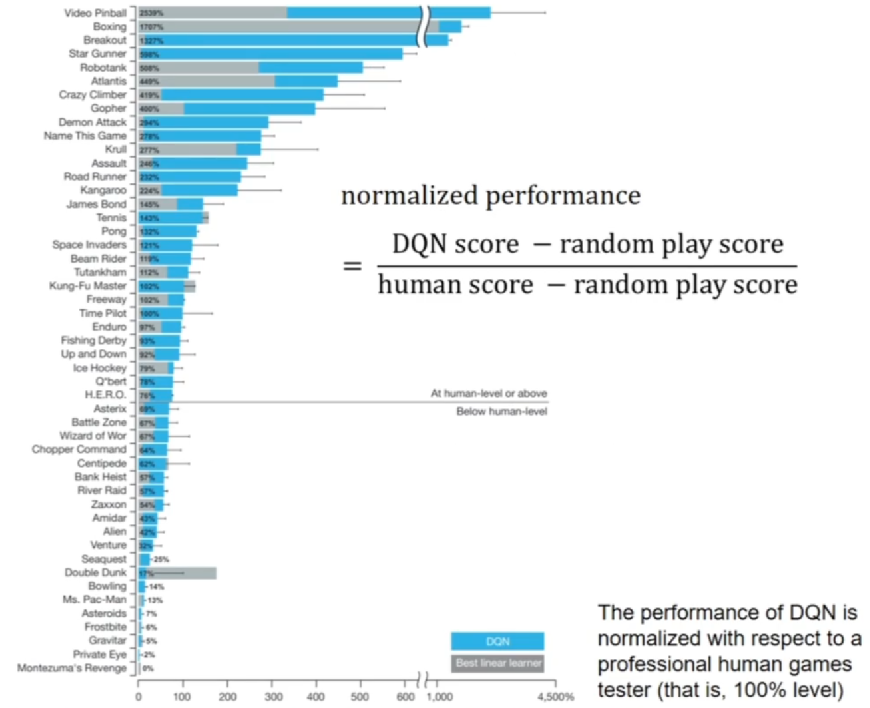
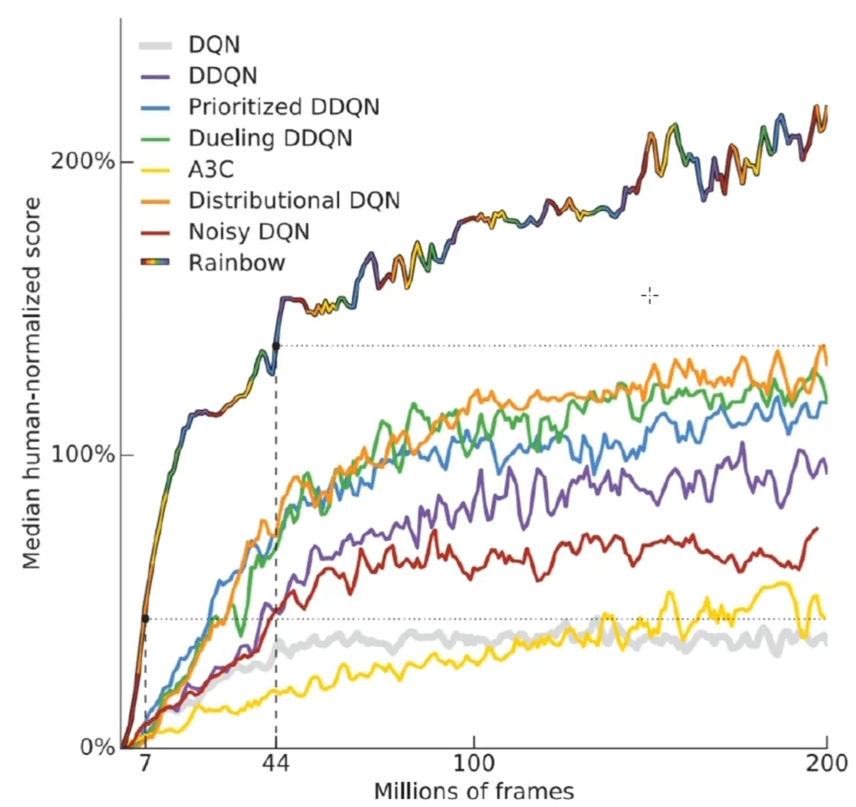
在 Atari 环境中的实验结果
Double DQN
Q-learning 中的过高估计
- Q 函数的过高估计
- Target 值
- 过高估计的原因
> 在 $\arg \max$ 选择的 $a^\prime$ 可能会由于 Q 函数错误的过高估计导致,如刚开始训练的时候,错误的估计值且数值很大,导致一直选择这个错误的动作,导致过高估计
- Q 函数的过高估计程度随着候选行动数量增大变得更严重
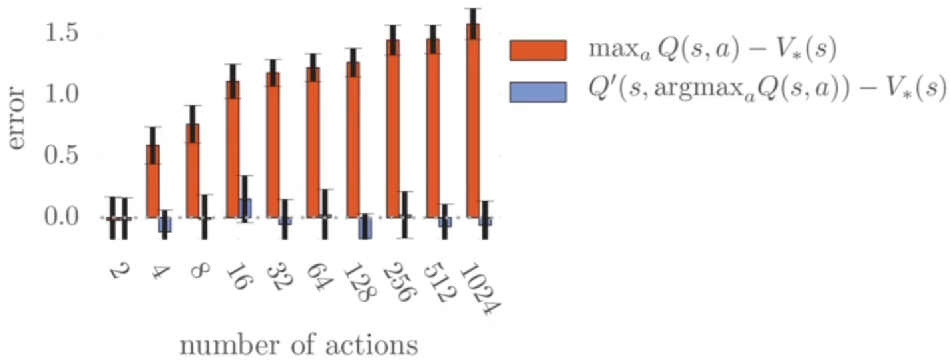
- 其中 设为在 区间均匀分布
- 函数是另一组独立训练的价值函数
Q-learning 中过高估计的例子
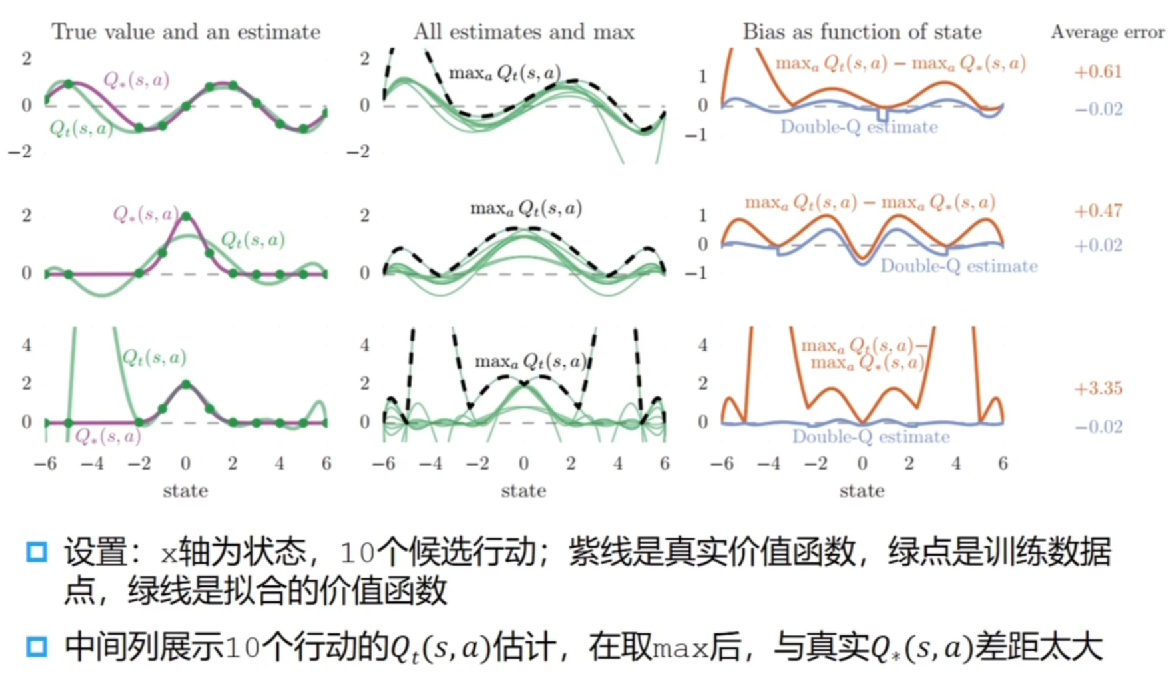
第二列可以看到取 max 之后很多价值非常高,会导致过高估计,让网络拟合到这些数值
- 使用不同的网络来估值和决策
这样 DQN 是运动员,Double DQN 是裁判
与DQN 的区别 首先 DQN 这里状态-动作空间是离散的,所以可以估计出max 以上公式是生成的目标值,需要网络生成的数值来拟合它 DQN 中目标值是目标函数自己的 max 数值,目标网络需要最大化他的价值,这时候需要选择最大价值的动作, 这个动作和主 Q 网络选择的不一定一样。DQN 只关心最后的价值数值够大 Double DQN 是先有主 Q 网络选出动作,再把动作交给 DoubleDQN|目标网络评估,目标网络不需要做 max 这个选动作的操作,只需要评估主 Q 网络选择的动作。这样减少了估计误差,但是目标网络还是使用的间隔几个轮次复制主 Q 网络参数
在 Atari 环境中的实验结果
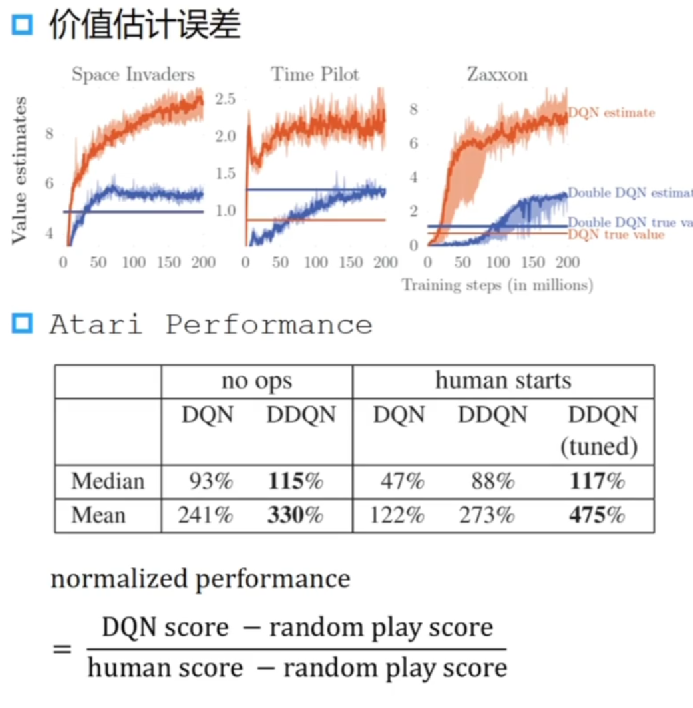
可以发现 Double DQN 的估计值更接近真实价值,但是 DDQN 的损失会更大一点,因为两个网络参数量更多
本人理解,单一模型存在估计过高问题,双模型能够缓解,是因为两个模型之间有一定对抗性,对于过高的动作,在另一个模型评估的时候可能没有这样高,也就是说很难两个模型同时对某一动作都有高的离谱的估计。这样两个模型相互影响来学习
Dueling DQN
假设动作值函数服从某个分布:
显然: 同样有:, 是偏移量
问题 如何描述 也称为Advantage 函数
Q 函数的问题是难以训练,我们可以使用 和 V 来表示 Q

网络结构
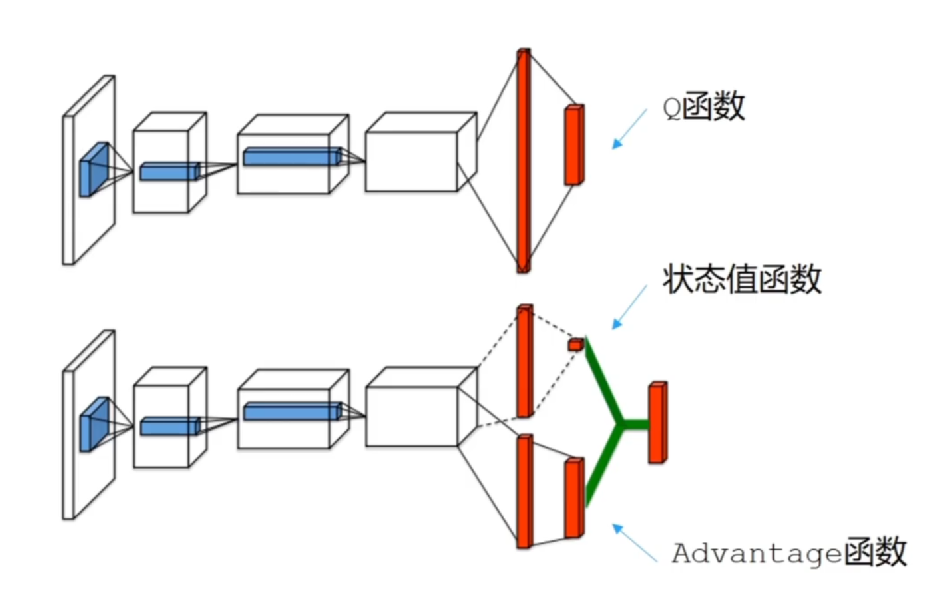
网络的输出分成两个分支,一条输出 V 函数值,一条输出 A 函数值,再把两条和到一起变成 Q 函数值 这样的好处:对于 Q 本身来说,对任何一个动作 a,要做出一个好的估计, 他需要依赖于(s, a)本身的表征的学习。但是如果 V+A 的话,对于一些 a 见得很少,只需要让 A 向向 0 走就可以,让 Q 回归到 V 的值,是对于Q 来说,他不一定回归到 0(这个状态可能没有足够训练,Q 的数值是不准的,可能过高|过低)
这就是在网络结构上能够提升的地方
优点
- 处理与动作关联小的状态
- 状态值函数的学习较为有效:一个状态值函数对应多个 Advatage 函数

Dueling DQN 的 Q 函数拟合更加精准,在附近有车的时候,注意力会更多的放到周围的车上面
探索任务:走廊环境
走廊环境
- 为起点状态
- 行动:上、下、左、有、不动
- 左下角有小的正向奖励
- 右上角有大的正向奖励
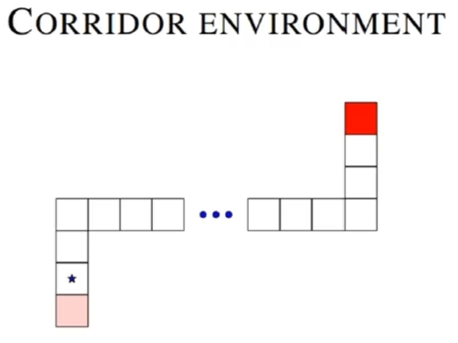
Q 函数评估均方误差
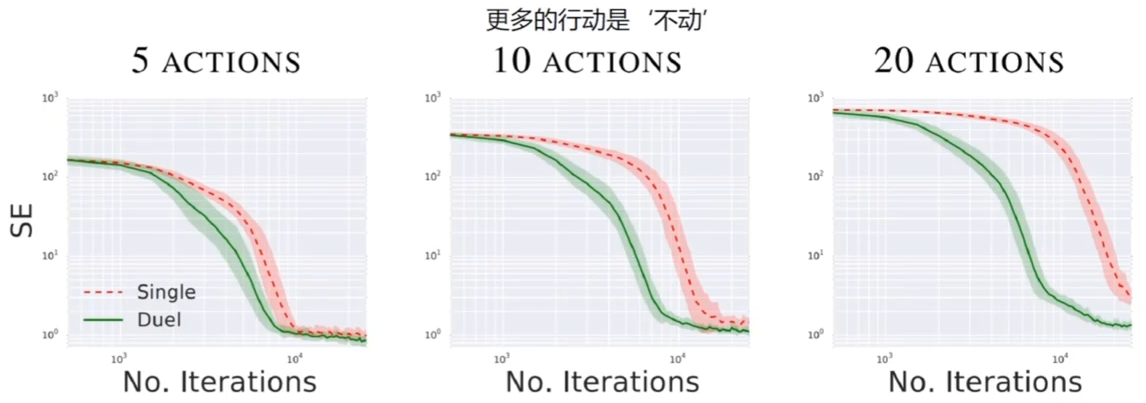
这个任务可以看出原始的 DQN 算法更倾向于左下角的小奖励,他的反应明显比 Duel DQN 迟钝,Duel DQN 学习的更快,能够看到右上角更大的奖励
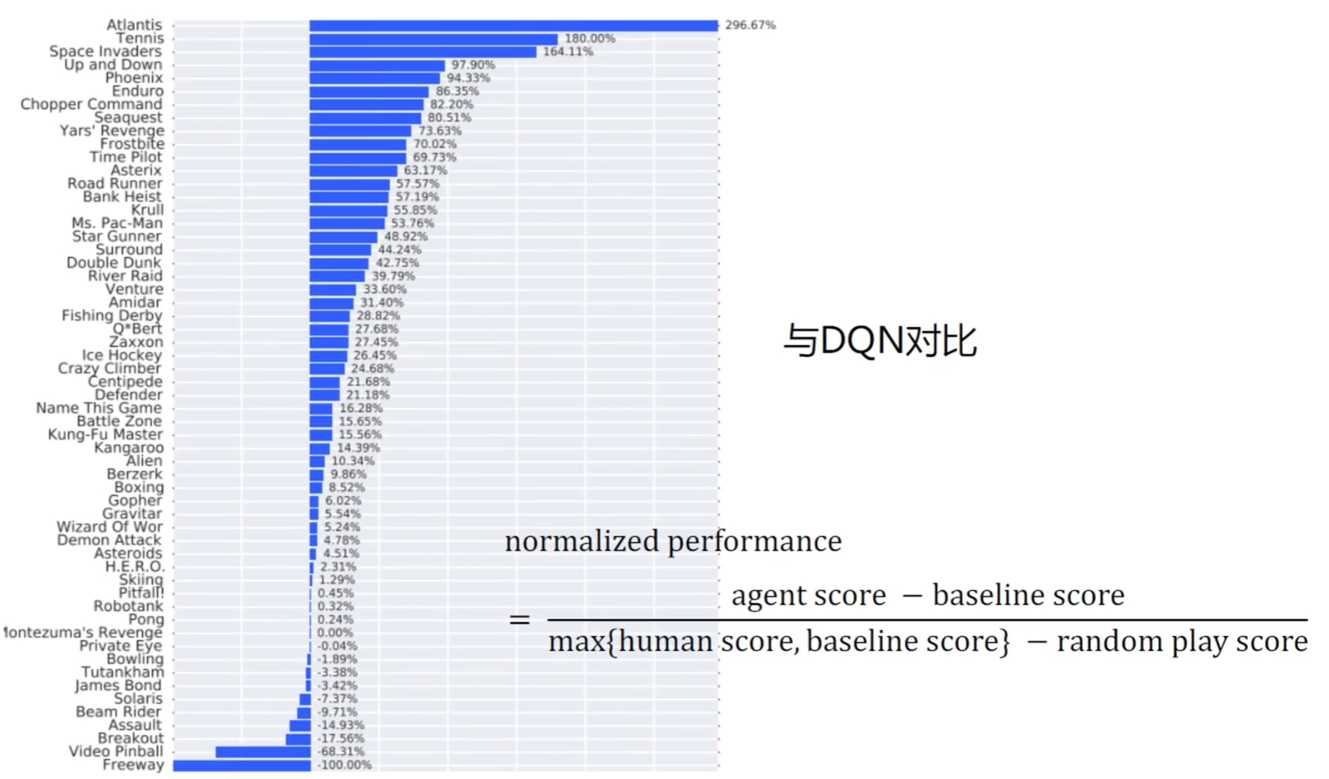
在 Atari 环境中的实验结果 1
在 Atari 环境中的实验结果 2
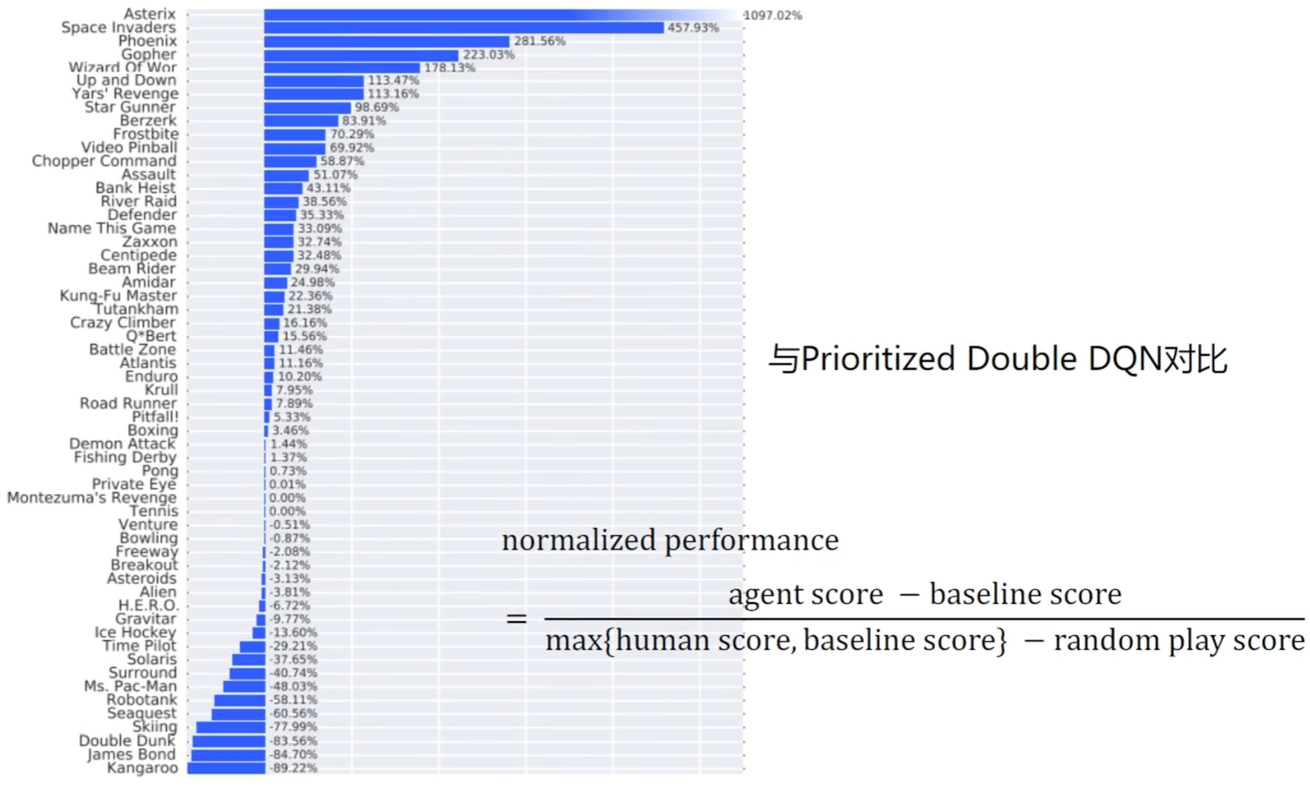
优先采样版本
深度强化学习算法总结

Rainbow:结合众多 Value-base DRL 方法
确定性策略梯度
确定性策略梯度(DPG),DDPG,TD 3)
随机策略和确定性策略
随机策略
- 对于离散动作$$ \pi(a|s;\theta)=\frac{\exp{Q_{\theta}(s,a)}}{\sum_{a^\prime}\exp{Q_{\theta}(s,a^\prime)}}
确定性策略
- 对于离散动作$$ \pi(s;\theta)=\arg\max_{a}Q_{\theta}(s,a)\ \text{不可微}
对于确定性策略,之后连续动作时可导
确定性策略梯度
用于估计状态-动作值的评论家(critic)模块
确定性策略
- 确定性策略梯度定理
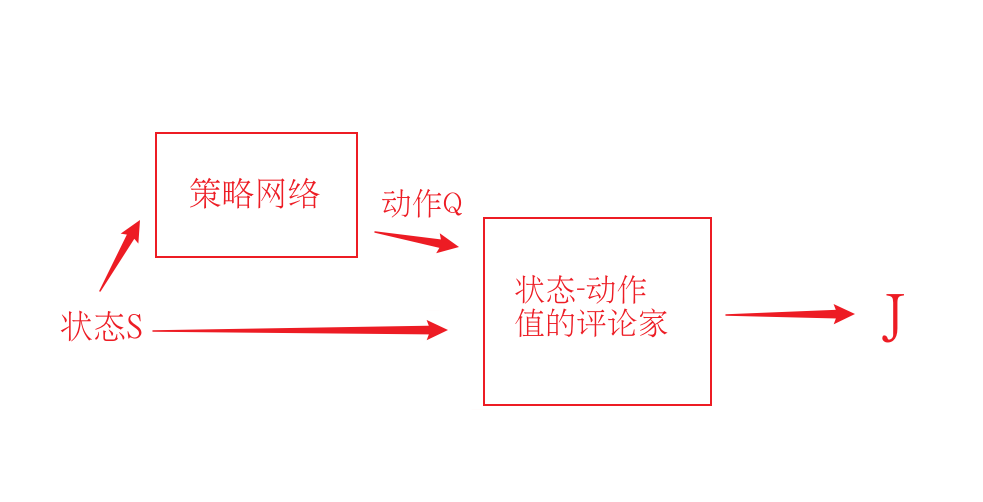 > 整个计算梯度的架构如图,这是一个比较在线的方法,因为需要当场采出来数据对策略的参数进行更新 ## 确定性策略梯度实验结果 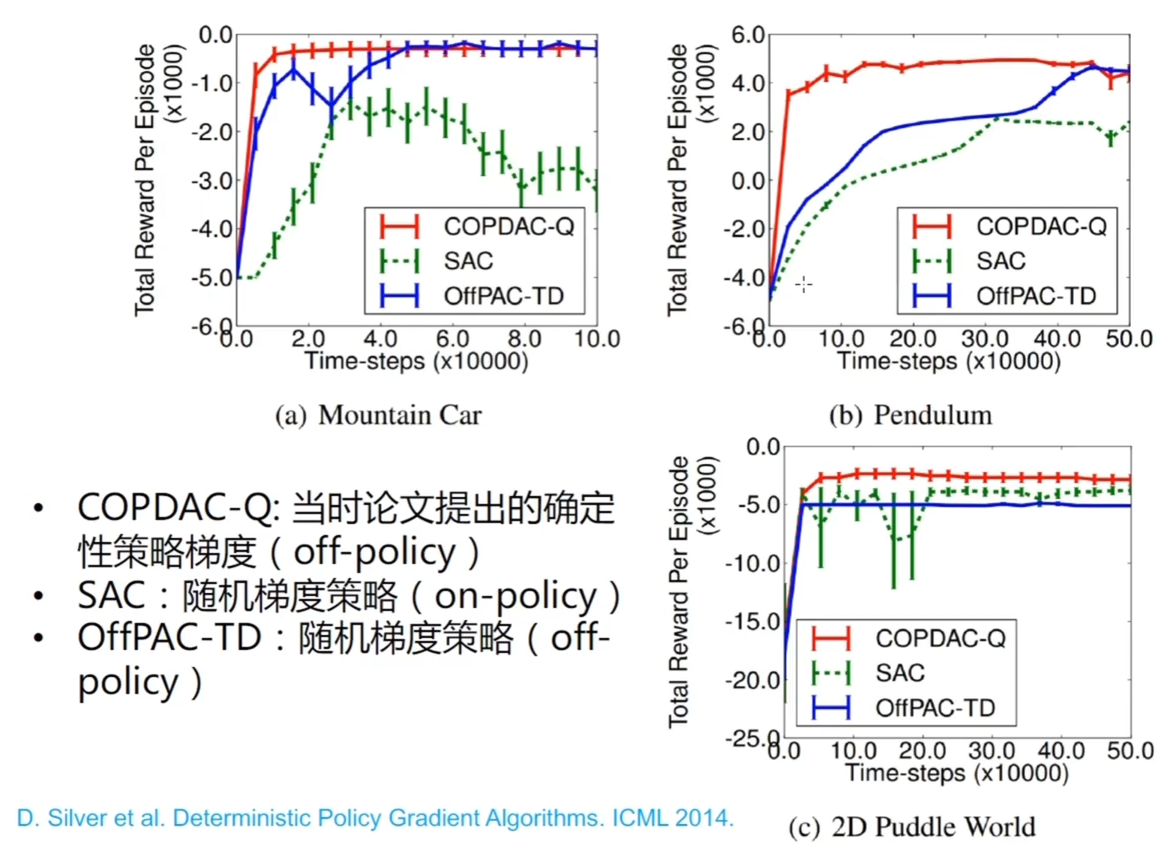 # DDPG:深度确定性策略梯度 - 对于确定性策略的梯度是参数化的 Q 函数模型,这里构造的策略 也是参数化的模型 这里的 a 实际上是 的输出值,损失函数求导,需要展开到 Q 里面的 a,也就是策略 $\pi$$$ \begin{array}{c} \ \begin{align} J(\pi_{\theta})&=\mathbb{E}{s\sim \rho^\pi}\left[Q^w(s,a)\right] \ &=\mathbb{E}{s\sim \rho^\pi}\left[Q^w(s,\pi_{\theta}(s))\right]
\end{align} \ \ \frac{\partial Q}{\partial \theta}=\frac{\partial Q}{\partial a}\frac{\partial \pi_{\theta}(s)}{\partial \theta}|{a=\pi{\theta(s)}} \end{array}
\nabla_{\theta}(\pi_{\theta})=\mathbb{E}{s\sim\rho^\pi}\left[\nabla{\theta}\pi_{\theta}(s)\nabla {a}Q^\pi(s,a)|{a=\pi_{\theta}(s)}\right]
- 在实际应用中,这种带有**神经函数近似器的 actor-critic**方法在面对有挑战性的问题是**不稳定地** - **深度确定性策略梯度**(DDPG)给出了在**确定性策略梯度**(DPG)基础上的解决方法 - 经验重放(离线策略|数据缓冲池) - 目标网络 - 在动作输入前标准化 Q 网络 - 添加连续噪声 > 使用在线策略更新参数(指上面的确定性策略),它当场采出来的数据分布是局部分布的,,全局的数据是不能全部采到的  > 选择动作的时候加上一个噪音(==噪声原版使用是 OU 噪声,适合惯性系统,这里简化为高斯噪声==),如果策略是一个连续的分布,那他的探索性无法保证,添加的噪声相当于探索 > 建立 data repaly buffer(数据缓冲池)。如果使用在线学习的方法,数据都是刚刚采集出来的局部数据,用来训练容易局部过拟合 > DDPG 使用了离线策略来采样数据,不论是平均从数据池中采样,还是按照一定策略|方法来采样 > > 对比似然比方法,似然比是用来衡量两个策略分布函数的,来拟合两个函数分布;DDPG 方法更直接策略动作和状态是点对点的,更新更直接 > > 再加上目标网络,Q 和策略都有一个对应的目标网络(就是用前几轮的网络的参数的网络),因为每次学习都会更新整个网络的参数,如果每次学习的目标值都是前一轮的,学习会很不稳定;尤其是 TD 更新的方式,学习的目标一直在变 > > 使用一个小批量的数据来学习,使用批标准化,我们希望网络能够工作在一个更加稳定的数值之上,由于使用离线学习|off-policy 输入的数据分布和当前学习的策略分布是不一致的,做了批标准化之后,输入数据会相对更加稳定 ## 深度确定性策略梯度实验 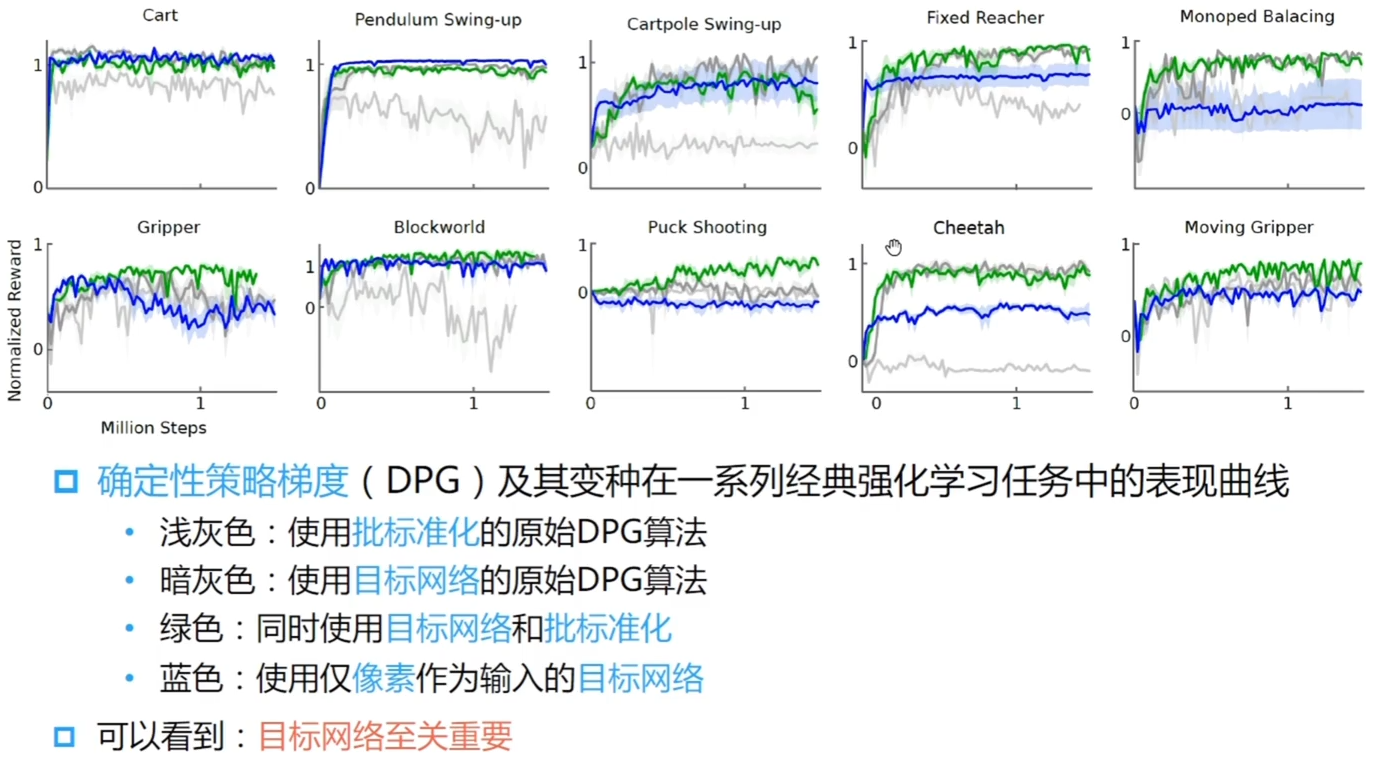 > 在机器人等需要确定性策略,不是随机策略的场景会使用 DDPG 进行策略控制 # 双价值函数策略演示更新-Twin Delayed DDPG(TD 3)\begin{align}
J(\pi_{\theta})&=\mathbb{E}{s\sim \rho^\pi}\left[Q^w(s,a)\right] \
&=\mathbb{E}{s\sim \rho^\pi}\left[Q^w(s,\pi_{\theta}(s))\right]
\end{align}
\nabla J(\pi_\theta) =\mathbb{E}{s\sim \rho^\pi}\left[\nabla {\theta}\pi{\theta}(s)\nabla{a}Q^\pi(s,a)|{a=\pi{\theta}(s)}\right]
- 在 DDPG 实际应用中,仍然有对 Q 函数过高估计问题 - $\pi$ 可能使用 Q 函数的漏洞(exploitation)(就是 Q 函数对一些没有见过的动作有过高的估计,导致策略钻到这个漏洞) 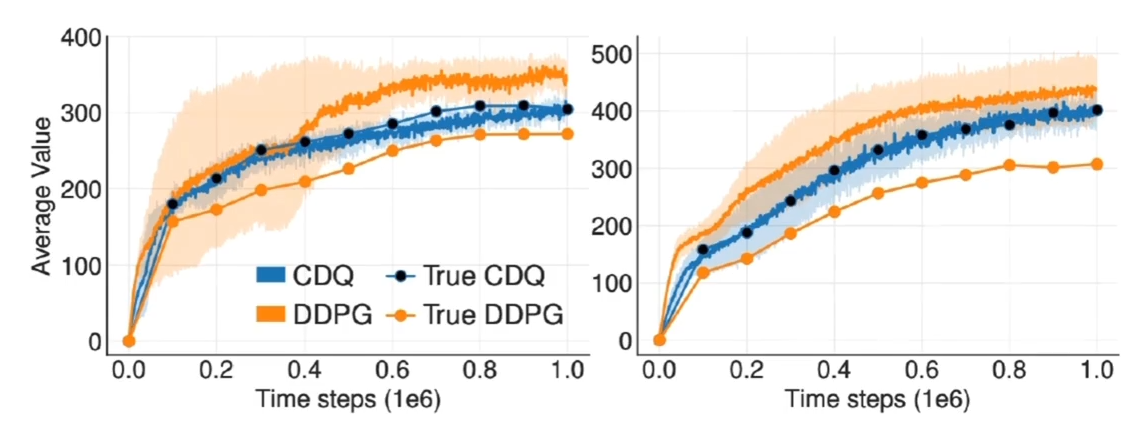 > 如上图,DDPG 对自己的价值有了过高的估计,远高于实际值  ## TD3:双价值函数策略延时更新 - Twin Delayed DDPG (TD 3)  > 1. 对策略输出做平滑操作,先给输出的动作加上噪音,噪音是经过 clip 的(clip 是对数值值进行限制,过大或过小的数据会被屏蔽掉),再对和clip > 2. 学习两个 Q 函数,使用其中更小的数值的目标网络的数值作为目标(**防止过高估计**),来做为一次更新的当前网络,两个网络都向这个目标学习。这里的 Q 有两个对应的目标网络和两个当前学习的网络, 还有目标策略网络和当前学习的策略网络 > 3. 策略策略学习使用最大化期望学习,这里只是用 $Q_{\theta_{1}}$,$Q$ 网络相当于策略的评估器,也做类似损失函数的工作,这里更新策略网络参数时 $Q$ 网络相当于损失函数,只用来更新策略网络。期望是用来平均小批次数据的学习梯度,由于神经网络的损失函数是计算更小数值,这里需要加上一个负号 > 4. 策略参数更新延迟,Q 函数更新更快,学习的更快,Q 作为裁判能够更好的评估策略这个运动员的做出的动作,否则学习会不稳定。两个网络水平不能相差太大,且裁判要更聪明一点,所以 Q 网络更新更多 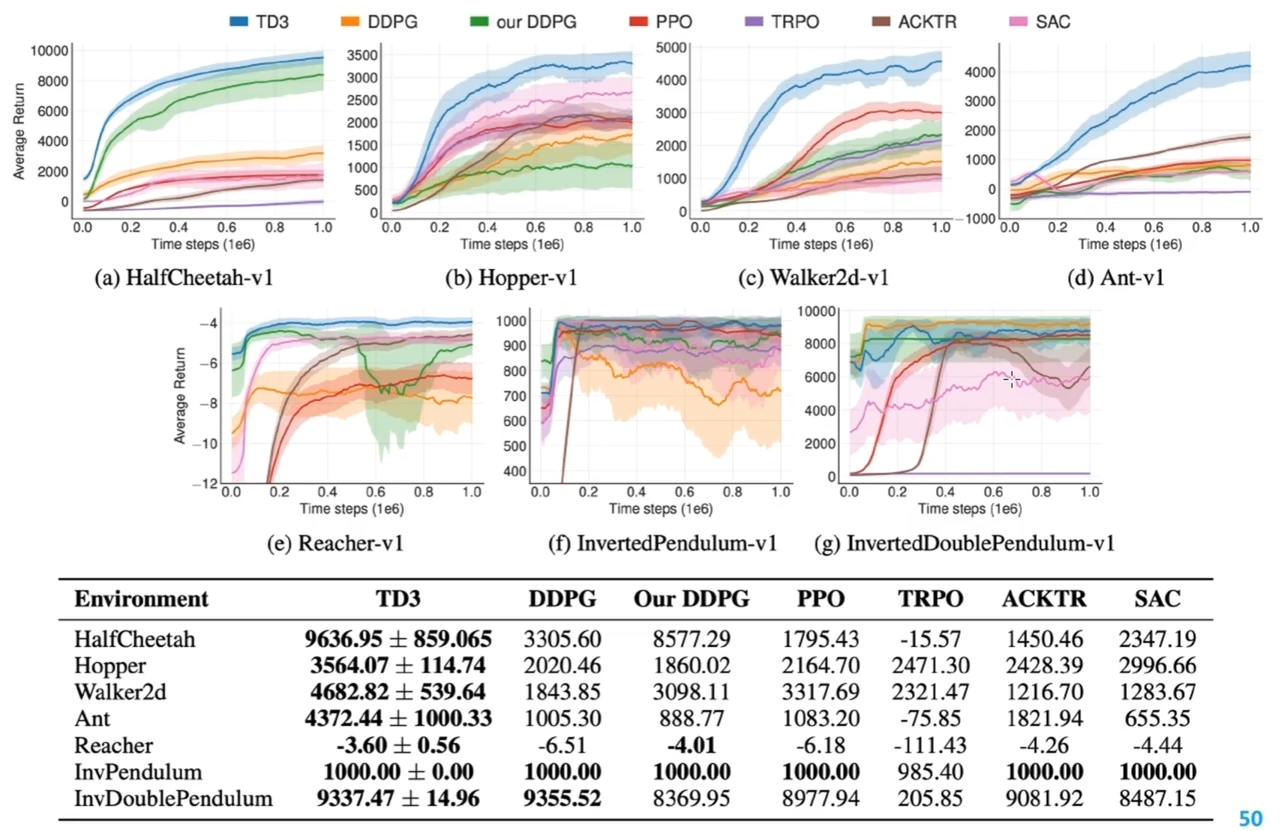 > 这种双生网络的方法,也可以加入到后续的基于策略的学习方法 # 深度强化学习总结  - 直面理解:深度学习+强化学习 - 深度强化学习使强化学习算法能够以端到端的方式解决复杂的问题 - 真正让强化学习有能力完成实际决策任务 - 比强化学习和深度学习各自都更加难以驯化 - 基于价值函数的深度强化学习 - DQN:一次输入多个行动 Q 值输出、目标网络、随机采样经验 - Double DQN:解耦合行动选择和价值估计、解决 DQN 过高估计问题 - Dueling DQN:精细捕捉价值和行动的细微关联、多种 advantage 函数建模 - DDPG:对价值函数求动作的导数,在根据链式法则对策略参数求倒数 - TD 3:用两个价值函数做 clip 来缓和过高估计,对策略输出做平滑,策略更新延缓 > 这里 DDPG 和 TD 3 是使用了策略函数,但是使用了 Q 价值函数来评评估,这里列到了基于价值的方法这一节