基于模型的强化学习(MDP)中,值函数可以通过动态规划计算获得
在模型无关的强化学习中,无法直接后去 和 ,但是我们有依稀恶劣可以用来估计值函数的经验
蒙特卡洛方法
蒙特卡洛方法是一类应用广泛的计算算法,生活中处处都是 MC 算法 依赖重复随机抽样来获取数值的结果
蒙特卡洛价值估计
目标:从策略 下的经验片段学习
回顾:累计奖励是总折扣奖励
值函数是期望累积奖励
- 上述公式代表,使用策略 从状态 采样 N 个片段
- 计算平均累计奖励
蒙特卡洛策略评估使用经验累积奖励而不是期望累计奖励
实现
使用策略 采样片段 在一个片段中的每个时间不长 t的状态 s都被访问
- 增量计数器
- 增量总累计奖励
- 价值被估计为累计奖励的均值
- 由大数定律有, 当采样趋向无穷, 接近真正的价值函数
增量蒙特卡洛更新
在每一个片段结束之后逐步更新 对于每一个状态 和对应累计奖励
对于非稳定问题(即环境随时间发生变化),我们可以跟踪一个现阶段的平均值(即,不考虑过久之前的片段)
这个式子和之前相比修改了步长,现在步长是一个固定值,这中情况下 V 不是收敛的,可以随环境变化而变化,这种情况实际中更多
蒙特卡洛值估计
思路
实现
从 N 次数据轨迹中估计价值函数 ,采用增量式更新的方式更新; 是其中一条轨迹的收益
蒙特卡洛方法:直接从经验片段学习 蒙特卡洛是模型无关的:未知马尔可夫决策过程的状态转移/奖励 蒙特卡洛从完整的片段中学习:没有使用 booststrapstrapping(自举法)的方法 蒙特卡罗最简单的思想:值(value)=平均奖励(mean return)
注意:只能将蒙特卡洛方法应用于有限长度的马尔可夫决策过程中 即,所有片段都有终止状态
重要性采样
关于上述值估计的数据的采样方法的讨论 问题出现在,一开始按照初始策略采样得到数据,这个数据是死的,固定的 在我们更新了策略之后,数据我们还要接着用,这时候由于策略的改进,数据的分布会发生变化,和现在的策略的数据分布不同,因此需要调整数据分布
估计一个不同分布的期望
将每一个实例的权重重新分配为
这里很容易发现问题, 很容易数值过大,存在风险
使用重要性采样的离线策略蒙特卡洛
-
使用策略 产生累计奖励评估策略
-
根据两个策略之间的重要性比率对累计奖励 进行加权
-
每个片段乘以重要性比率
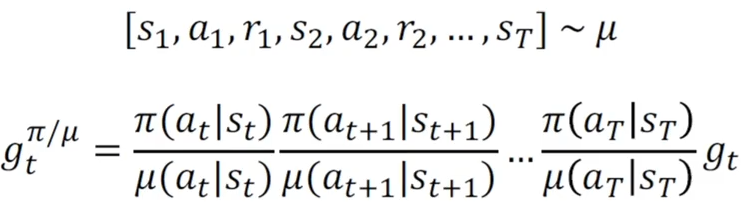
观察可以发现,这里的重要性比率是针对整个轨迹的,需要把整个轨迹中的每一步的比率连续相乘,很容易导致数值不稳定,数值方差变大,导致学习效果变差
-
更新值函数以逼近修正累计奖励 存在问题:无法在 非零,而 为零的时候使用;重要性采样将大大增大方差
使用重要性采样的离线策略时序差分
12:53
- 使用策略 产生的时序差分目标和策略目标
- 根据重要性采样对时序差分目标 加权
- 仅需要一步来进行重要性采样修正
重要性采样修正: 时序差分目标:
优势:
- 具有比蒙特卡洛重要性采样更低的方差(蒙特卡洛需要采样轨迹,这里只需要单步信息)
- 策略仅需要在单步中被近似
时序差分学习 (Temporal Difference Learning)
观测值: 对未来的猜测:
- 时序差分方法直接从经验片段中学习
- 时序差分是模型无关的
- 不需要预先后去马尔可夫决策过程的状态转移/奖励
- 通过 bootstrapping,时许差分从不完整的片段中学习
- 时许差分更新当前预测值使之更接近估计累积奖励(非真实值)
时序差分和蒙特卡洛对比
蒙特卡洛使用 来计算当前收益,而计算 需要用到整条轨迹的数据来计算,同时也需要轨迹有明显的结束状态,这个计算量取决于轨迹数据长度,计算量会比较大,同时使用重要性采样会产生连乘的重要性比率,连乘会导致数据方差变大
时序差分采用 来估计 ,这样只需当前动作的收益 和当前价值函数对未来的估计就可以,这样可以进行片段化学习,不需要一个完整的轨迹,使用重要性采样也不会有连乘问题,自然会减少方差(vanriance),但是使用 函数来估计未来值并且对自己进行更更新,会产生偏差(bias),这里用偏差换取了方差的减小,使模型的泛化性更好
对于无模型强化学习 强化学习需要状态转移矩阵 和价值 价值可以从观测中得到,状态转移矩阵是我们需要解决的问题
蒙特卡洛(MC)和时序差分(TD)优缺点
时序差分:能够在最后结果之前进行学习
- 时序差分能够在每一步之后进行在线学习
- 蒙特卡洛必须等待片段结束,直到累积奖励已知
时序差分:能够无需最后结果进行学习
- 时序差分能够从不完整的序列中学习
- 蒙特卡洛只能从完整的序列中学习
- 时序差分在连续(无终止的)环境下工作
- 蒙特卡洛只能在片段化的(有终止的)环境下工作
蒙特卡洛具有高方差,无偏差
- 良好的收敛性质
- 使用函数近似时依然如此
- 对初始值不敏感
- 易于理解和使用
时序差分具有低方差,有偏差
- 通常比蒙特卡洛更加高效
- 时序差分最终收敛到
- 但是使用函数近似并不总是如此,因为有偏差
- 比蒙特卡洛对初始值更敏感
随机游走的例子
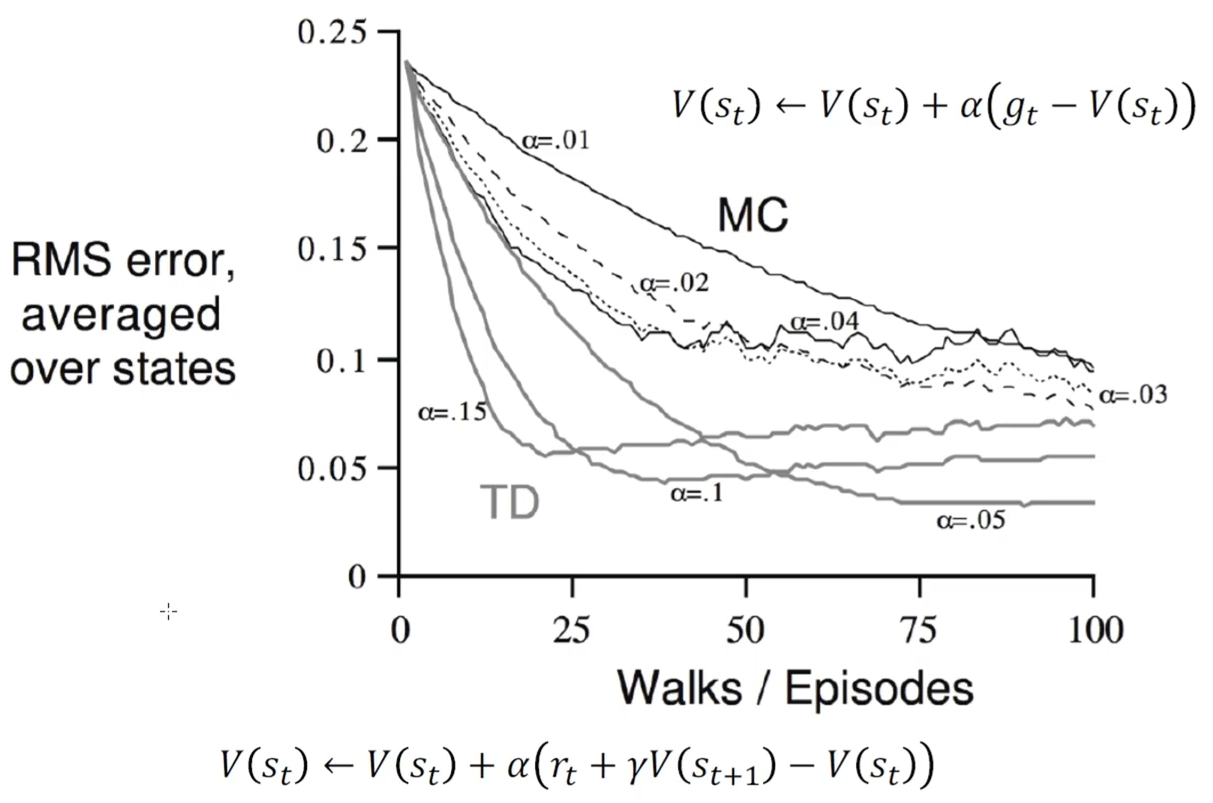
蒙特卡洛方法(MC)下降的比较平稳,但是下降的比较浅, 比较大的时候,震荡比较明显
时序差分算法(TD)下降的更深,且下降的更快,但是学习一段时间之后,loss 会逐渐回弹,这是由于偏差存在
对比深度学习中的反向传播算法 在强化学习中,也是通过后续的价值函数来学习当前状态的价值函数,也有一个反向传递的过程
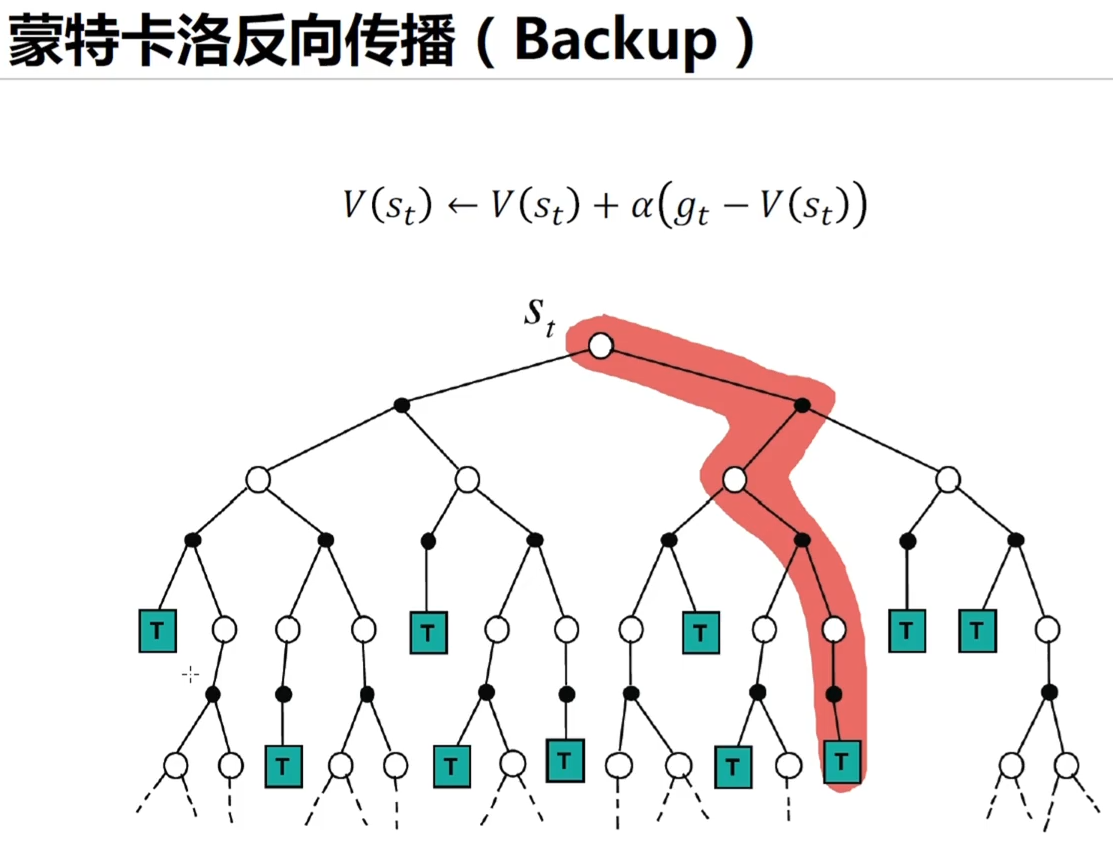
蒙特卡洛方法需要先计算完一整条轨迹的 ,才能计算出当前的
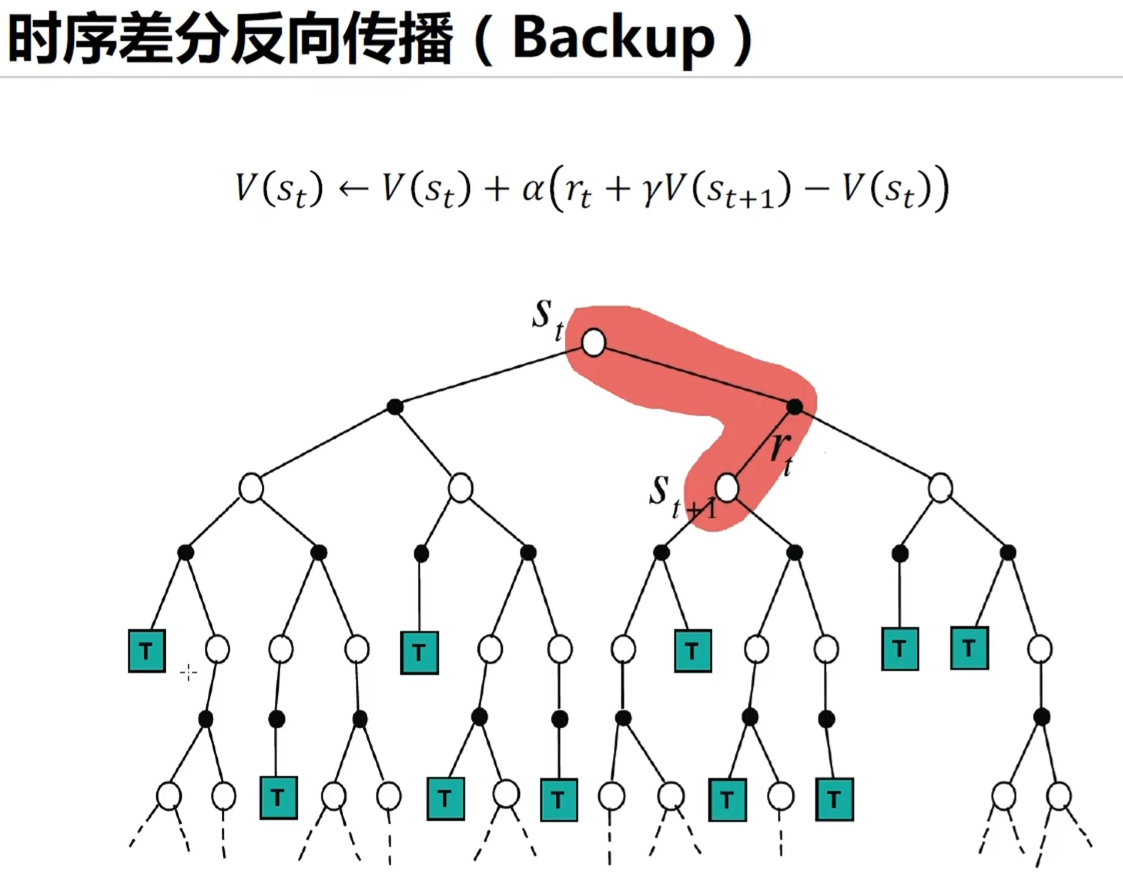
时序差分只需要当前动作收益和对下一状态的估计,下一状态的估计还是使用 来算,它是自助|自举的
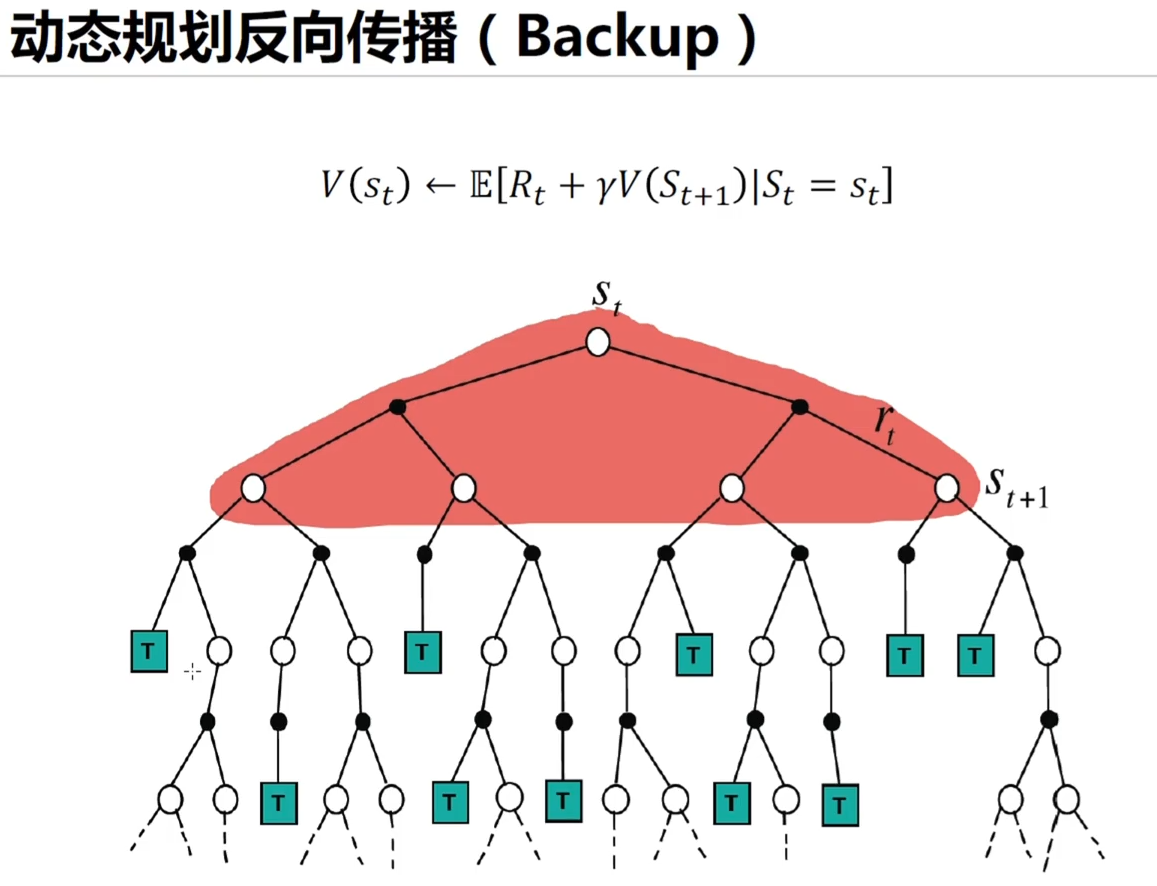
更像广度搜索,一层一层的把所有状态都计算完毕,做的全部的 和
多步时序差分学习
- 对于有时间约束的情况,我们可以跳过 n 步预测的部分,直接进入无模型的控制
- 定义 n 步累计奖励
- n 步时序差分学习
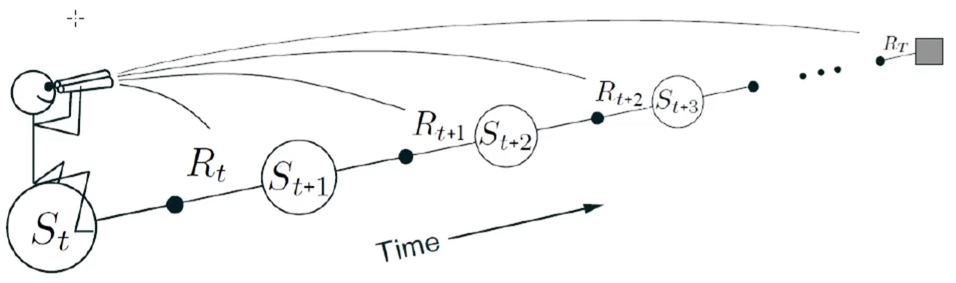
总结:n 步时许差分步数很多是相当于 MC 方法,因此方差也会变大,这里选择不同的 n ,可以达到偏差和方差之间的平衡,让模型有更好的泛化能力
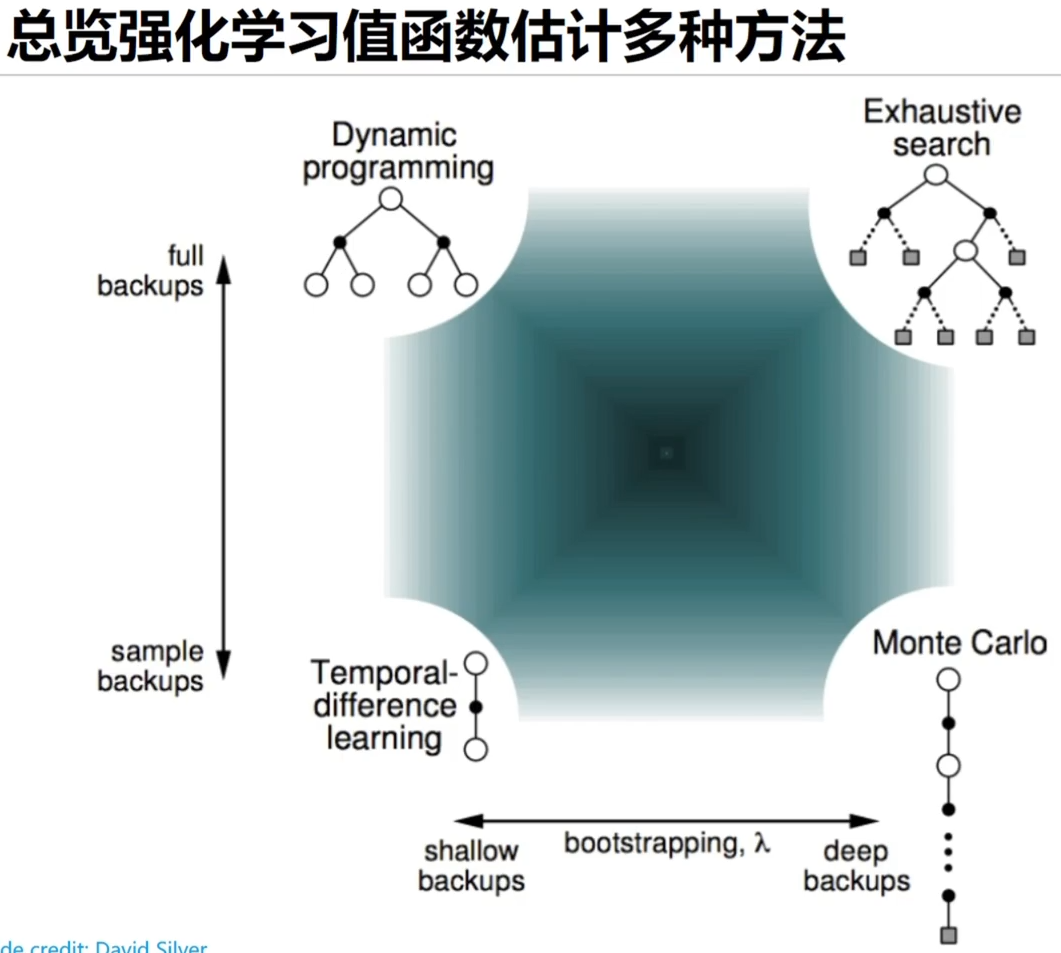
值函数估计总结
- 无模型的强化学习在黑盒环境下使用
- 要优化智能体的策略,首要任务是精准高效的估计状态或者(状态,动作)的价值
- 黑盒环境下,值函数的估计方法主要包括蒙特卡洛方法和时序差分方法
- 蒙特卡洛方法通过采样到底的方式来直接估计价值函数
- 时序差分学习通过下一步的估值来更新当前一步的价值估计
- 实际使用中,时序差分方法更常见