只能作为一部分骨干网络,对 3 D 目标识别没有特别设计
简要介绍
- 后续工作如 StruMamba3D、UniMamba 等在自监督、统一时空/通道表示或把卷积与 SSM 结合方面做了延伸(更多结构化/多尺度的 SSM 变体)。
核心问题 之前的点云方法仍然面临两个关键问题:
- SSM 处理过程中破坏了 3 D 点的邻接性
- 在下游任务中随着输入长度的增加,未能保留长序列记忆
StruMamba 3 D 的优点
- 设计了空间状态,将其作为代理来保留点之间的空间依赖性
- 通过一种状态更新策略增强了 SSM,并结合了一个轻量级卷积来促进空间状态之间的交互,以实现高效建模
- 通过引入序列长度自适应策略,降低了预训练的 Mamba 模型对不同长度的敏感性
Stru-Mamba 的两个核心组件
- 结构化 SMM 块
- 序列长度自适应策略
核心贡献
- 提出了 StruMamba 3 D 用于自检度点云表示学习,这是首次在 SSM 的潜在装体中建模结构信息
- 设计了结构化 SSM,在状态信息选择和传播过程中保持点之间的空间依赖性,同时序列长度自适应策略降低了预训练的 Mamba 类模型对不同输入长度的敏感性
- 在四个下游任务上的实验结果展示了我们方法的优越性能
此外,消融试验验证了设计的有效性
概述
首先通过最远点采样和 KNN 采样得到初始输入,然后使用轻量级 PointNet 提取特征作为 token 嵌入 ;同时,将空间状态 初始化为原始点云中局部结构的代理
这里的局部结构的代理,是 FPS 采样得到的关键点?
最后将空间状态和输入 token 嵌入输入到网络中
结构化 SSM 模块
目标 该模块旨在让 SSM 处理过程中 保留点之间的依赖关系来捕获复杂的结构特征,分为五个模块:
空间状态初始化
存在问题:原始 Mamba 中,潜在状态不包括几何信息, 这使得建模点云的局部结构变得困难
为解决该问题,在潜在问题中引入了位置属性,使每个状态都能关注点云的不同区域。由于点云的稀疏性,根据原始点 初始化状态位置 ,以确保点云的全面覆盖
具体,采用 FPS 和 KNN 聚类将点云分割成组 \{\begin{align}\cal{G}_{m}\end{align}\} ^M_{m=1},并计算其质心:
其中 是第 m 个状态的位置属性。将具有位置属性的状态称为空间状态,然后使用线性映射 将位置属性嵌入为初始状态特征:
状态 随后被用作 SSM 的初始潜在状态,并与输入 token 一起更新
状态更新机制
存在问题:原始 Mamba 的状态更新和传播方程依赖与输入 token,而忽略了输入点和空间状态之间的空间关系。这一限制是的 Mamba 难以有效建模点云的结构信息
为解决该问题,修改了状态更新和传播方程,以显示的建模状态和输入之间的空间依赖关系
具体,首先计算输入点 与状态位置 之间的相对偏移:
其中, 表示第 i 个输入点与第 m 个状态之间的相对偏移。接下来将偏移映射到 SSM 参数 ,这些参数控制状态更新和传播
但是只考虑空间关系是不够的,因为信息的重要性因点而异。因此设计了一下的状态更新和传播机制:
其中 MLP 是多层感知机, 是线性投影, 表示第 个输入点的特征。基于修改后的参数,空间状态可以利用同一区域内的点选择性的更新特征,而输入点可以从状态中获取局部结构信息
实际上,是聚合了小邻域内的点的特征,增强了局部特征的感受; 不只是使用空间关系控制 SSM 参数更新,还融合了提取的特征
结构化 SSM
存在问题:单向扫描机制,无法实现输入点之间的双向信息交换
未解决高问题,采用了 VisionMamba 启发的双向扫描机制
具体,使用前向和后向结构化SSM,后向 SSM 以相反的顺序处理输入点;两者都使用空间状态 作为初始状态 ,为输入点和状态空间生成更新后的特征
最后,使用线性层 融合这些输出,以获得输入点和空间状态的最终特征 和
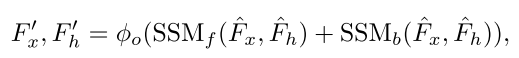
轻量化卷积
结构化 SSM 能有效建模空间状态 和输入点 之间的依赖关系。但是 SSM 中的空间状态 仍然是孤立的,彼此之间缺乏直接交互
替换了原始 SSM 中的 1 D 卷积层
为解决该问题,引入一个轻量级卷积模块。受图卷积的启发,该模块基于相对位置信息聚合邻近状态的特征。
具体,对于每个空间状态 ,首先识别其 k 近邻 并计算相对位置 。然后,使用线性层 为每个邻居生成注意力权重 ,然后进行 softmax 操作:
每个状态 的输出状态特征 通过加权聚合获得:
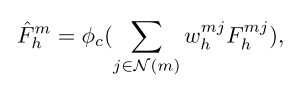
这里是对每一个邻域内部,使用权重重新获得聚合特征
其中, 表示邻域状态特征(邻域内每个点的), 是一个线性层
通过拓展空间状态的感受野,这种轻量级卷积增强了他们捕获全局语义信息的能力,将其替换 Mamba 块中的因果一维卷积,使其更适合处理具有复杂结构的几何结构的输入的点
序列长度自适应策略
存在问题:未解决下游任务中序列记忆不足的问题,我们提出了一种序列长度自适应策略,该策略继承了自应状态更新机制和空间状态一致性损失
自适应状态更新机制 SSM 参数更新中,参数采样间隔 通过影响 SSM 中的参数 来控制状态更新的频率
较大的 会使模型更频繁地更新状态特征;较小的 会允许模型以最小的改变量保持当前的状态
为了在下游任务中为更长的序列保留内存,提出了一种自适应状态更新机制。改机制根据输入序列长度调整采样间隔 ,使模型能够在不同序列长度下保持一致的总采样时间
每个序列之间的时间间隔一致,但是序列内部时间步是自适应的
具体,使用一个可学习的参数 ,它调节了不同长度序列的总采样时间 。每个输入 token 的采样间隔 计算如下:
基于自适应状态更新机制,该模型可以在不同序列长度下保持一致的总采样时间
空间一致性损失 为了进一步确保不同输入序列长度下更新的状态特征的一致性,我们在预训练任务中引入了空间状态一致性损失
这里使用教师模型的方法,略过,对简单的任务友好的效果。对 3 D 目标检测这个方法不太好
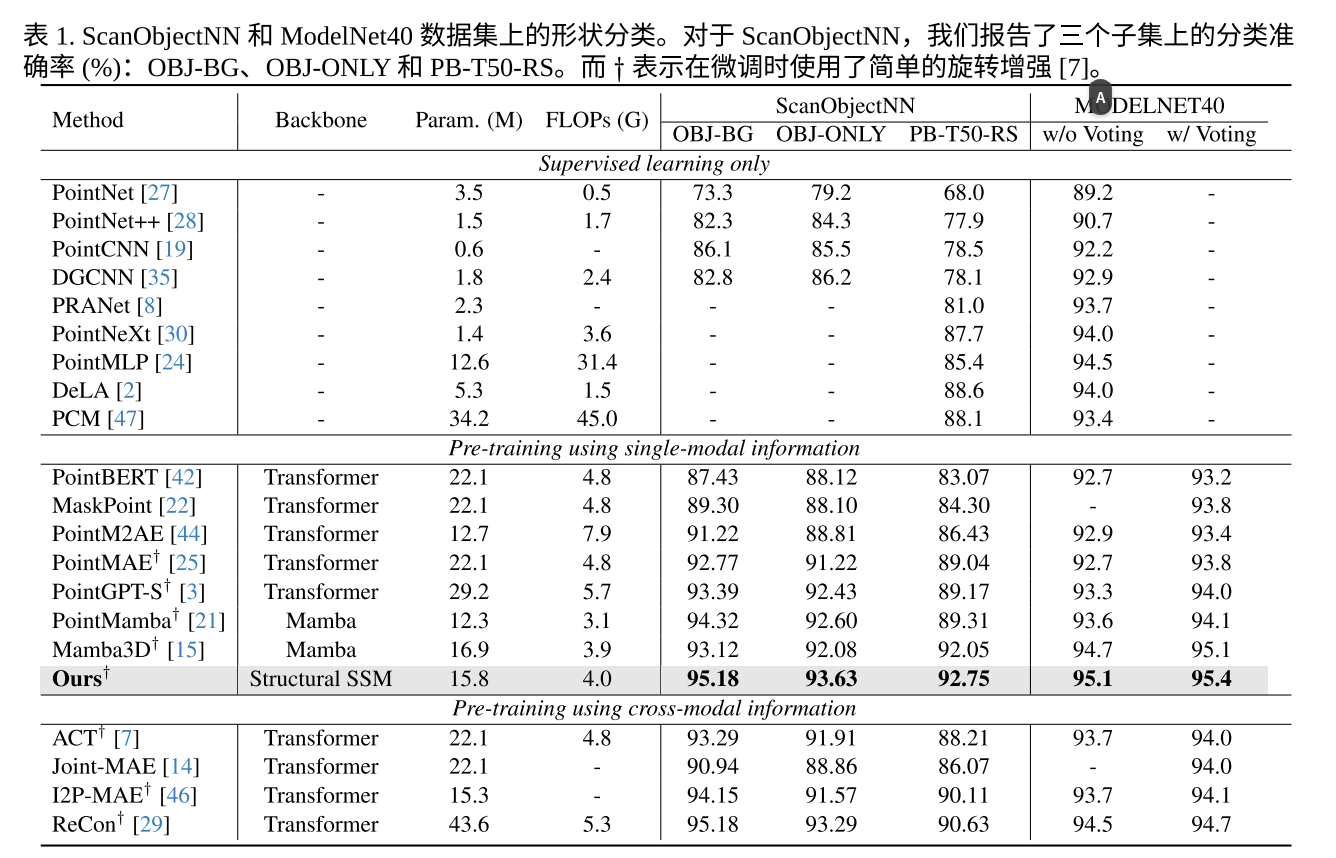
ScanObjectNN 和 ModelNet 40