Meta AI 研究院
简要介绍
把 DETR 思路扩展到点云,直接基于 set prediction,anchor-free。
适合研究 anchor-free + Transformer 在 3D 的纯粹表现。
是纯 Transformer 实现的
讨论问题
- VoteNet 和 DETR 之间的相似性
- P ointNet++核心机制与 Transformer 自注意力机制之间的相似性
以构建本文的端到端的基于 Transformer 的检测模型
3DETR
- 遵循DETR 和 VoteNet 通用的编码器-解码器结构;
- 编码器使用标准 Transformer 替代 PointNet++,并直接应用在点云数据;
- 解码器使用 DETR 并行解码策略,并在 Transformer 层使用两项重要修改适配 3 D 检测,即非参数化查询嵌入和傅里叶位置嵌入
3 DETR: 编码器-解码器 Transformer
- 采用 PointNet++的方式对原始点云采样(邻域采样)
- 通过 MLP 将点云转换为 特征维度
- 特征通过 Transformer 编码器
- 特征进入 Transformer 解码器,同时还有查询嵌入
- 查询嵌入从采样输入的点集中采样,通过位置编码和 MLP 转换为查询嵌入
- 解码器使用并行解码方案,输出多个边界框
编码器
下采样和集聚步骤(邻域采样)通过一个包含两层隐藏层(64,128)的MLP 生成一组 特征,维度为 256
随后特征被传递到 Transformer 中,生成一组特征,维度为 256。Transformer 使用标准自注意力机制,没有针对 3 D 数据进行修改,且忽略了位置嵌入
解码器
将检测视为一个集合预测问题,即同时预测一组无特征顺序的框。这一过程由 Transformer 组成的并行解码器实现。解码器将 点特征和一组 B 查询嵌入 作为输入,生成一组 B 特征,这特征随后被用来预测 3 D 边界框
其中,查询 表示 3 D 空间中的位置,最红的 3 D 边界框将围绕这些位置进行预测;在解码器中需要使用位置嵌入,因为它无法直接访问坐标(基于编码器特征和查询嵌入)
非参数化查询嵌入
受 VoteNet 和 BoxNet 种子点的启发,提出非参数化嵌入,从种子点的位置进行计算
从输入点中随机采样一组 B 查询点。采用最远点采样法进行采样,因为能够确保对原始点集的均匀覆盖
每个查询点会和每个插叙嵌入相关联,通过傅里叶位置嵌入,然后通过多层感知机进行投影
3 DETR-m
将归案偏置引入 3 DETR,为了保证模型灵活性,修改了编码器,以在 3 D 数据中包含归纳偏置,同时保持解码器损失函数不变
受 PointNet++启发的弱归纳偏置,即局部特征聚合比全局聚合更重要
通过在子注意力机制中应用掩码轻松实现。获得的模型 3 DETR-m 使用一个三层编码器,在第一层之后添加一个降采样操作(到 1024 个点)。每个编码器层在自注意力操作中应用一个 的二进制掩码。掩码中第 行表示 1024 个点中那些位于点 的 半径范围内。使用半径值为 。和 PointNet++相比,3 DETR-m 不依赖多层 3 D 特征聚合和 3 D 上采样
边界框参数化与预测
解码器生成一组 B 特征,特征被输出到预测 MLP 以预测边界框
一个三维边界框包含下列属性:
- 位置
- 尺寸
- 方向
- 类别
预测 MLP 在每个查询周围生成一个框坐标
- 位置:预测一个偏移 来预测位置 ,
- 尺寸:每个框都是一个 3 D 矩形,围绕其中心 c 来描述尺寸d
- 方向:遵循投票网络的方法,将 划分为 12 区间,并记录量化残差。角度预测包括量化的角度类别和残差,以获得连续角度a
- 类别:使用独热编码向量 s 对边界框中包含的类别进行编码;加入“背景”和“非对象类别”,因为部分预测框可能不包含任何对象
集合匹配和损失函数
为训练模型,需要将预测框和真实框进行匹配,使用二分图匹配,该方法更简单、通用。并且对非极大值抑制具有鲁棒性。之后通过匹配的真实框计算损失
二分图匹配
通过对几何项和语义项的定义,为一对边界框定义匹配代价
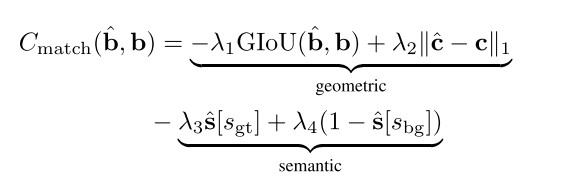
该代价衡量了几何代价和语义代价;集合代价使用 GIoU 和中心坐标偏差衡量;语义代价使用预测的分布下真实标签的可能性,以及框特征为前景类别的可能性,即不属于背景类别的可能性
通过每个真实框和预测框的代价,来给每个真实框分配对应的预测框,使用匈牙利算法计算预测框和真实框之间的最优二分匹配。由于预测框的数量多于真实框,未匹配的预测框被视为匹配到背景类。这鼓励模型不过度预测,这一特性有助于模型在非极大值抑制中保持鲁棒性
损失函数
对中心点和框尺寸使用 使用回归损失,并将他们均归一化到范围 以实现尺寸不变性。
对于角度残差,使用 Huber 回归算是,对角度分类和语义分类使用交叉熵损失
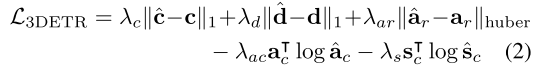
最终损失是上述五项加权组合
对于预测框匹配到“背景”类的情况,值即损和背景类真实标签的语义分类损失。
对于具有轴对齐 3 D 边界框的数据集,也直接使用基于 GIoU 的损失;不对定向 3 D 边界框使用 GIoU 损失,因为其计算复杂
中间解码器层
训练时,使用相同的边界框预测 MLP 层,来预测解码器每一层的边界框。独立计算每层的损失,并将所有损失加一训练模型。
测试时,只使用最后一个解码器层预测的边界框
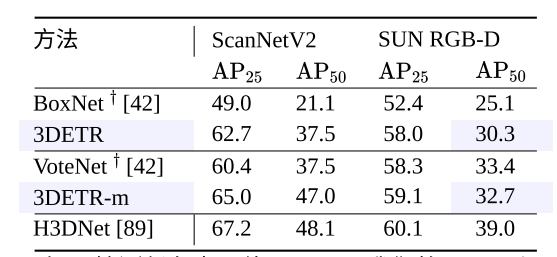
性能比较